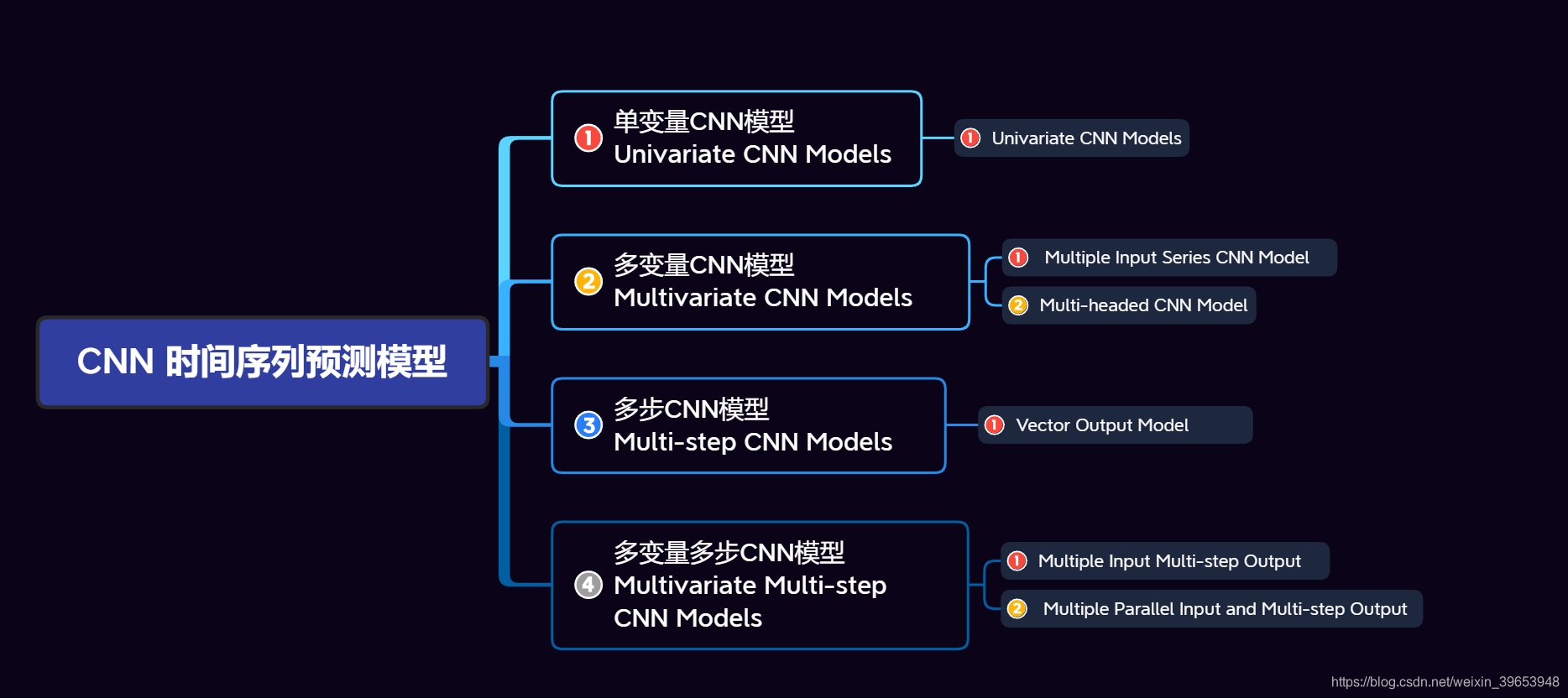
接上文,本文介绍了开发CNN时间序列模型中的后两个知识点:多步CNN模型和多变量多步输出CNN模型来解决时间序列预测问题(思维导图中的3、4)。看一下这两篇文章的思维导图:
文章目录
2.3 多步 CNN 模型
与一步预测一样,用于多步时间序列预测的时间序列必须分成具有输入和输出分量的样本。输入和输出组件将由多个时间步组成,并且可能具有或可能不具有相同的步数。例如,给定一元时间序列:
[10, 20, 30, 40, 50, 60, 70, 80, 90]
输入:
[10, 20, 30]
输出:
[40, 50]
整个数据集划分为样本:
[10 20 30] [40 50]
[20 30 40] [50 60]
[30 40 50] [60 70]
[40 50 60] [70 80]
[50 60 70] [80 90]
2.3.1 向量输出模型
CNN希望数据有一个三维结构[样本,时间步,特征],在这种情况下,我们只有一个特征,因此重塑数据很简单。
n_features = 1
X = X.reshape((X.shape[0], X.shape[1], n_features))
在n步输入和n步输出变量中指定输入和输出步数,就可以定义一个多步时间序列预测模型。代码实现:
model = Sequential()
model.add(Conv1D(filters=64, kernel_size=2, activation='relu', input_shape=(n_steps_in,
n_features)))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(50, activation='relu'))
model.add(Dense(n_steps_out))
model.compile(optimizer='adam', loss='mse')
完整代码:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv1D, MaxPooling1D
def split_sequences(sequence, n_steps_in, n_steps_out, n_features):
'''
该函数将序列数据分割成样本
'''
X, y = [], []
for i in range(len(sequence)):
end_ix = i + n_steps_in
out_end_ix = end_ix + n_steps_out
if out_end_ix > len(sequence):
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix:out_end_ix]
X.append(seq_x)
y.append(seq_y)
X, y = np.array(X), np.array(y)
X = X.reshape((X.shape[0], X.shape[1], n_features))
print('train_X:\n{}\ntrain_y:\n{}\n'.format(X, y))
print('train_X.shape:{},trian_y.shape:{}\n'.format(X.shape, y.shape))
print('n_features:',n_features)
return X, y
def oned_cnn_model(steps_in, n_features, steps_out, X, y, test_X, epoch_num, verbose_set):
model = Sequential()
model.add(Conv1D(filters=64, kernel_size=2, activation='relu',
strides=1, padding='valid', data_format='channels_last',
input_shape=(steps_in, n_features)))
model.add(MaxPooling1D(pool_size=2, strides=None, padding='valid',
data_format='channels_last'))
model.add(Flatten())
model.add(Dense(units=50, activation='relu',
use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros',))
model.add(Dense(units=steps_out))
model.compile(optimizer='adam', loss='mse',
metrics=['accuracy'], loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None)
print('\n',model.summary())
history = model.fit(X, y, batch_size=32, epochs=epoch_num, verbose=verbose_set)
yhat = model.predict(test_X, verbose=0)
print('\nyhat:', yhat)
return model, history
if __name__ == '__main__':
train_seq1 = [10, 20, 30, 40, 50, 60, 70, 80, 90]
n_steps_in, n_steps_out = 3, 2
n_features = 1
epoch_num = 2000
verbose_set = 0
train_X, train_y = split_sequences(train_seq1, n_steps_in, n_steps_out, n_features)
