**redis必须提供一种持久化策略,将redis没有出问题前的内存数据,dump到磁盘上去,就是之前的序列化过程,内存的结构毕竟和磁盘结构不一样,必须把内存的数据序列化之后存到磁盘中,数据从内存到了磁盘,就完成了一次dump。
我们dump的时候,会让dedis的服务暂时停止,所以这种dump方式称为镜像,但是有问题,只能保存一个时间点的,之后的变化就没了,这种方式成为RDB方式。
**
RDB也是默认开启的持久化方案,策略有两种:自动策略,手动策略。
自动,是由redis服务管理者,由它来敲一个命令,save或者BGsave。
SAVE:是当前环境执行,会导致暂时服务停止响应
BGSAVE:到后台,redis会启动一个子进程,由这个子进程在后台把数据从内存同步至磁盘,(先快照再同步,以免数据不一致),主程序可以向客户端继续提供服务(但是内存快满就不太好用,毕竟开一个进制,还会引起数据的复制,会导致内存耗尽)

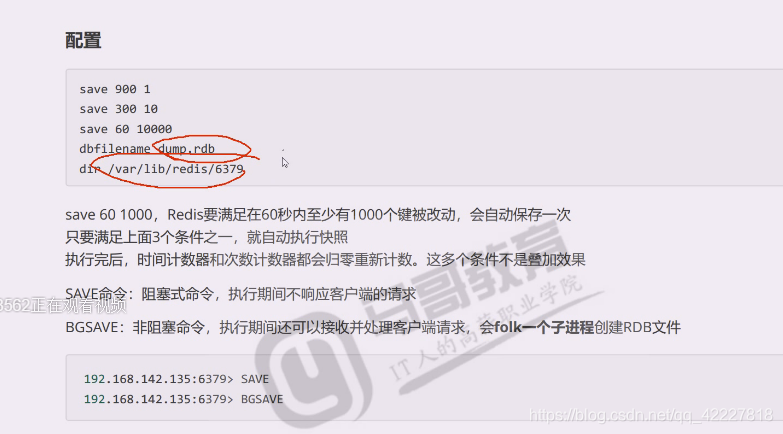
dump.rdb,是内存拿下来存的文件,以后就靠这个文件来恢复,
dbfilename dump.rdb:指定rdb文件名
dir /var/lib/redis:rdb文件的存储路径
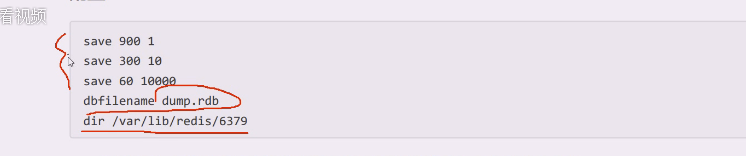
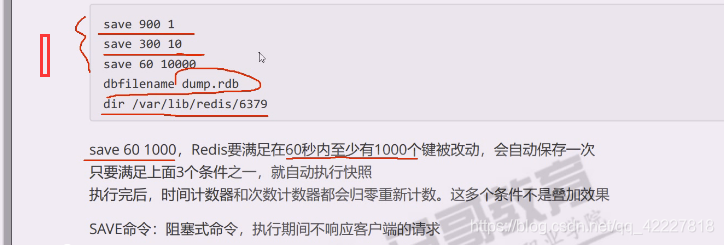
满足60秒内至少有1000个键发生改的,会自动保存一次

这个三个条件是依次看的,但凡有一个条件被触发了,就相当于立即就dump一次,重新开始计时。
假如任何一个条件刚dump完一次,结果redis崩了,如果有dump文件,就会用dump文件来还原当时你的内存的所有数据
有些场景没有事务要求更高,但是有事务就可以保证数据的完整性一致性,这里redis的服务,要是 中间用户的评论的数据没了还可以接收,但是交易的数据就不能方redis里了。需要事务
save是阻塞式的命令,执行期间不响应客户端的请求。
BGsave是非阻塞命令,执行期间还可以接收用户请求,会folk一个子进程来创建RDB文件,(注意内存使用,可能会出现内存不够的情况)

redis持久化访问有两种,一种RDB,一种AOF,append only file
敲完命令就可以看到这个文件了
优点:
1.完全的内存备份,完全的内存镜像,不同时间的数据集可以恢复(多版本就是每次dump下来,写一个脚本,可以把dump的文件搬到更安全的地方去,要恢复就把这个文件搬过来,到时候可以指定恢复)
2.是单一文件,单一文件传输方便点,适合灾难恢复
3.快照文件直接恢复,大数据集速度教AOF快(它是直接把dump文件序列化在内存里直接构建)

