1. 内存分配方式,池化和非池化
可以通过下面代码实现内存分配是采用pooled还是unpooled方式,pooled可以增加对内存的使用反复使用
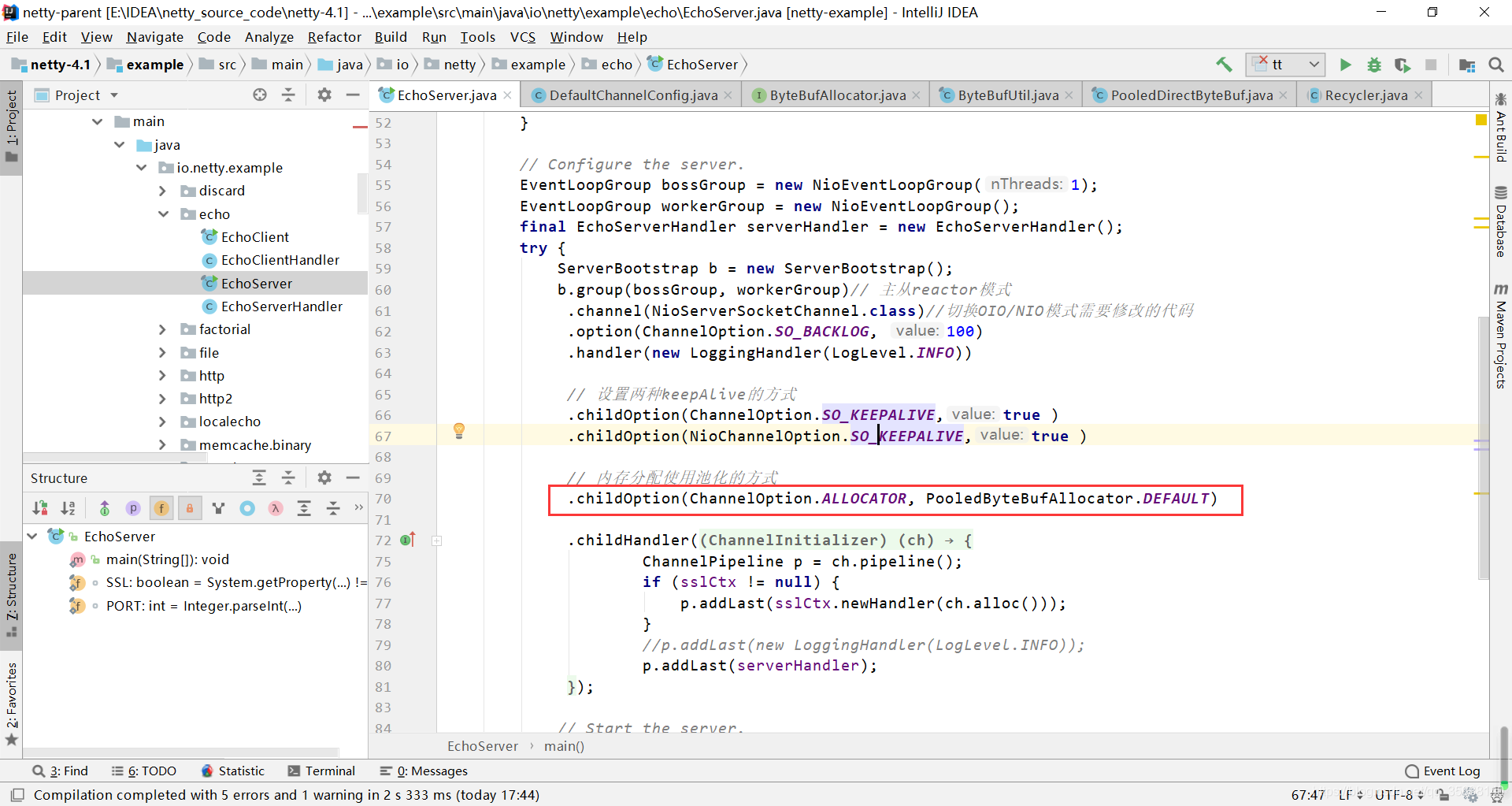
下面试netty默认的内存分配方式
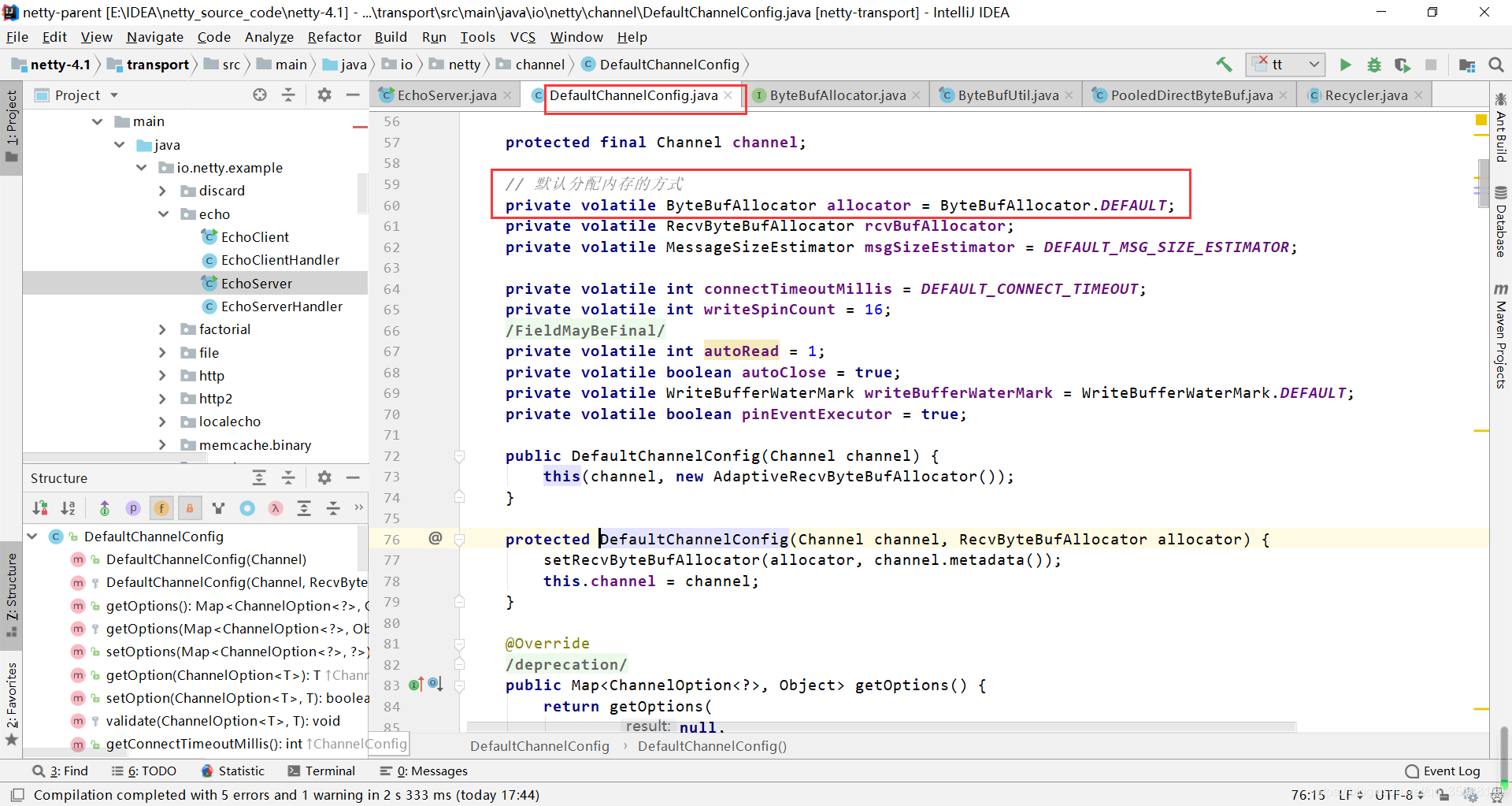
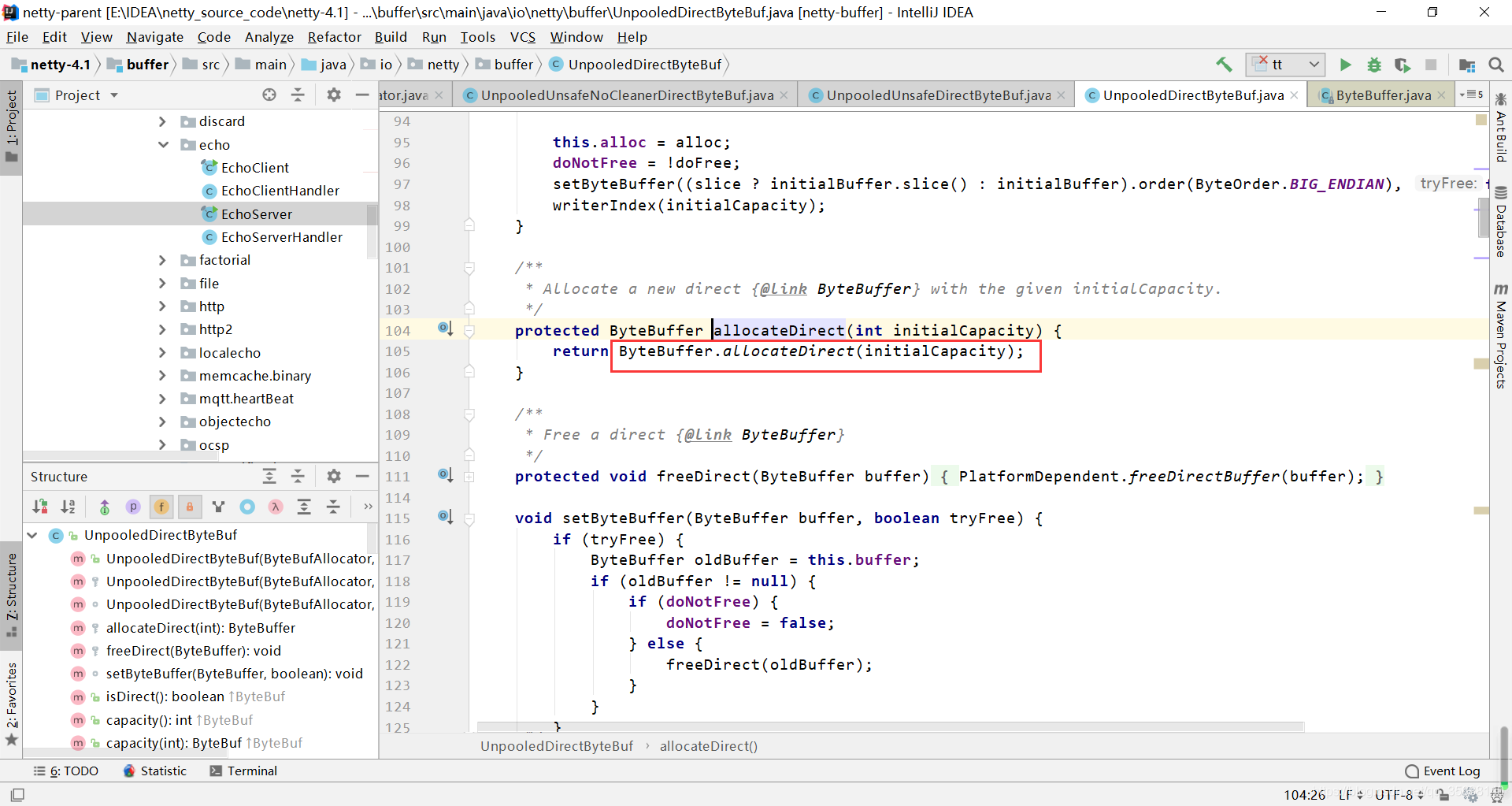
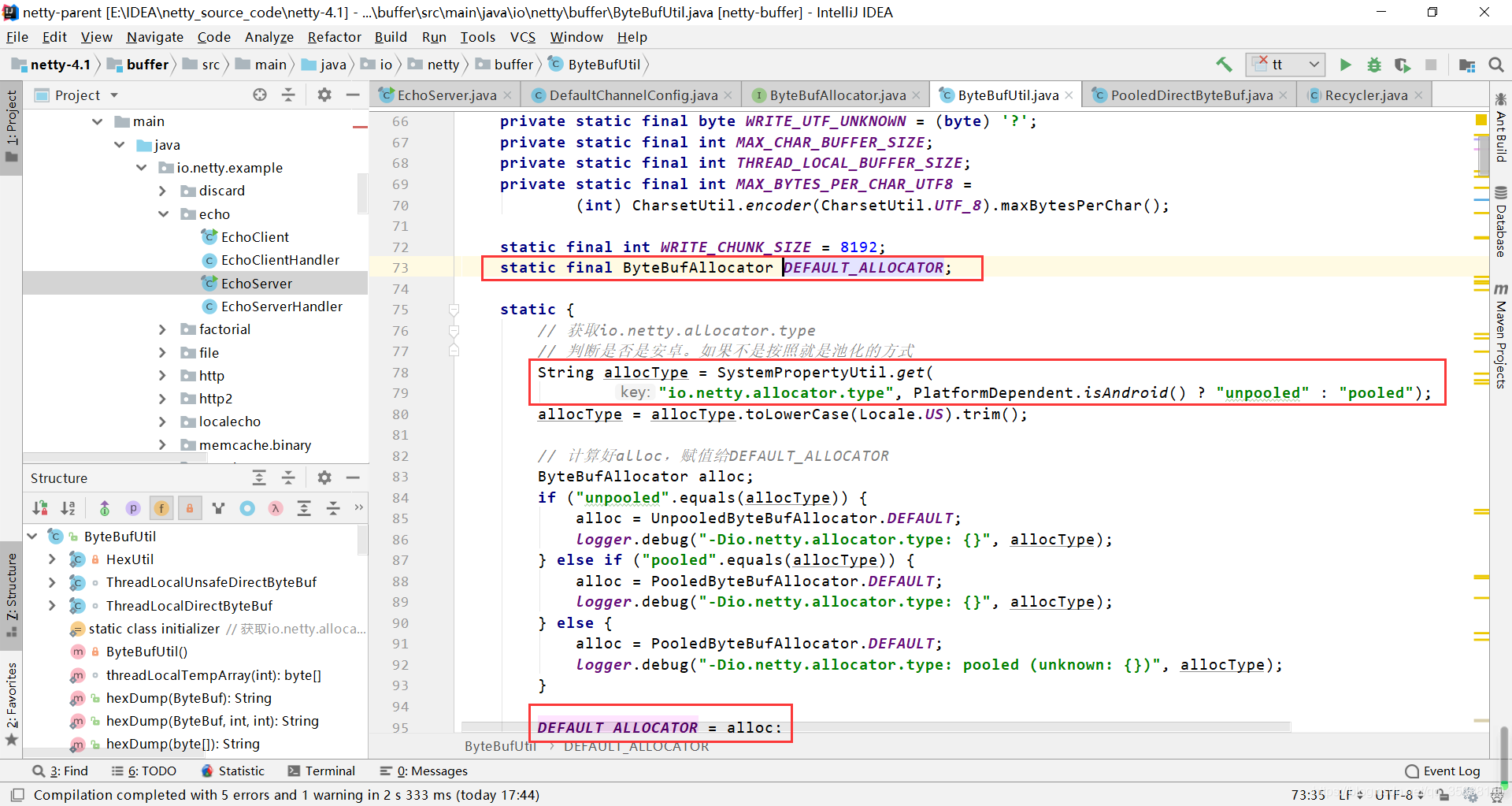
不断跟进ByteBufAllocator.DEFAULT里面的代码,发现如下代码,可以看出内存的分配默认还是pooled的方式
1.1 PooledDirectByteBuf对象池的使用
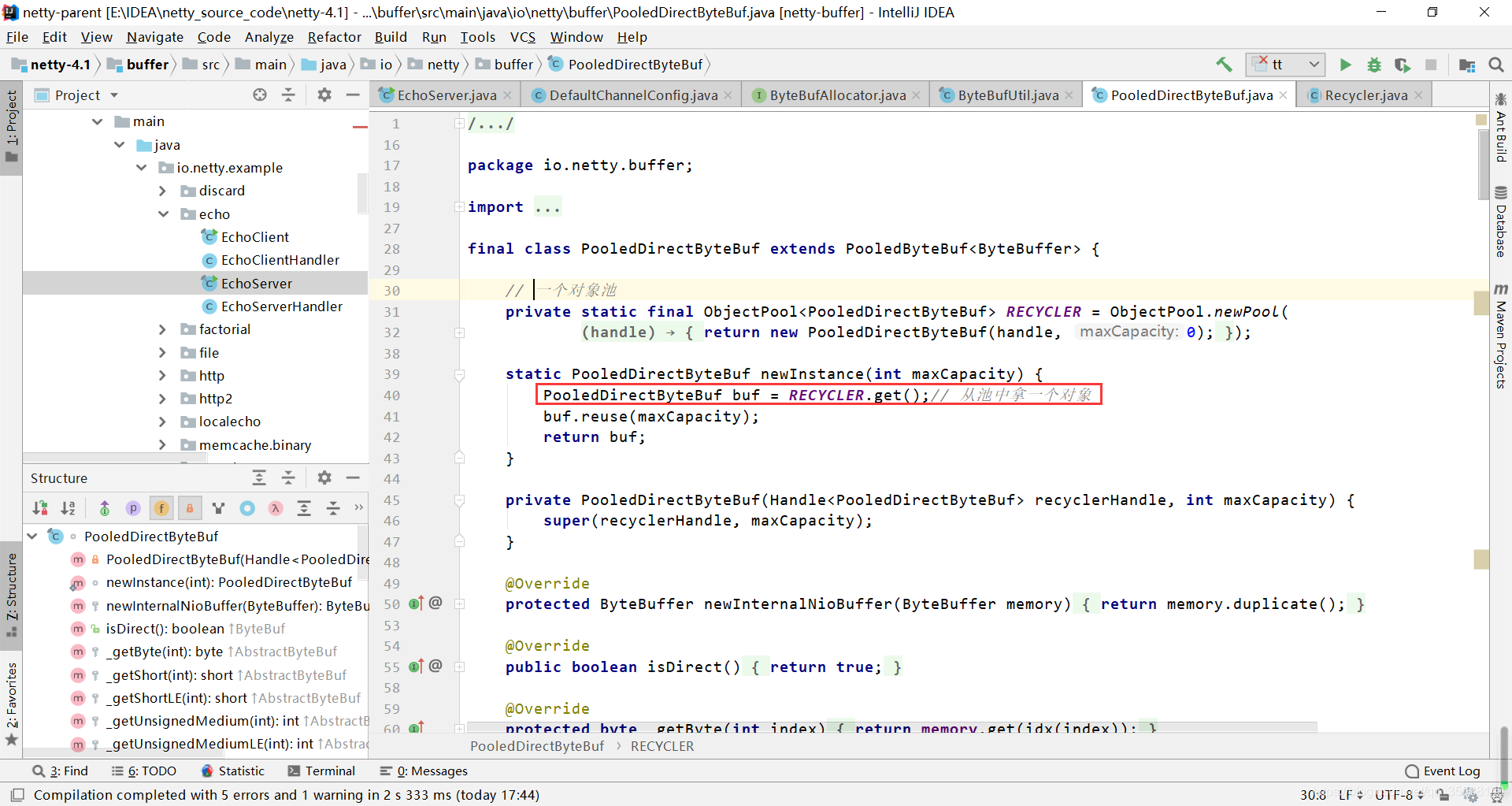
