一、RocketMQ实现原理
二、为什么要自己写NameServer而不用Zk呢?
1、NameServer是自己写的,方便扩展,去中心化,只要有一个NameServer在,整个注册中心环境就可以用
2、Zk选举需要满足过半机制才可以使用
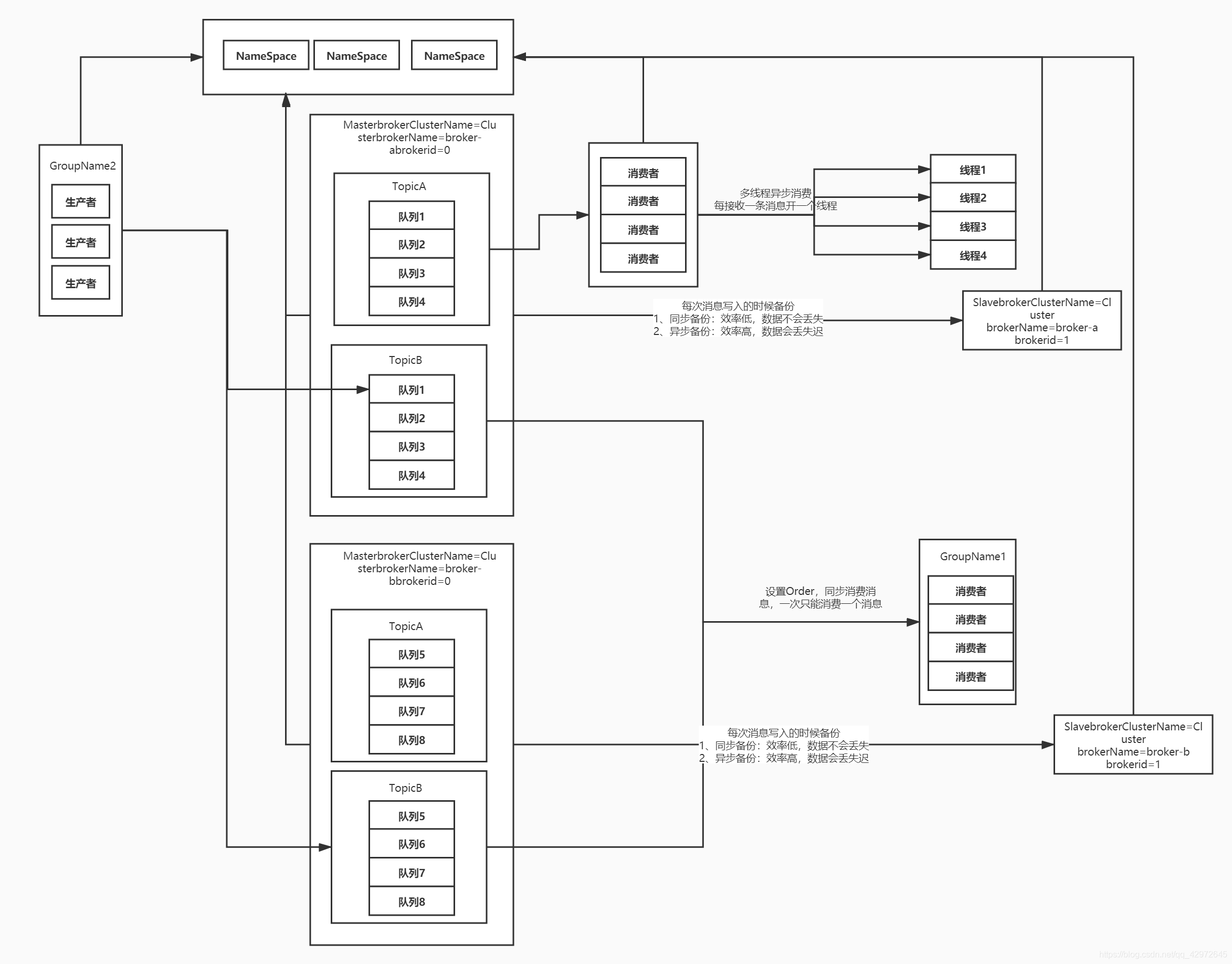
三、四种集群方式:
1、单个Master节点:负载压力非常大,如果宕机的话,数据可能会丢失
2、多个Master阶段:分摊存储数据,但是没有Slave节点的话,宕机的情况下数据可能会丢失
3、多Master和多Slave节点,同步形式实现主从数据同步,在生产者将消息存放到主再同步到备Broker中才返回ack确认消息投递成功
4、多Master和多Slave节点,异步形式实现主从数据同步,在生产者将消息存放到主,返回ack确认消息投递成功,异步同步到备Broker中,效率高,但是数据可能会丢失
四、在Broker扩容的时候会影响到其他的Broker使用吗?可以缩容吗?
