秒杀超卖现象:在高并发下,多个线程并发更新库存,导致库存为负的情况。
我搜集了一些资料,整理了一下,秒杀可选方案主要有以下三种:
1.超卖原因
一个简单的订单表
create table orders (
sku_id int PRIMARY KEY,
count int
)
一个/buy接口
begin()
count = db.Query(`select count from orders where sku_id = '123'`)
if count < 0 {
fmt.Println("卖光了")
return ;
}
db.Exec(`update orders set count = count -1 where sku_id = '123'`)
commit()
由于sql 支持并行加上事务的隔离性,所以当多个事务并行时,select出来的值并不一定准确的,进而update之后的值也就不正确了。
方案一数据库悲观锁
数据库设置字段为无符号型
当并发超卖时直接报异常
通过捕获异常提示已经售空。
方案二:数据库悲观锁
采用排他锁
当用户同时到达更新操作,同时到达的用户一个个执行
在当前这个update语句commit之前,其他用户等待执行
解决方法:
begin()
update orders set count = count -1 where count > 0 and sku_id = '123'
commit()
这里是利用了update造成的行级锁,避免了超卖的问题。
优点:确保了线程安全。
缺点:高并发场景下会导致多个请求一直等待,数据库性能下降,系统的链接数上升,负载飙升,影响系统的平均响应时间,甚至会瘫痪。
数据库悲观锁优化
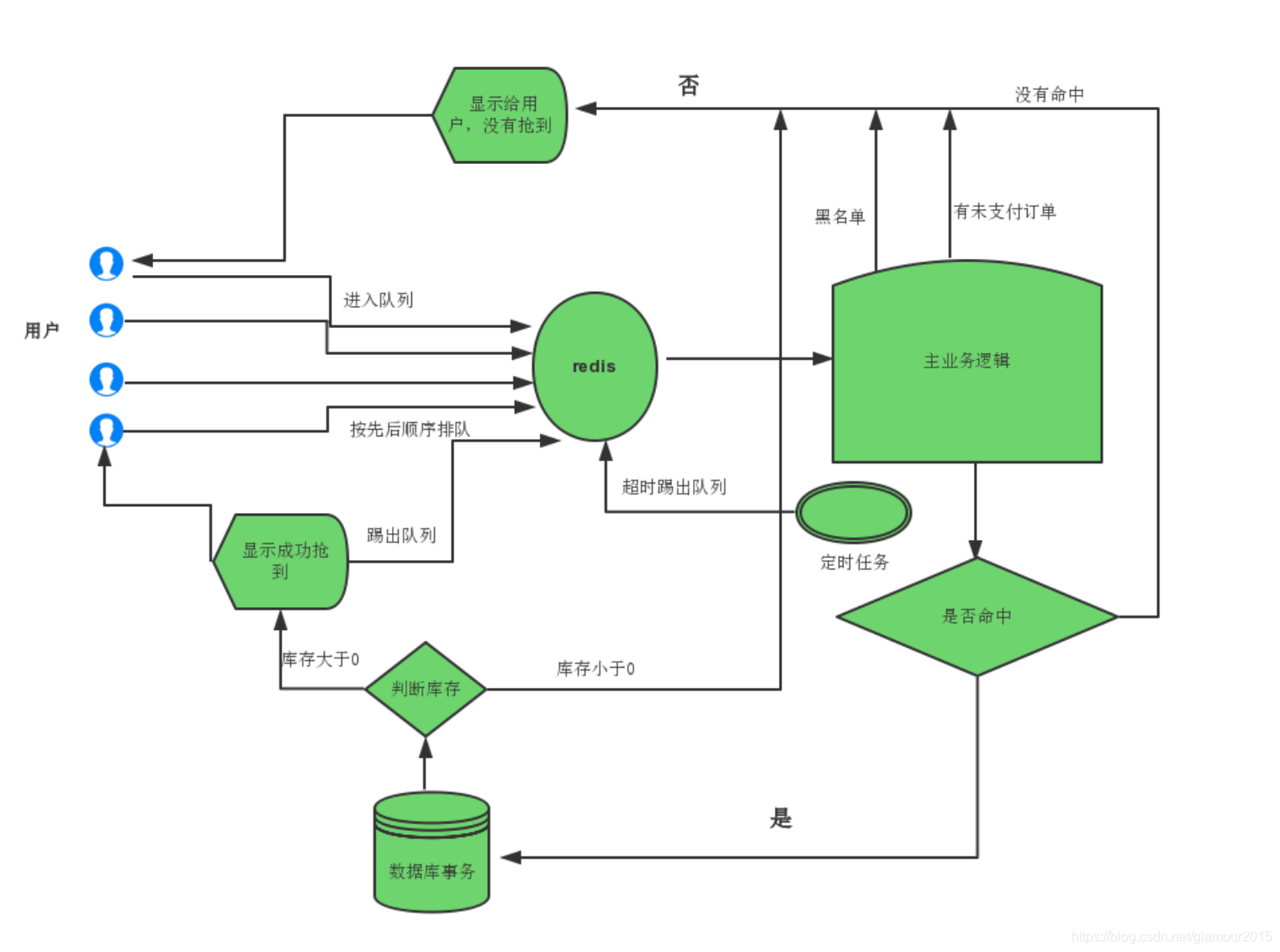
上述的方案的确解决了线程安全的问题,但是,别忘记,我们的场景是“高并发”。也就是说,会很多这样的修改请求,每个请求都需要等待“锁”,某些线程可能永远都没有机会抢到这个“锁”,这种请求就会死在那里。针对这个问题我们稍微修改一下上面的场景,我们直接将请求放入队列中的,采用FIFO(First Input First Output,先进先出),这样的话,我们就不会导致某些请求永远获取不到锁。可以采用redis队列+mysql事务控制的方案.下面是整个执行流程图:
方案三:文件锁
当用户抢到一件促销商品后先触发文件锁,防止其他用户进入,该用户抢到促销品后再解开文件锁,放其他用户进行操作。这样可以解决超卖的问题,但是会导致文件得I/O开销很大。
优点确保了线程安全。
缺点是磁盘 IO 开销会变大。
方案四:缓存方案
由于数据库的性能问题,无法应对高并发的秒杀场景,所以通常的解决方案是利用缓存来完成,先在缓存中完成计数,然后再通过消息队列异步地入库。
redis由于其高速+单进程模型,省掉了很多并发的问题,所以可以被选来进行高速秒杀的工作。
方案一,FIFO队列串行化( redis list)
通过 FIFO 队列,使修改库存的操作串行化。
我们建立sku:id为键的list结构, 在得到sku的库存余量N之后,在sku:id中push N个值为1的元素。当秒杀时,执行lpop即可。当lpop返回nil时, 即代表库存卖完了。
优点:实现简单,不需要在单独加锁(无论是悲观锁还是乐观锁)。
缺点:队列的长度是有限的,必须控制好,不然请求会越积越多。当库存非常大时, 会占用非常多的内存。
方案二, Redis原子操作(redis incr)
仍然是sku:id为键,但是直接设置为库存余量N。当秒杀时,执行DECR 即可,当DECR返回值小于0时,即代表库存卖完了。
