环顾当今社会,或多或少可称之为被交易系统控制的社会。我们的股票市场离不开交易系统,我们的银行离不开交易系统,我们出行做出租离不开交易系统,我们的网上购物离不开交易系统等等。仔细想想交易系统还真是主宰了我们的很多行为或者重新定义了我们的行为。交易系统是我们技术人员的智慧结晶,聚集了技术人员的辛勤和汗水。设计一套交易系统不容易,设计一套高并发、高可用的交易系统更不容易,但是随着业务的深入发展,这块又是谁也避免不了的问题。本篇我们来聊聊交易系统的高并发问题。
每个系统都有其独特的特点,因此设计方案都可能不尽相同,但一些基本的设计原则还是可以参考的。
原则一 设计应该是无状态的
如果应用是无状态的话,系统就比较容易水平扩展。一般实际生产环境是:应用无状态、配置文件有状态。比如不同的机房要读取不同的数据源,此时,就需要通过配置文件或配置中心指定。
原则二 系统拆分
每个系统初期可能都是一个大而全的系统,因为初期的业务量一般都不是很大,一般一个单体都能够支撑。随着业务快速发展,单体系统能够调用的资源有限,无法再支撑更大的交易量,这时就需要拆分系统,每个被拆分的系统支撑独立的功能,可以根据需要水平扩展。根据具体的业务情况拆分的维度也不一样。一般分为系统维度、功能维度、读写维度、AOP维度及模块维度等。
系统维度:
按照业务功能拆分,比如交易系统可以拆分为商品系统、购物车、结算、订单系统等。

功能维度:
对一个系统对功能进行再拆分,实际上这就是对系统维度的深度拆分。比如订单系统可拆分为手机端订单和pc端订单等。
读写维度:
根据系统功能的读写比例进行拆分。比如商品系统,交易的各个系统都会读取数据,读的量远大于写的量,因此可拆分为商品读服务、商品写服务;读服务可以考虑使用缓存提升性能;写的量太大时可以考虑分表分库;有些聚合读取的场景可以考虑数据库异构、搜索引擎Elasticsearch及hbase数据库等。严格的说这不是系统拆分而是一种实现方案。
AOP维度:
根据访问特征,按照AOP进行拆分,比如商品详情页可分为CDN、页面渲染系统;CDN就是一个AOP系统。
模块维度:
按照基础或代码维护特征进行拆分,如第三方控件使用代码、数据库连接池、基础模块分表分库等;传统经典的mvc架构等等。
原则三 服务化
设计一个系统,我首先要考虑一些问题:用户有多少、交易量有多少、业务增长的趋势、系统的可用性、系统故障容忍度等等。针对这些问题设计系统方案,是不是单体系统就可解决?是不是集群就可以解决?前端使用Nginx负载均衡是不是可以解决?随着调用方的增多,我们的服务如何注册和被发现?服务之间的稳定性如何保证,服务之间是否需要隔离、服务分组?如何对大流量做流量控制,是否要做访问黑白名单控制等?
原则四 消息队列
消息队列用来解耦不需要同步调用的服务或者订阅系统关心的变化。使用消息队列可以实现服务解耦,异步处理,流量削峰等。电商系统的交易订单数据会被多个系统所订阅,订单生成系统,定期送系统,风控系统等。

如果订阅者太多,那么订阅单个消息队列就会成为瓶颈,此时需要考虑对消息队列进行多个镜像复制。
使用消息队列时,还要注意处理产生消息失败及消息重复处理的情况。有些消息队列会提供产生重试功能,再达到重试次数还未成功时对外通知生产失败。这是对于不能容忍失败的业务场景来说,一定要做好后续的数据处理工作,比如增加日志,报警等。对于重复性消息,一定要做好系统的防重设计和幂等设计。市面上的消息控件有很多,不同的消息产品侧重点都有所差异,笔者给出各种消息控件的对比图,供老铁们选择时参考。
原则五 数据异构
一般来说系统开始都是单体系统,数据库也是单库,比较好一点的可能会做到读写分离,在读数据库这一块也是各种复杂的查询语句。这种结构在数据量不大的情况下可能问题不大,但随着业务量的急剧增长,这种架构简直就是灾难,即使做分表分库基本上不能支撑多久。此时需要按照我们的查询需求对订单表进行异构,比如我们要查询某个用户的订单列表,那么我们就可以按照用户ID做数据异构,按照数据数据ID进行数据保存。当然我们数据异构的保存载体不仅仅是同类型的数据库,也可以是其他类型的数据载体,比如搜索引擎Elasticsearch、OLAP类型数据库mpp等,可以根据我们的业务特点灵活选择我们的数据异构方式,总之一切为业务方便服务。数据异构的来源一般通过消息队列实现数据分发。