# 预测
x_input = np.array([70, 80, 90])
x_input = x_input.reshape((1, n_steps_in, n_features))
model, history = oned_cnn_model(n_steps_in, n_features, n_steps_out, train_X, train_y, x_input, epoch_num, verbose_set)
print('\ntrain_acc:%s'%np.mean(history.history['accuracy']), '\ntrain_loss:%s'%np.mean(history.history['loss']))
输出:
train_X:
[[[10]
[20]
[30]]
[[20]
[30]
[40]]
[[30]
[40]
[50]]
[[40]
[50]
[60]]
[[50]
[60]
[70]]]
train_y:
[[40 50]
[50 60]
[60 70]
[70 80]
[80 90]]
train_X.shape:(5, 3, 1),trian_y.shape:(5, 2)
n_features: 1
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1d_5 (Conv1D) (None, 2, 64) 192
_________________________________________________________________
max_pooling1d_5 (MaxPooling1 (None, 1, 64) 0
_________________________________________________________________
flatten_5 (Flatten) (None, 64) 0
_________________________________________________________________
dense_18 (Dense) (None, 50) 3250
_________________________________________________________________
dense_19 (Dense) (None, 2) 102
=================================================================
Total params: 3,544
Trainable params: 3,544
Non-trainable params: 0
_________________________________________________________________
None
yhat: [[102.96412 114.83157]]
train_acc:1.0
train_loss:74.88895527674454
2.4 多变量多步CNN模型
2.4.1 多输入多步输出(Multiple Input Multi-step Output)
在多变量时间序列预测问题中,输出序列是独立的,但依赖于输入序列,输出序列需要多个时间步。例如,考虑前面一节中的多元时间序列:
[[ 10 15 25]
[ 20 25 45]
[ 30 35 65]
[ 40 45 85]
[ 50 55 105]
[ 60 65 125]
[ 70 75 145]
[ 80 85 165]
[ 90 95 185]]
我们可以使用两个输入时间序列中每一个的三个先验时间步的值来预测输出时间序列的两个时间步的值。
输入:
10, 15
20, 25
30, 35
输出:
65
85
对于整个数据集来划分:
[[10 15]
[20 25]
[30 35]] [65 85]
[[20 25]
[30 35]
[40 45]] [ 85 105]
[[30 35]
[40 45]
[50 55]] [105 125]
[[40 45]
[50 55]
[60 65]] [125 145]
[[50 55]
[60 65]
[70 75]] [145 165]
[[60 65]
[70 75]
[80 85]] [165 185]
样本划分可以通过函数实现,请看完整代码:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv1D, MaxPooling1D
def split_sequences(first_seq, secend_seq, steps_in, steps_out):
'''
该函数将序列数据分割成样本
'''
input_seq1 = np.array(first_seq).reshape(len(first_seq), 1)
input_seq2 = np.array(secend_seq).reshape(len(secend_seq), 1)
out_seq = np.array([first_seq[i]+secend_seq[i] for i in range(len(first_seq))])
out_seq = out_seq.reshape(len(out_seq), 1)
dataset = np.hstack((input_seq1, input_seq2, out_seq))
print('dataset:\n',dataset)
X, y = [], []
for i in range(len(dataset)):
end_element_index = i + steps_in
out_end_index = end_element_index + steps_out-1
if end_element_index > len(dataset)-1:
break