跟进RECYCLER.get()源码
@SuppressWarnings("unchecked")
public final T get() {
// 判断线程池的容量等于0则直接返回一个Object
if (maxCapacityPerThread == 0) {
return newObject((Handle<T>) NOOP_HANDLE);
}
// fastThreadLocal中获取一个stack
Stack<T> stack = threadLocal.get();
DefaultHandle<T> handle = stack.pop();
// 试图从"池"中取一个handle,如果没有成功就new一个handle
if (handle == null) {
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
}
在类中方法内回收对象的实现
private static final class DefaultHandle<T> implements Handle<T> {
int lastRecycledId;
int recycleId;
boolean hasBeenRecycled;
Stack<?> stack;
Object value;
DefaultHandle(Stack<?> stack) {
this.stack = stack;
}
// 默认的回收对象的实现方式
@Override
public void recycle(Object object) {
if (object != value) {
throw new IllegalArgumentException("object does not belong to handle");
}
Stack<?> stack = this.stack;
if (lastRecycledId != recycleId || stack == null) {
throw new IllegalStateException("recycled already");
}
stack.push(this);// 将对象再放入栈中
}
}
1.2 关于回收池Recycler原理
参考了:https://kkewwei.github.io/elasticsearch_learning/2019/01/16/Netty对象回收池Recycler原理详解/
对象池通过Recycler里面WeakOrderQueue、Stack 2个类来实现。 首先放一张图来展示一个stack中两者的关系:
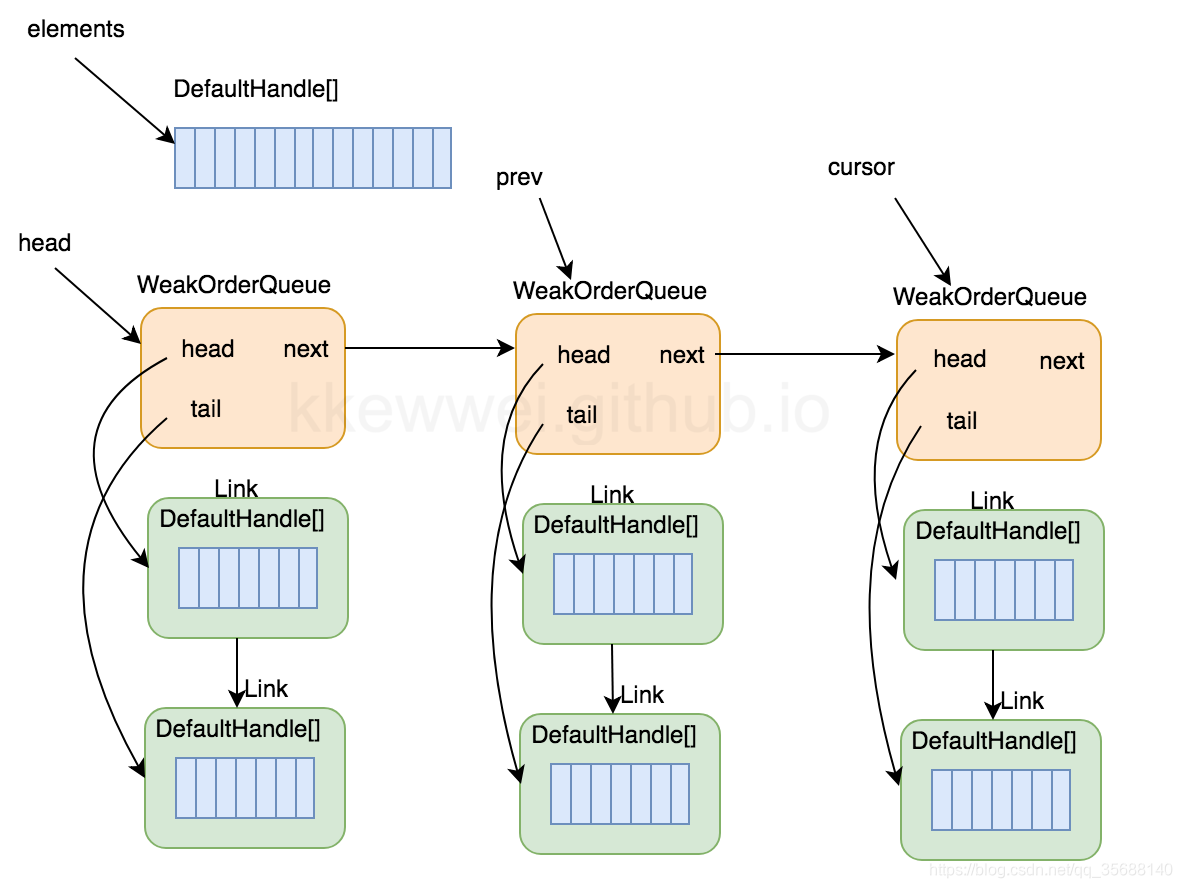