上图较完整的诠释了数据异构的思想:订单在写入mysql数据库时同时通过消息通知将数据库写入了MongoDB数据库和ES搜索引擎,在MongoDB数据库和ES搜索引擎内可以按照我们的查询要求重新组装数据提供业务查询,如此可大大提高查询效率,对mysql数据库基本没啥依赖,使mysql有更多做主流程业务,间接提高了整个系统的效率。
原则六 缓存
缓存是读服务对抗流量的利器,缓存主要目的是减少向更深一层的系统底层访问,减少整个系统资源的消耗,提高系统性能。缓存无处不在,在系统的各个层面都有对应处理手段,下图是系统的流程节点及对应的缓存技术

下面对各个缓存技术做个简要说明。
1.浏览器缓存
设置请求的过期时间,如对响应头Expires、Catch-control进行控制。这种机制适用于对实时性不太敏感的数据,如广告词、评价、商家评分等;对于价格、库存等实时性较高的数据不太建议用此方法。
2.APP客户端缓存
在做秒杀系统时,为了防止瞬间流量冲击,一般会在秒杀之前把APP需要访问的一些素材(如js/css/image)提前下发到客户端进行缓存,这样在秒杀是就不用去拉取这些素材了。如果首屏数据也可以缓存起来,那么万一出现网络异常,首屏数据既可以作为托底数据展示也用户
3.CDN缓存
有些页面、活动也页、图片推送到离用户最近的CDN节点,使用户在最近的节点找到想要的数据。一般有两种机制:推送机制和拉取机制,两种机制各有利弊。使用CDN时要考虑URL的设计,比如URL不能有随机数,否则每次都穿透CDN回源到服务器,相当于CDN没有任何效果。
4.接入缓存
对于没有CDN缓存的应用来说,可以考虑使用Nginx搭建一层接入层。此处要注意,对于托底数据或异常数据,不应该让其缓存,否则用户在很长一段时间看到该数据。
5.应用层缓存
在使用tomcat时,可以使用堆内缓存/堆外缓存,堆内缓存最大问题是重启是内存中的缓存会丢失,流量风暴来临有可能冲垮应用。还可以使用local redis catch来代替堆外缓存。所谓的local redis catch就是在应用所在服务器上部署一组Redis,应用直接读取本机redis获取数据,多机之间使用主从同步机制同步数据,这种方式没有网络消耗,性能是最优的。
6.分布式缓存
在第5点中谈到使用local redis catch来做缓存性能最优,但是该方案毕竟是单机结构,但是如果数据量太大,单服务器存储不了,那么可以使用分片机制将流量分散到多台,或者直接使用分布式缓存实现。常见的分片规则就是一致性哈希了,当然你也可以根据实际需求制定你的分片 算法。
7.并发化
随着计算机硬件的不断发展,cpu基本上都为双核甚至为多核,如果还是用串行的方式来处理业务,简直就是暴殄天物啊。
假设一个读服务需要如下数据。
 如果用串行的方式,需要60ms。
如果用串行的方式,需要60ms。
而如果C依赖A和B、D谁也不依赖,E依赖C那么可以这样来获取数据。
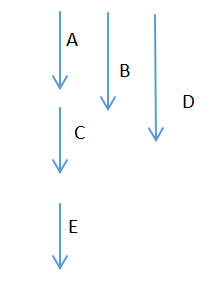
如果并发化获取,则需要30秒,提升一倍的性能。
总结
以上就是笔者总结的高并发系统可以重点考虑的几点,当然每个系统都有其独特的业务要求,不能一股脑的堆砌这些技术,需要有针对性的取舍,因为没有最好,只有合适。
