1.技术层面
1.高访问压力隔离
将秒杀系统独立部署,甚至使用独立域名,使其与网站完全隔离。
2.用户在秒杀开始前,通过不停刷新浏览器页面以保证不会错过秒杀.但是持续刷新商品页面详情页会对服务器造成压力
重新设计秒杀商品页面,不使用网站原来的商品详细页面,页面内容静态化(静态在CDN或客户端),用户请求不需要经过应用服务。而是静态页面,秒杀按钮在秒杀开始前无法点击。
3.突然增加的网络带宽:主要是很多商品的静态图片如果从某一个服务器去加载,网页必然在秒杀开始的那一刻崩溃。
秒杀商品页面缓存在CDN
4.如果下单的url可以直接通过html源码获取,那么就会有部分用户绕过网页前端直接在秒杀开始前下单。
隐藏下单的url,流程变为了:点击下单->获取秒杀url->通过url下单
在获取url层加入验证,判断是否有在下单时间内,如果可以下单就生成随机数,在url下单时就可以通过随机数判断了。
为了增大qps,获取秒杀url的时候可以单独隔离为其他服务,结果写入redis(前缀+userId+goodsId,随机数)即可。
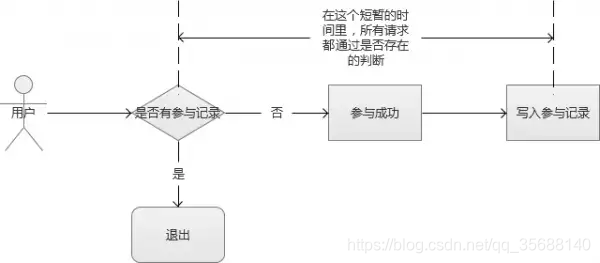
5.如何只允许第一个提交的订单被发送到订单子系统
由于最终能够成功秒杀到商品的用户只有一个,因此需要在用户提交订单时,检查是否已经有订单提交。
如果已经有订单提交成功,则需要更新 JavaScript文件的请求秒杀url为空,更新秒杀开始标志为否,购买按钮变灰。
6.限流
在获取秒杀url这一层可以做限流操作,比如使用guava做令牌桶算法等等。某一个多次点击秒杀按钮,会生成验证码来限流。
7.减库存的时机
有两种选择,一种是拍下减库存 另外一种是付款减库存;目前采用的“拍下减库存”的方式,拍下就是一瞬间的事,对用户体验会好些。
8.库存会带来“超卖”的问题
redis分布式乐观锁,如果并发量不算极大也可以考虑zookeeper分布式锁
2.设计原则
1.尽量将请求拦截在系统上游
传统秒杀系统之所以挂,请求都压倒了后端数据层,数据读写锁冲突严重,并发高响应慢,几乎所有请求都超时,流量虽大,下单成功的有效流量甚小
2.读多写少的常用多使用缓存
这是一个典型的读多写少的应用场景【一趟火车其实只有2000张票,200w个人来买,最多2000个人下单成功,其他人都是查询库存,写比例只有0.1%,读比例占99.9%】,非常适合使用缓存。
3.架构
在秒杀开始的时候抢先进入下单页面,而不是商品详情等用户体验细节,因此秒杀系统的页面设计应尽可能简单。
下单表单也尽可能简单,购买数量只能是一个且不可以修改,送货地址和付款方式都使用用户默认设置,没有默认也可以不填,允许等订单提交后修改
1.前端页面
加上其他的css, js,图片等资源,如果同时有几千万人参与一个商品的抢购,一般机房带宽也就只有1G10G,所以必须前端页面CDN。
2.出于性能原因这个一般由js调用客户端本地时间,就有可能出现客户端时钟与服务器时钟不一致,另外服务器之间也是有可能出现时钟不一致。
客户端与服务器时钟不一致可以采用客户端定时和服务器同步时间。
这里考虑一下性能问题,用于同步时间的接口由于不涉及到后端逻辑,只需要将当前web服务器的时间发送给客户端就可以了,因此速度很快。
并且web服务器群是可以很容易的横向扩展的(LB+DNS轮询),这个接口可以只返回一小段json格式的数据
而且可以优化一下减少不必要cookie和其他http头的信息,所以数据量不会很大。
JS层面,限制用户在x秒之内只能提交一次请求;
3.站点设计
前端层的请求拦截,只能拦住小白用户(不过这是99%的用户哟),高端的程序员根本不吃这一套,写个for循环,直接调用你后端的http请求,怎么整?
同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面(redis页面静态化)
同一个item的查询,例如手机车次,做页面缓存,x秒内到达站点层的请求,均返回同一页面(redis页面静态化)
如此限流,又有99%的流量会被拦截在站点层。
4.服务层设计
站点层的请求拦截,只能拦住普通程序员,高级黑客,假设他控制了10w台肉鸡(并且假设买票不需要实名认证),这下uid的限制不行了吧?怎么整?
大哥,我是服务层,我清楚的知道小米只有1万部手机,我清楚的知道一列火车只有2000张车票,我透10w个请求去数据库有什么意义呢?