优点: 节约内存
缺点:decr incr的操作范围都是int64,当decr min_int64时,redis会报告overflow。不过好在考虑到业务实际,几乎不会出现该情况,毕竟库存终究会刷新的,秒杀也不可能一直持续下去。
方案三, redis 分布式锁
锁似乎一直都是用来解决并发问题的良药。redis由于其单进程的模型,很多设计都可以作为分布式锁来用,在sku:id中保存库存余量, 以sku_lock:id作为其锁,当成功获得锁后, 对sku:id进行获取,减1。
比较常见的是setnx来做分布式锁。
setnx: 当只在键 key 不存在的情况下, 将键 key 的值设置为 value ,返回1。
若键 key 已经存在, 则 SETNX 命令不做任何动作,返回0。
因此当setnx返回1时即意味着加锁成功,返回0即加锁失败。解锁操作比较简单,del掉这个key就可以了。
优点: 锁似乎永远都可以作为解决并发问题的银弹,因此当你发现并发造成数据不一致的时候,从解决问题的思路出发,第一反应应该是加锁,第二反应才应该是无锁化的优化操作。
缺点:明显比前两种方案增加了一些代价。另外,由于该锁并不是阻塞型的,没有排队机制,并不会遵循先到先到的逻辑。
方案五:乐观锁解决方案
悲观锁的解决方案解决了锁的问题,全部请求采用“先进先出”的队列方式来处理。那么新的问题来了,高并发的场景下,因为请求很多,系统处理队列内请求的速度根本无法和疯狂涌入队列中的数目相比,很可能一瞬间将队列内存“撑爆”,最终Web系统平均响应时候还是会大幅下降,系统还是陷入异常。
这个时候,我们就可以讨论一下“乐观锁”的思路了。乐观锁,是相对于“悲观锁”采用更为宽松的加锁机制,大都是采用带版本号(Version)更新。实现就是,这个数据所有请求都有资格去修改,但会获得一个该数据的版本号,只有版本号符合的才能更新成功,其他的返回抢购失败。这样的话,我们就不需要考虑队列的问题,不过,它会增大CPU的计算开销。但是,综合来说,这是一个比较好的解决方案。
乐观锁的执行流程如下:
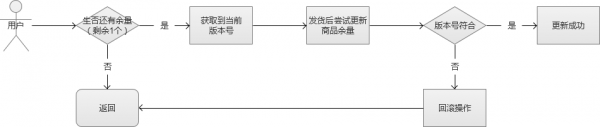
Redis 的 watch机制
采用redis数据库,前置到mysql。思路如下:
2.1系统启动后,初始化sku信息到redis数据库,记录其可用量和锁定量
2.2使用乐观锁,采用redis的watch机制。逻辑为:
1.定义门票号变量,设置初始值为0。watchkey
2.watch该变量,watch(watchkey);
3.使用redis事务加减库存。首先获取可用量和抢购量比较,如果curcount>buycount,那么正常执行减库存和加锁定量操作:
multi;
redis incr watchkey;
redis decrby curcount buycount;
redis incrby lockcount buycount;
exec;
由于上述操作都在事务内进行,一旦watchkey被其他的事务修改过,那么exec将返回nil,如此就放弃本次请求。一般都是在循环中重复尝试直到成功或没有可用量。
最后通过订单信息流,保证mysql数据库的最终一致性。
结论
总的来说,不能把压力放在数据库上,所以使用"select xxx for update"的方式在高并发的场景下是不可行的。FIFO 同步队列的方式,可以结合库存限制队列长,但是在库存较多的场景下,又不太适用。所以相对来说,我会倾向于选择:乐观锁/缓存锁/分布式锁的方式。
参考:https://hacpai.com/article/1536335417613