- 每个线程都拥有自己的对象池, 该对象池结构如上图所示, stack作为本线程对象池的核心, 通过FastThreadLocal来实现每个线程的本地化。
- 本线程回收本线程产生的对象时, 会将对象以DefaultHandle的形式存放在stack的elements数组中; 若本线程thread1回收其它线程thread2产生的对象时, 将该对象放到thread2对应stack的一个WeakOrderQueue的Link中。 也就是说一个WeakOrderQueue节点存放着一个其他线程帮着本线程回收本线程生产的对象。每个stack的WeakOrderQueue链表节点个数不能超过2cpu, 可以通过io.netty.recycler.maxDelayedQueuesPerThread控制。 也就是说最多有2cpu个线程帮着回收对象。
- 每个link存放的对象是有限的, Link中DefaultHandle[]最多存放16个对象。 若thread1回收thread2产生的对象装满了一个Link, 则会再产生一个link继续存放。
- 当前线程从对象池中拿对象时, 首先从stack的elements中获取, 若没有的话, 将尝试从当前WeakOrderQueue节点cursor的Link中的数组对象transfer到stack的elements, 再从stack的elements中获取对象。
- stack的element数组最大长度32768, 可以通过io.netty.recycler.maxCapacityPerThread控制; 而Link节点中每个DefaultHandle数组默认长度16, 可以通过io.netty.recycler.linkCapacity控制;
