今天是猿灯塔“365天原创计划”第8天。
今天讲:

什么是重排序?
重排序是指编译器和处理器为了优化程序性能对指令序列进行重新排序的一种手段。Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序可以保证最终执行的结果是与程序顺序执行的结果一致,并且只会对不存在数据依赖性的指令进行重排序,这个重排序在单线程下对最终执行结果是没有影响的,但是在多线程下就会存在问题。
int a = 1;(1)
int b = 2;(2)
int c= a + b;(3)
如上c的值依赖a和b的值,所以重排序后能够保证(3)的操作在(2)(1)之后,但是(1)(2)谁先执行就不一定 了,这在单线程下不会存在问题,因为并不影响最终结果。
class RecorderExample{
int a = 0;
boolean flag = false;
public void write(){
a = 1; // 1
flag = true; // 2
}
public void read(){
if(!flag){ // 3
a = 2; // 4
}
}
}
有两个线程,线程A首先执行write()方法,线程B首先执行read()方法。
JMM中可能的执行时序为:

而编译器可以对操作1和操作2进行重排序
得到的执行时序为:
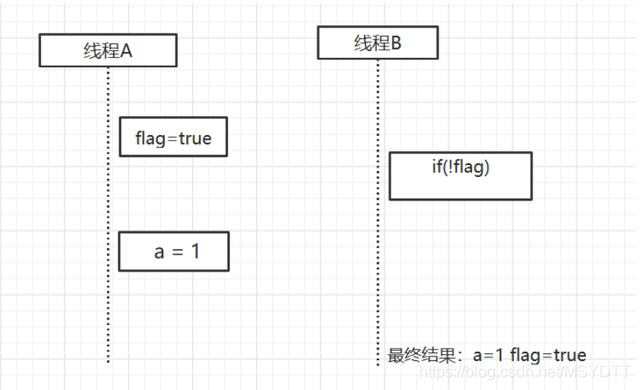
一个多线程的例子:
public class TestCP {
private static int num =0;
private static boolean ready = false;
public static class ReadThread extends Thread {
public void run() {
while(!Thread.currentThread().isInterrupted()){
if(ready){//(1)
System.out.println(num+num);//(2)如代码由于(1)(2)(3)(4) 之间不存在依赖,所以写线程(3)(4)可能被重排序为先执行(4)在执行(3),那么
执行(4)后,读线程可能已经执行了(1)操作,并且在(3)执行前开始执行(2)操作,这时候打印
结果为0而不是4.
改变程序执行结果的直接原因是重排序,而根本原因是未正确同步。
如果程序是正确同步的,程序的执行将具有顺序一致性。即:正确同步程序的执行结果与顺序一致性内存模型的执行结果相同。
注意:这里的同步是广义的同步,包括同步原语(synchronized,volatile,fifinal)的正确使用。
从源代码到最终实际执行的指令序列,会分别经历以下三中排序
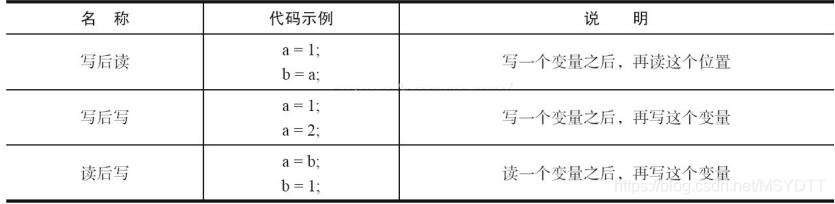
2、数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖
性。数据依赖分为下列3种类型,如下图所示
}
System.out.println("read thread....");
}
}
}
public static class Writethread extends Thread {
public void run() {
num = 2;//(3)
ready = true;//(4)
System.out.println("writeThread set over...");
}
}
public static void main(String[] args) throws InterruptedException {
ReadThread rt = new ReadThread();
rt.start();
Writethread wt = new Writethread();
wt.start();
Thread.sleep(10);
rt.interrupt();
System.out.println("main exit");
}
}
如代码由于(1)(2)(3)(4)之间不存在依赖,所以写线程(3)(4)可能被重排序为先执行(4)在执行(3)那么执行(4)后,读线程可能已经执行了(1)操作,并且在(3)执行前开始执行(2)操作,这时候打印结果为0而不是4。
改变程序执行结果的直接原因是重排序,而根本原因是未正确同步。
如果程序是正确同步的,程序的执行将具有顺序一致性。即:正确同步程序的执行结果与顺序一致性内存模型的执行结果相同,注意:这里的同步是广义的同步,包括同步原语(synchronized,volatile,fifinal)的正确使用,从源代码到最终实际执行的指令序列,会分别经历以下三中排。
数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。
数据依赖分为下列3种类型如下图所示:
上面3种情况,只要重排序两个操作的执行顺序,程序的执行结果就会被改变。前面提到过编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
365天干货不断,可以微信搜索「 猿灯塔」第一时间阅读,回复【资料】【面试】【简历】有我准备的一线大厂面试资料和简历模板