缺点:
1.在dump之后的数据就会被丢掉了
2.BGSAVE,folk过程比较耗时,其实是folk开启之后内存不够的情况下,如果用到swap交换内存就会带来很大的性能问题

RDB备份策略:
可以定时任务,看你忍受程度,每小时还是每天将dump文件复制到指定目录,也可以定时删除任务。
2u机器,戴尔710,一个机架是有风险的,一般故意要跨机架。
机房着火用四氯化氮,不会用水。
分布式文件系统也会多文本分布,把一个整文件打散了,这些分散在不同的节点,在某一个副本还会再分散。,一部分坏了,在其他节点也可以找到,不管是HDFS,fastfs,全是这样的。每种分布式文件系统要管理数据就要用不同的方法,分散方式也不同
*
AOF append only file
其实跟mysql的binlog是一样的。写指令会造成redis的变化,写指令,是让redis从一个状态变成另外的状态,所以要记住写指令。
记录所有的写操作命令,这种恢复叫重演replay,将所有对数据库的改变重新再来一遍,AOF不作为首选的原因,是因为写指令对于操作数据库来讲太慢了。
有时候重演太慢了,不如RDB还原快

RDB如果你设置一秒一次就触发,那就不停在写磁盘了,就没性能可言了
AOF也不能保证绝对不丢失数据,写指令是要记录到文件,appendonly.aof里的,如果文本文件没写进去,整个机器就挂了,就没办法了

目前常用操作系统中,执行系统调用write函数,文件操作就要用这个系统调用,为了提高效率其实是用批处理方式,不会将内容直接写入磁盘中,会写成一个内存中的缓冲区buffer(在内核态中,缓冲区满了或者用户调用fsync,这时候才写磁盘),如果还没写磁盘,机器坏了,这些指令就没了。
**
可以在这个配置的时候加一下些策略,有三种:
always,只要有一条写指令就给你写磁盘。最多丢一条,但是太伤硬盘了,写操作会出问题,磁盘适合一批一批的
everysec,每一秒收集了多少,就要求写一次磁盘,这样就丢一秒钟的指令
no,全部交给操作系统,它认为什么时候能写进去就写进去,丢失的不可预期**

AOF,保存了所有写指令,这样会导致文件越拉越大,所以redis提了叫合并,会将质量合并,压缩AOF

重写过程:
1.folk一个子进程负责重写AOF文件
2.子进程会创建一个临时文件写入AOF信息
3.父进程会开辟一个内存缓冲区接收新的命令
4.子进程重写完成后,父进程会获得一个信号,将父进程接收到新的写操作由子进程写入到临时文件中
5.新文件替代旧文件
如果有问题就用redis-check-aof来修复一下