seq_x, seq_y = dataset[i:end_element_index, :-1], dataset[end_element_index-1:out_end_index, -1]
X.append(seq_x)
y.append(seq_y)
process_X, process_y = np.array(X), np.array(y)
n_features = process_X.shape[2]
print('train_X:\n{}\ntrain_y:\n{}\n'.format(process_X, process_y))
print('train_X.shape:{},trian_y.shape:{}\n'.format(process_X.shape, process_y.shape))
print('n_features:',n_features)
return process_X, process_y, n_features
def oned_cnn_model(step_in, step_out, n_features, X, y, test_X, epoch_num, verbose_set):
model = Sequential()
model.add(Conv1D(filters=64, kernel_size=2, activation='relu',
strides=1, padding='valid', data_format='channels_last',
input_shape=(step_in, n_features)))
model.add(MaxPooling1D(pool_size=2, strides=None, padding='valid',
data_format='channels_last'))
model.add(Flatten())
model.add(Dense(units=50, activation='relu',
use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros',))
model.add(Dense(units=step_out))
model.compile(optimizer='adam', loss='mse',
metrics=['accuracy'], loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None)
print('\n',model.summary())
history = model.fit(X, y, batch_size=32, epochs=epoch_num, verbose=verbose_set)
yhat = model.predict(test_X, verbose=0)
print('\nyhat:', yhat)
return model, history
if __name__ == '__main__':
train_seq1 = [10, 20, 30, 40, 50, 60, 70, 80, 90]
train_seq2 = [15, 25, 35, 45, 55, 65, 75, 85, 95]
n_steps_in, n_steps_out = 3, 2
epoch_num = 1000
verbose_set = 0
train_X, train_y, n_feature = split_sequences(train_seq1, train_seq2, n_steps_in, n_steps_out)
# 预测
x_input = np.array([[70, 75], [80, 85], [90, 95]])
x_input = x_input.reshape((1, n_steps_in, n_feature))
model, history = oned_cnn_model(n_steps_in, n_steps_out, n_feature, train_X, train_y, x_input, epoch_num, verbose_set)
print('\ntrain_acc:%s'%np.mean(history.history['accuracy']), '\ntrain_loss:%s'%np.mean(history.history['loss']))
输出:
dataset:
[[ 10 15 25]
[ 20 25 45]
[ 30 35 65]
[ 40 45 85]
[ 50 55 105]
[ 60 65 125]
[ 70 75 145]
[ 80 85 165]
[ 90 95 185]]
train_X:
[[[10 15]
[20 25]
[30 35]]
[[20 25]
[30 35]
[40 45]]
[[30 35]
[40 45]
[50 55]]
[[40 45]
[50 55]
[60 65]]
[[50 55]
[60 65]
[70 75]]
[[60 65]
[70 75]
[80 85]]]
train_y:
[[ 65 85]
[ 85 105]
[105 125]
[125 145]
[145 165]
[165 185]]
train_X.shape:(6, 3, 2),trian_y.shape:(6, 2)
n_features: 2
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1d_4 (Conv1D) (None, 2, 64) 320
_________________________________________________________________
max_pooling1d_4 (MaxPooling1 (None, 1, 64) 0
_________________________________________________________________
flatten_4 (Flatten) (None, 64) 0