访问数据库的过程:秒杀开始->redis->进入消息对列->mysql
对于写请求,做请求队列,每次只透过有限的写请求去数据层,如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完”(无需再次访问数据库);
对于读请求,还用说么?cache来抗,不管是memcached还是redis,单机抗个每秒10w应该都是没什么问题的;
如此限流,只有非常少的写请求,和非常少的读缓存mis的请求会透到数据层去,又有99.9%的请求被拦住了。
5.请求分发
用户请求分发模块:使用Nginx或Apache将用户的请求分发到不同的机器上
用户请求预处理模块:判断商品是不是还有剩余来决定是不是要处理该请求。
用户请求处理模块:把通过预处理的请求封装成事务提交给数据库,并返回是否成功。
数据库接口模块:该模块是数据库的唯一接口,负责与数据库交互,提供RPC接口供查询是否秒杀结束、剩余数量等信息。
4.数据库设计
1.数据库分片

分片解决的是“数据量太大”的问题,也就是通常说的“水平切分”。
一旦引入分片,势必有“数据路由”的概念,哪个数据访问哪个库。
hash分库:
优点:简单,数据均衡,负载均匀
缺点:迁移麻烦(2库扩3库数据要迁移)
ps:此时不能使用id自增的模式
两个写库使用不同的初始值,相同的步长来增加id:1写库的id为0,2,4,6…;2写库的id为1,3,5,7…;
不使用数据的id,业务层自己生成唯一的id(雪花算法),保证数据不冲突;
2.分组
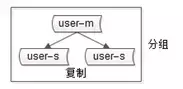
也就是组从分离模式,一主多从实现读写分离
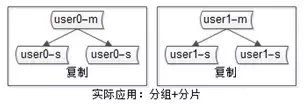
实际互联网公司都是:分片又分组
3.高可用
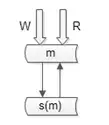
仍是双主,但只有一个主提供服务(读+写),另一个主是“shadow-master”,只用来保证高可用,平时不提供服务。
4.读性能
添加索引,主库不加索引,从库加索引
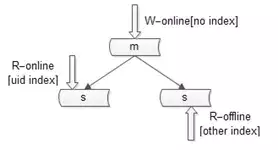
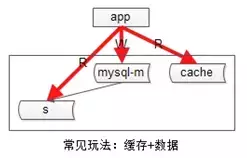
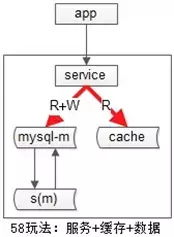
常见的是下面两种缓存增加读性能的结构:
5.数据一致性
**主从一致性:**常用中间件同步主从库,某一个操作会被发送给所有db。
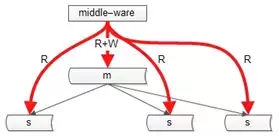
cache和数据库的一致性的问题
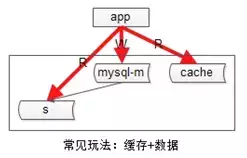
常见的缓存架构如上,此时写操作的顺序是:
(1)淘汰cache;
(2)写数据库;
读操作的顺序是:
(1)读cache,如果cache hit则返回;
(2)如果cache miss,则读从库;
(3)读从库后,将数据放回cache;
在一些异常时序情况下,有可能从【从库读到旧数据(同步还没有完成),旧数据入cache后】,数据会长期不一致。解决办法是“缓存双淘汰”,写操作时序升级为:
(1)淘汰cache;
(2)写数据库;
(3)在经过“主从同步延时窗口时间”后,再次发起一个异步淘汰cache的请求;
这样,即使有脏数据如cache,一个小的时间窗口之后,脏数据还是会被淘汰。带来的代价是,多引入一次读miss(成本可以忽略)。
除此之外,最佳实践之一是:建议为所有cache中的item设置一个超时时间。
数据库扩容保证高效扩容:数据库节点加倍(解决hash扩容的缺点)
原始结构:两个master,一个作为另一个的备份,原来只有模0和模1的区别。
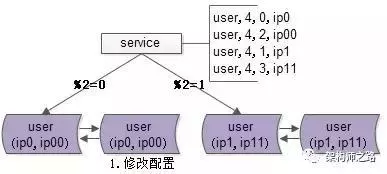
开始扩容:现在变成了模0到模3,并且原来的备用的master生效开始工作,承担四分之一的工作。
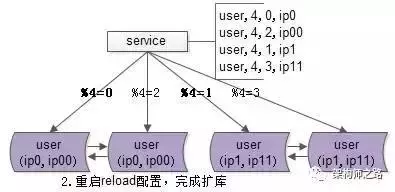
最后给四个master分配一个“备用master”。
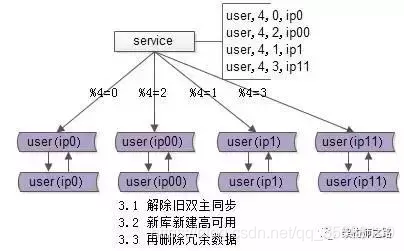
5.一些总结
万一负载过大,可以选择拒绝请求来保护服务的可用性
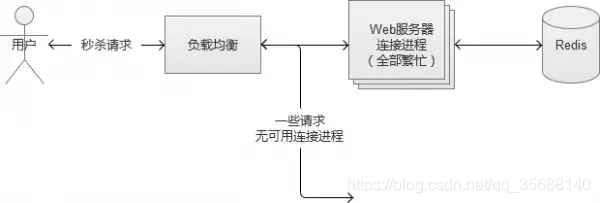
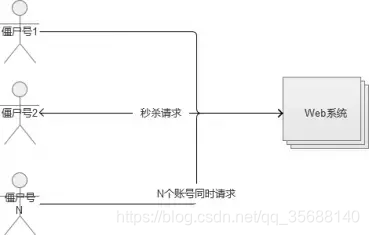
多次重复的用户请求生效一次
万一流量多大以可使用验证码来削峰
超发和超卖问题可以使用redis和zookeeper的分布式锁解决:
友情链接https://blog.csdn.net/qq_35688140/article/details/100983288