不会,因为生产者是通过NameServer中注册的节点数通过轮询来实现数据的存放,节点数没有写死
可以缩容,但是前提是Broker中的消息要被消费完
五、RocketMQ与Kafka的区别
| RocketMQ | Kafka | |
|---|---|---|
| 注册中心 | Zookeeper | NameServer |
| Broker | 逻辑概念,一个Broker等于多个Master组合 | 物理概念,一个Broker就是一个 |
| 事务消息 | 支持 | |
| 顺序消息 | 支持 | 一台Brocker对应一个消费者实现顺序消息 |
六、单机版本中如何增加RocketMQ的吞吐量?
只需要增加队列和消费者
七、 Rocketmq解决分布式事务的核心思路
1.生产者向我们的Broker(MQ服务器端)发送我们派单消息设置为半消息,该消息不可以被消费者消费。
2.在执行我们的本地的事务,将本地执行事务结果提交或者回滚告诉Broker
3.Broker获取本地事务的结果如果是为提交的话,将该半消息设置为允许被消费者消费,如果本地事务执行失败的情况下,将该半消息直接从Broker中移除
4.如果我们的本地事务没有将结果及时通知给我们的Broker,这时候我们Broker会主动定时(默认60s)查询本地事务结果
5.本地事务结果实际上就是一个回调方法,根据自己业务场景封装本地事务结果
此时本地事务必须要用手动事务,用注解事务不好控制
八、RabbitMQ解决分布式事务问题存在的缺陷
RabbitMQ解决分布式事务问题,如果补单队列也挂的情况下,订单数据可能会丢失,但是能够成功派单,之后得手动补偿
九、解决分布式事务核心思想
1、最终一致性
2、保证第一个事务执行成功
十、分布式事务产生背景
rpc远程调用 多个不同服务之间通讯需要保证数据一致性的问题 存在多个数据源 每个数据源的事务都互不影响
十一、其他
RocketMQ单机版本,默认情况下一个Topic中分成四个队列,目的是为了高吞吐量
Broker中包含主题,主题中包含队列
Kafka有副本备份
kafka中是分区,一个broker有多个分区
rocketMQ中是队列,一个broker有多个队列
RocketMQ中队列的数量要和消费者数量一致
三种mq都是怎么实现顺序消息的?
都是怎么集群的?
lcn不再维护了,现在主要使用seata
RocketMQ经历过双11的考验
java语言编写的,懂源码容易扩展和维护
RocketMQ是对kafka的升级
9876是NameServer默认端口号
生产者必须分组,不然会报错
消费者如果在同一个组中,最终只会有一个消费者消费同一个消息
RocketMQ的特点
1、支持事务消息
2、支持顺序消息
3、消费者支持tag过滤,减少带宽传输
4、java语言编写,容易扩展和维护
5、RocketMQ经历过双11的考验
NameServer:类似eureka实现服务注册与发现,生产者、消费者、topic信息都统一存放在NameServer上。去中心化。实现动态感知,避免宕机修改地址
Broker:MQ服务器
Producer:生产者
Consumer:消费者
brokerid=0为master节点>0为slave节点
备变成主要手动改