- 通过elements及Link完成了整个对象池的构建。
- Netty回收对象也不是把所有对象全部回收, 为了防止回收对象过多, 会在直接存入stack的elements和从Link转移到stack的elements时会丢弃7/8的废弃对象。
2.内存分配方式,堆内和堆外内存
跟进源码
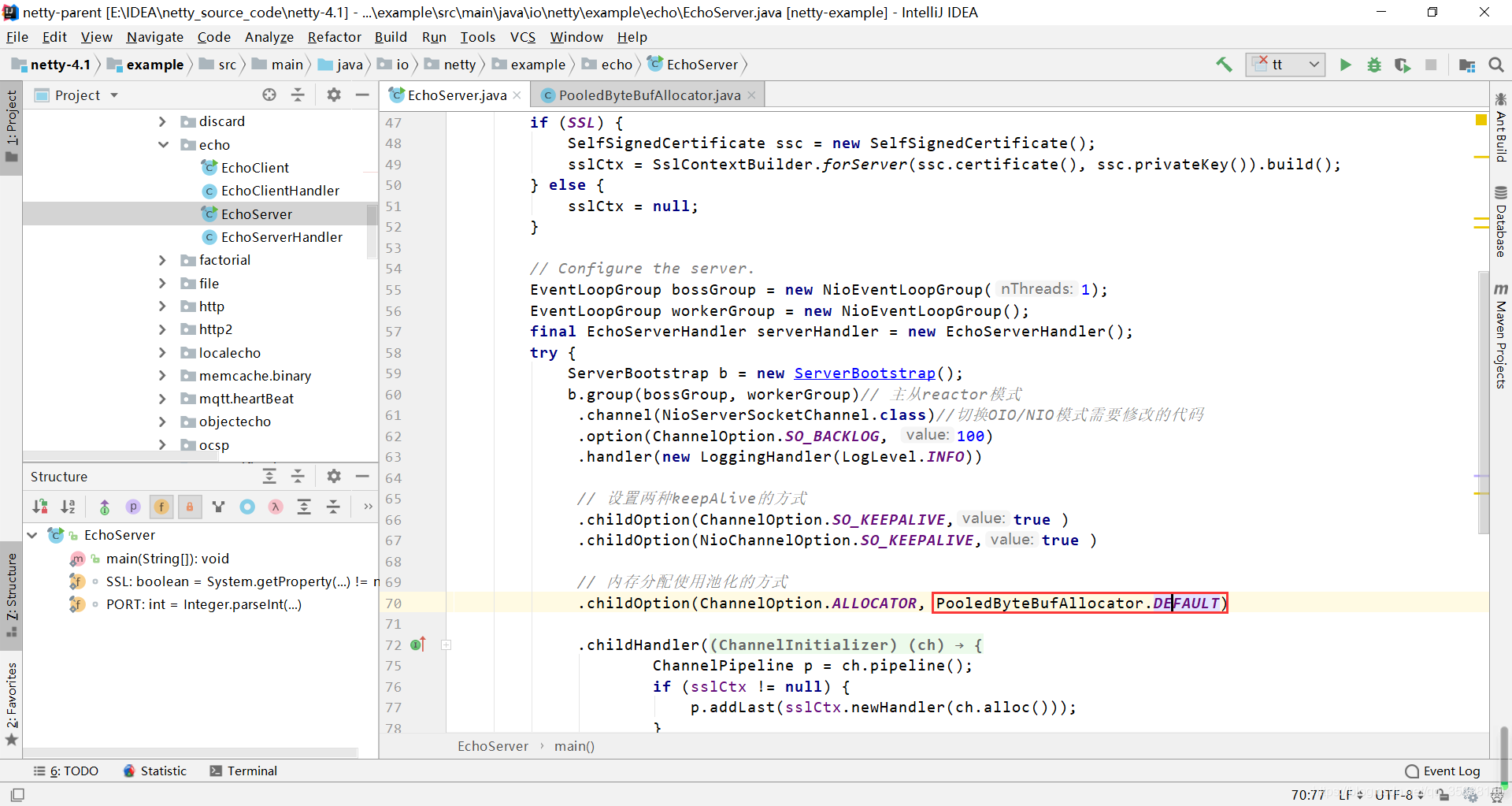
可以看出默认是堆外缓冲区
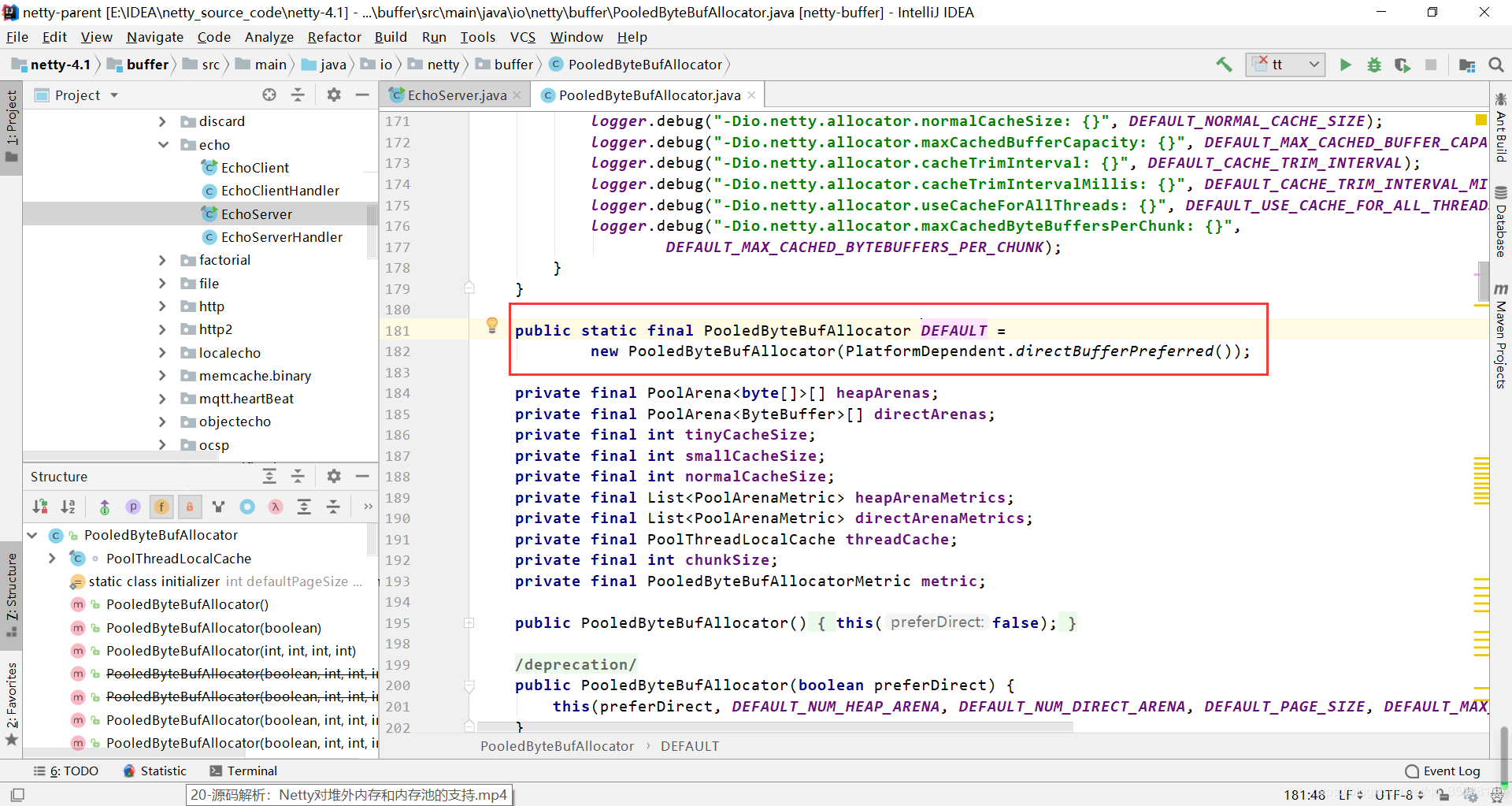
不断跟进源码,发现
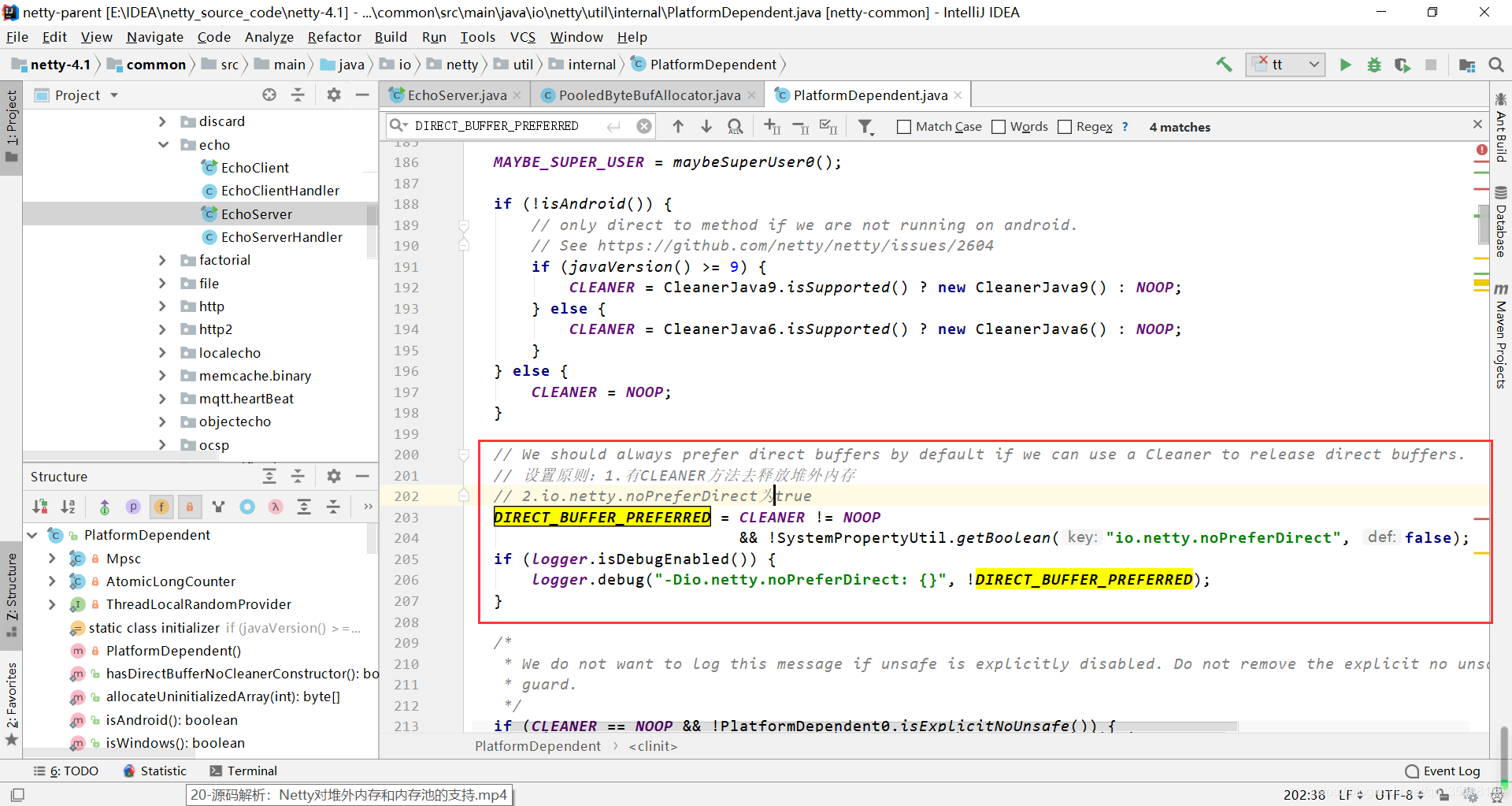
2.1 PooledByteBufAllocator如何实现堆外内存分配
进入PooledByteBufAllocator的构造函数
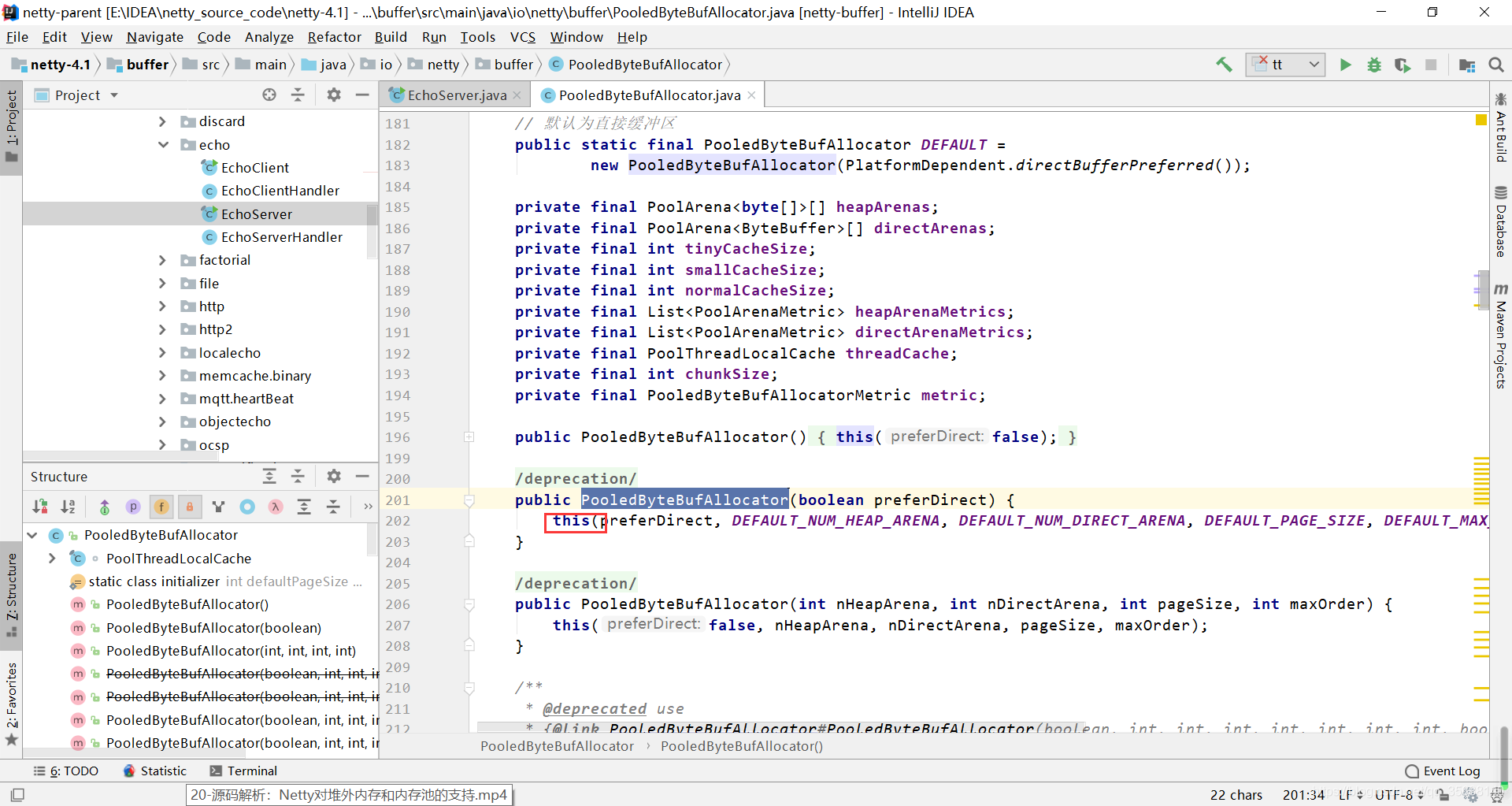