重写机制

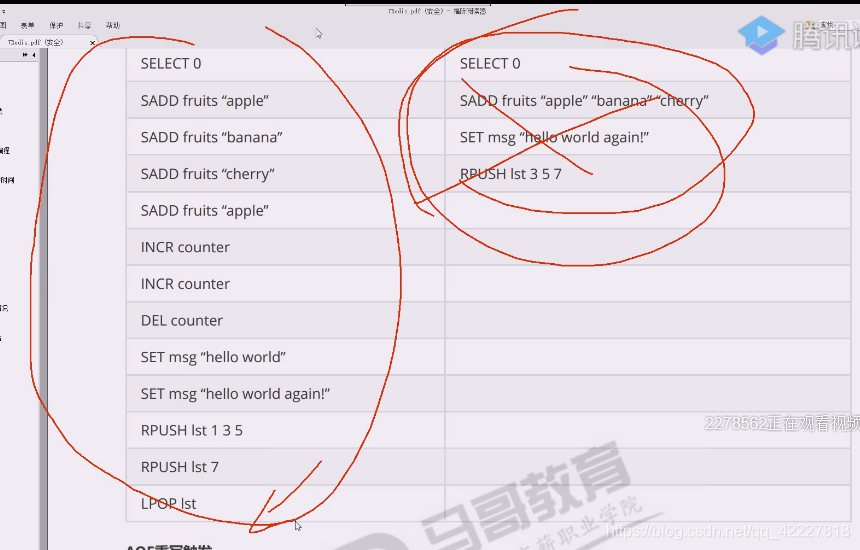
重写后这样文本文件就缩小了很多
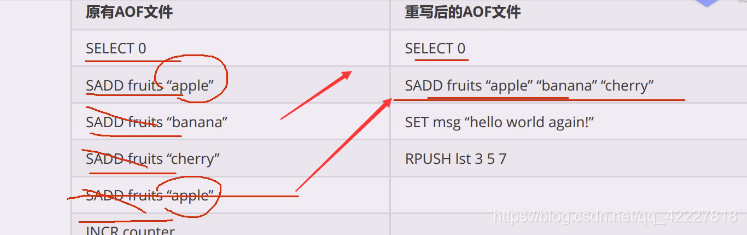
这个删删减减等于废语句,根本没必要存在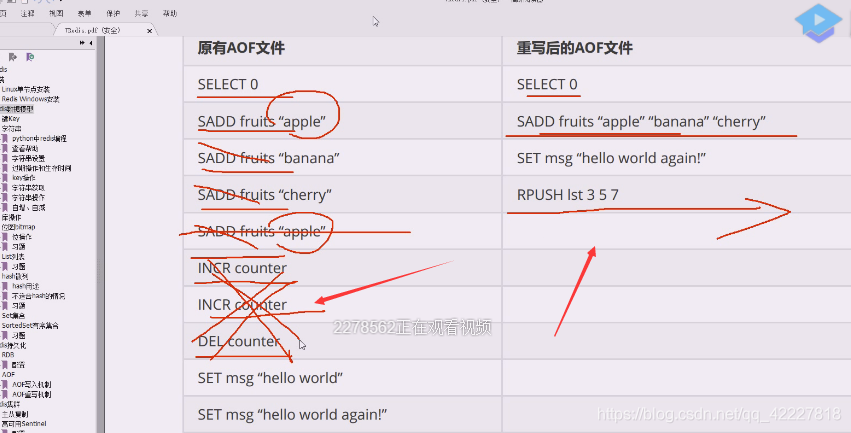
左边的文本缩减成右边的,但是重演出来的效果是一样的
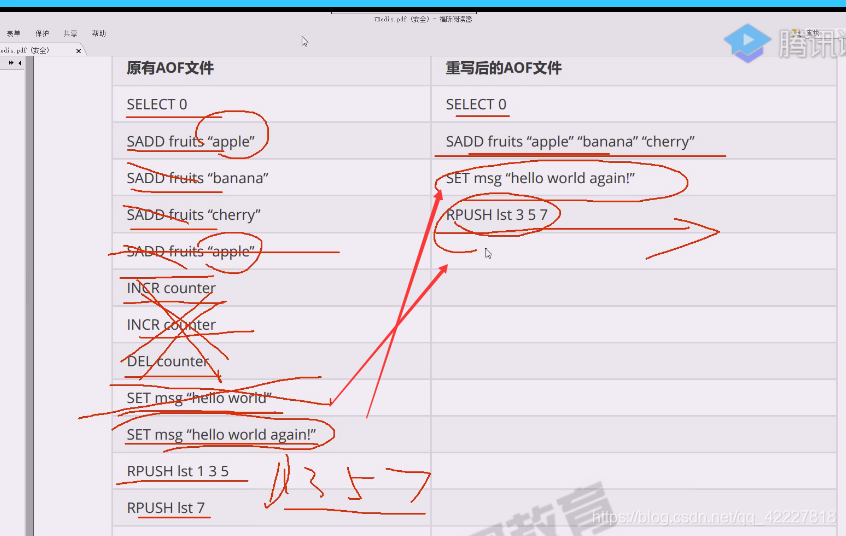
后面有个flushdb,后面这些就都不要了
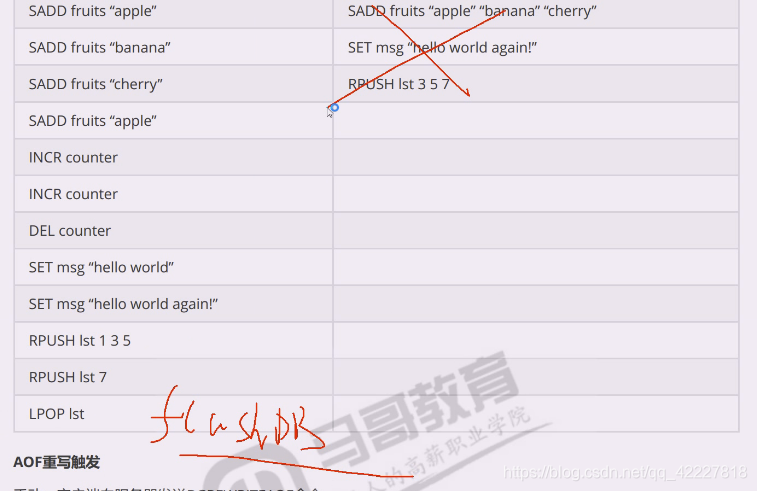
假如误操作flushdb了,RDB如果生成了还来得及,因为AOF没重写过,AOF就剩flushdb了就麻烦了,只要AOF还没被重写过,虽然RDB覆盖了,但是还可以通过当下的AOF文件,可以重演恢复原内存,重演之前先把最后的flushdb干掉。
缓存服务器是为了让压力不压到mysql上的,带来的雪崩,是后果不敢想的
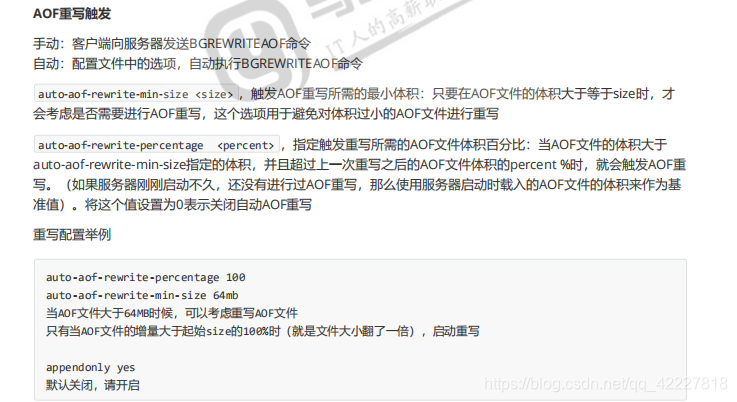
AOF何时重写,也有两种:
