一. redis 持久化机制
防止redis服务器发生异常,接收数据丢失,提供了持久化机制,分为AOF全量数据持久化与RDB指定时间内触发存储操作数据指令的增量持久化
AOF 持久化
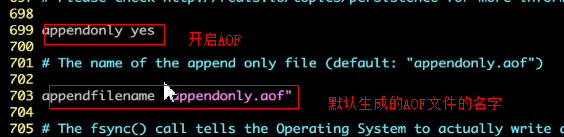
记录指定时间内触发的操作数据的指令,将这些指令存储到一个AOF文件中,默认是关闭的,通过在redis.conf文件中配置"appendony yes" 开启


RDB 持久化
通过 redis.conf文件中配置RDB持久化策略,记录指定时间内触发的操作redis数据的指令
RDB持久化原理: 当使用SAVE命令,先阻塞redis的服务进程,创建rdb文件完毕后(不推荐使用),采用BGSAVE命令: Fork出一个子线程处理创建Rdb文件,不会阻塞服务器进程
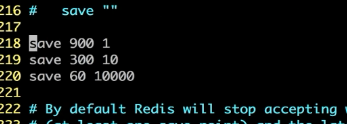
举例:
Save 900 1 :如果900秒之内发生了一次写入的操作,就触发产生一次快照备份数据
Save 300 10: 如果在300秒内有10条信息写入,就触发产生一次快照,如果未到10,就等到9秒
Save 60 10000: 如果在60秒内有10000条数据写入,就产生快照,不然等300秒—9000秒
为了保护数据的一致性,当用户触发备份数据发生错误时,停止redis的写入操作(如果业务中有更完善的配置可以关闭,否则请开启)
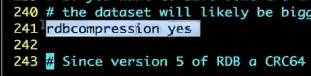
将rdb压缩后再去做保存(建议设置为no,redis是密集型操作,如果进行压缩会造成cpu资源浪费)
查看redb文件,在redis文件夹下有src文件夹,在rec文件夹下有dump.rdb文件,进入src文件夹下打开dump.rdb,如果使用rdb方式进行持久化,redis会定期将全量数据保存,生成在dump.rdb文件中(二进制)
RDB与AOF的区别,持久化的执行
默认情况下redis启动时首先会查查找AOF文件,如果没有则去查找RDB文件,如果有则忽略RDB文件,通过加载获取文件中的数据,进行恢复数据

考虑到RDB与AOF不同方式持久化的优缺点,采用RDB+AOF混合持久化,由于RDB的BGSAVE会耗费较长时间,在停止恢复时,可能会出现大量数据丢失,与AOF配合使用,在redis重启时会使用RDB的BGSAVE持久化文件重新构建内容,AOF重持久化增加内容先以RDB方式写入全量数据,在以AOF追加增量数据,提高重写和恢复速度,减少文件大小,也可以保证数据的完整性
子线程在做AOF重写时会通过管道在父线程读取增加数据并缓存下来.在以RDB方式在管道中读取全量数据,不会造成管道阻塞(也就是说AOF前面的数据是RDB的全量数据,后面的是redis命名格式的增量数据)
二. 缓存击穿与缓存穿透
缓存击穿也就是缓存雪崩,redis中存储的数据失效,造成对该数据的访问直接打到数据库上,高并发下对数据库造成压力问题
缓存穿透就是请求一个不存在的数据,第一次请求到达数据库查询为null,不做任何操作,后续请求还是打到数据库上
总结上就是请求一个redis中不存在的数据,多个请求直接访问数据库
解决方案
- 对数据进行分级缓存,合理设置失效时间,例如一个数据存储两份不同的失效时间,例如增加Ehcache二级缓存等
- 利用消息中间件顺序性消费,流量削峰的特性,当请求redis中不存在的数据时,将这个请求通过消息中间件去查询,消息中间件中首次还是查询redis,如果redis没有再去查询数据库
- 对redis中不存在的数据进行加锁,限流,保证当前只有指定请求到达数据库
不考虑增加限流削峰的情况下,解决恶意请求数据库,redis同时不存在的数据问题: 使用BloomFilter,可以简单理解为存储所有数据的key,后续的查询中首先查询这个key是否存在,如果不存在,直接返回