不断的跟进源码
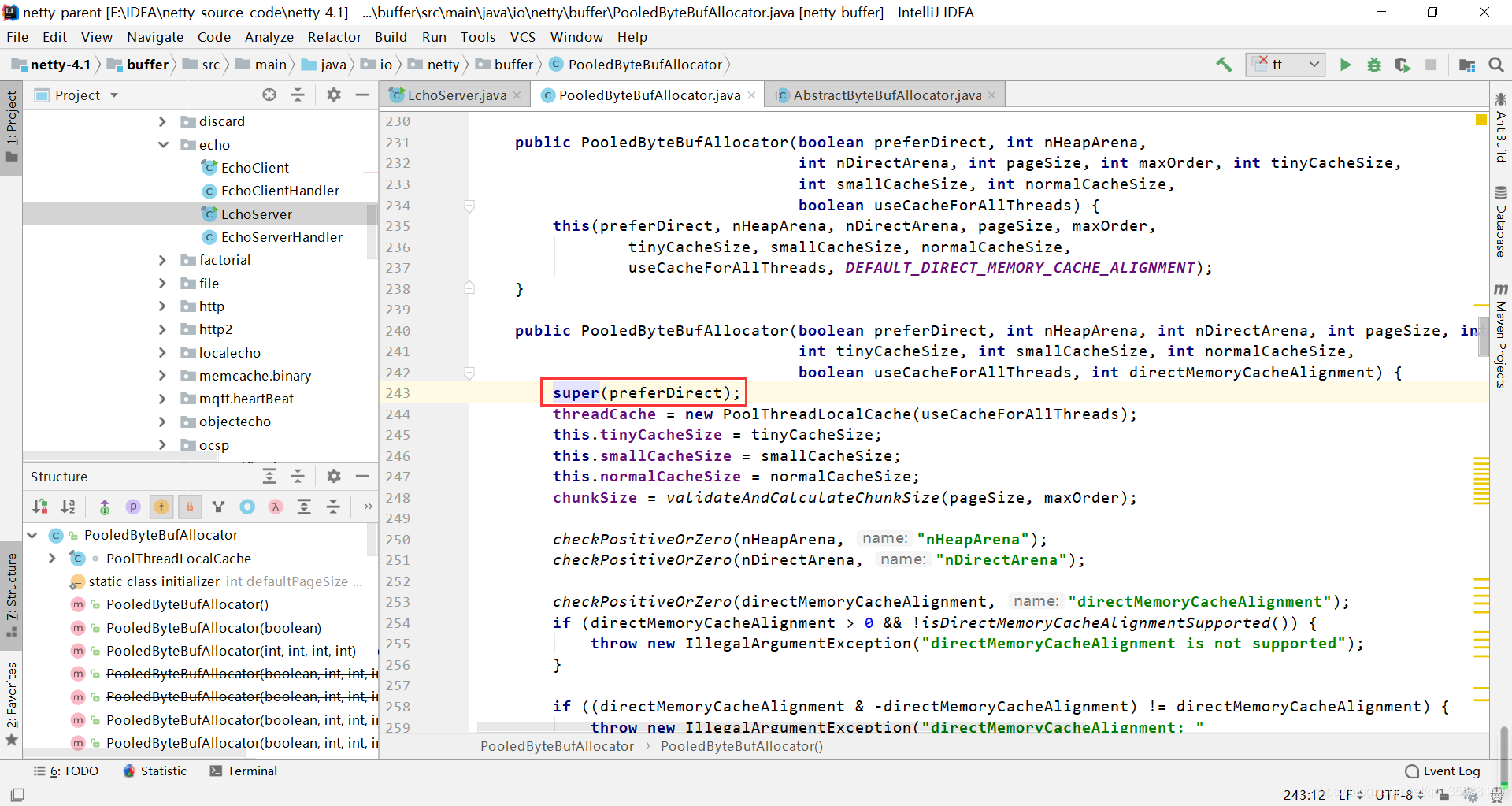
继续跟进源码,传入的preferDirect最后作用于directByDefault,然后当directByDefault为true的时候,115行的代码会分配一个堆外内存
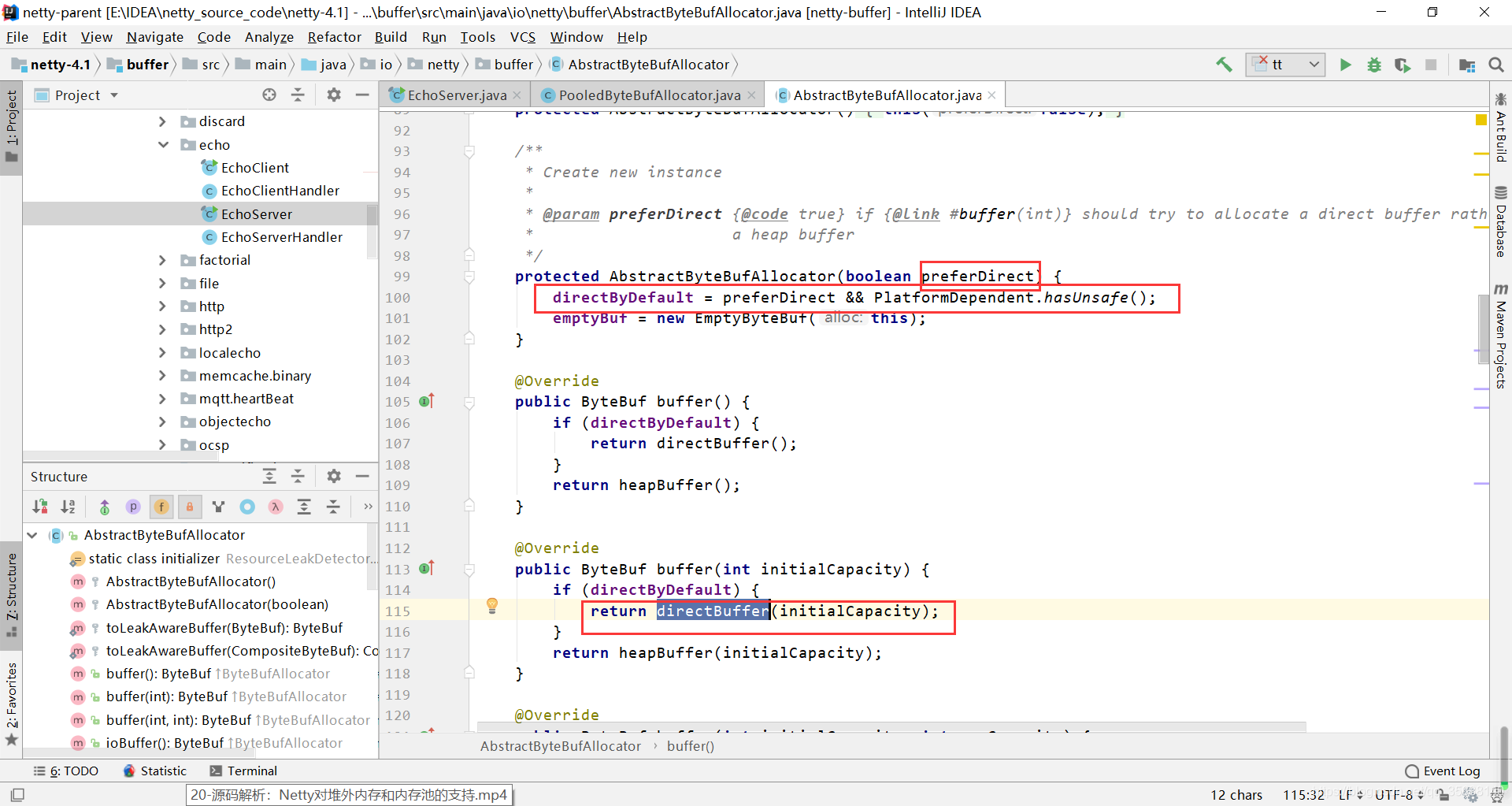
不断跟进源码
进入newDirectBuffer的一个实现类中,选用了UnpooledByteBufAllocator的newDirectBuffer方法,因为大多数情况下平台都支持unsafe和clear操作,所以进入InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf()方法的源码
跟进源码
最后发现直接调用了jdk的堆外内存分配的方法。