手动:
自动:
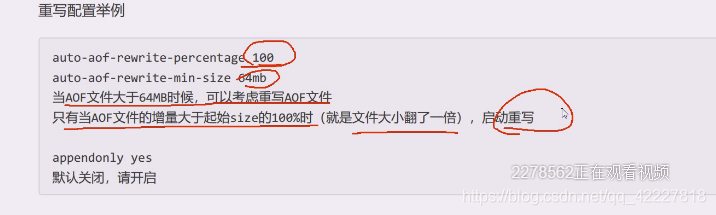
auto-aof-rewrite-min-size 自动AOF重写的最小大小,达到大小,只是会考虑是否要重写,这个是避免体积太小AOF文件进行重写,浪费时间,因为磁盘IO毕竟慢
auto-aof-rewrite-percentage,如果这次增加比上一次增加了多少百分比就会触发重写。,以上一次的AOF文件大小做为基准值来判断,但是如果没超过最小体积也是不会改变的

AOF如果和RDB同时开启,优先使用AOF,RDB形同虚设,一般AOF不开启,但是数据丢了,没办法,因为单点肯定出事情,我们就要考虑集群来解决问题
优点:
写入机制,默认fysnc每秒执行,性能很好不阻塞服务,最多丢失一秒的数据,重写机制,可以优化AOF文件体积,误删除了,AOF还可以救你一次,停止服务把AOF文件最后的FLUSHALL干掉


**缺点:
相同数据集,AOF文件大于RDB,因为是文本的;
恢复速度快,就用RDB
**

因为有这些持久化方案的问题,所以避免单点,利用集群来解决,单点的服务要靠一起来支持,让它不要出现这种问题