_________________________________________________________________
dense_8 (Dense) (None, 50) 3250
_________________________________________________________________
dense_9 (Dense) (None, 2) 102
=================================================================
Total params: 3,672
Trainable params: 3,672
Non-trainable params: 0
_________________________________________________________________
None
yhat: [[187.56087 217.18515]]
train_acc:0.921
train_loss:440.7402523803711
2.4.2 多并行输入多步输出 (Multiple Parallel Input and Multi-step Output)
具有并行时间序列的问题可能需要预测每个时间序列的多个时间步。例如,考虑前面一节中的多元时间序列:
[[ 10 15 25]
[ 20 25 45]
[ 30 35 65]
[ 40 45 85]
[ 50 55 105]
[ 60 65 125]
[ 70 75 145]
[ 80 85 165]
[ 90 95 185]]
我们可以使用三个时间序列中每一个的最后三个时间步作为模型的输入,并预测三个时间序列中每一个的下一个时间步作为输出。训练数据集中的第一个样本如下。
输入:
10, 15, 25
20, 25, 45
30, 35, 65
输出:
40, 45, 85
50, 55, 105
将整个数据集划分成样本:
[[10 15 25]
[20 25 45]
[30 35 65]] [[ 40 45 85]
[ 50 55 105]]
[[20 25 45]
[30 35 65]
[40 45 85]] [[ 50 55 105]
[ 60 65 125]]
[[ 30 35 65]
[ 40 45 85]
[ 50 55 105]] [[ 60 65 125]
[ 70 75 145]]
[[ 40 45 85]
[ 50 55 105]
[ 60 65 125]] [[ 70 75 145]
[ 80 85 165]]
[[ 50 55 105]
[ 60 65 125]
[ 70 75 145]] [[ 80 85 165]
[ 90 95 185]]
我们现在可以为这个数据集开发1D CNN模型。在这种情况下,我们将使用矢量输出模型。因此,为了训练模型,我们必须将每个样本输出部分的三维结构展平。这意味着,该模型不是为每个序列预测两个时间步的输出值,而是训练并期望直接预测一个有六个元素的向量。代码实现:
n_output = y.shape[1] * y.shape[2]
y = y.reshape((y.shape[0], n_output))
完整代码:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv1D, MaxPooling1D
def split_sequences(first_seq, secend_seq, steps_in, steps_out):
'''
该函数将序列数据分割成样本
'''
input_seq1 = np.array(first_seq).reshape(len(first_seq), 1)
input_seq2 = np.array(secend_seq).reshape(len(secend_seq), 1)
out_seq = np.array([first_seq[i]+secend_seq[i] for i in range(len(first_seq))])
out_seq = out_seq.reshape(len(out_seq), 1)
dataset = np.hstack((input_seq1, input_seq2, out_seq))
print('dataset:\n',dataset)
X, y = [], []
for i in range(len(dataset)):
end_element_index = i + steps_in
out_end_index = end_element_index + steps_out
if out_end_index > len(dataset):
break
seq_x, seq_y = dataset[i:end_element_index, :], dataset[end_element_index:out_end_index, :]
X.append(seq_x)
y.append(seq_y)
X, y = np.array(X), np.array(y)
n_output = y.shape[1] * y.shape[2]
y = y.reshape((y.shape[0], n_output))
n_features = X.shape[2]
print('train_X:\n{}\ntrain_y:\n{}\n'.format(X, y))
print('train_X.shape:{},trian_y.shape:{}\n'.format(X.shape, y.shape))
print('n_features:',n_features)
print('n_output:',n_output)
return X, y, n_features, n_output
def oned_cnn_model(step_in, step_out, n_features, n_output, X, y, test_X, epoch_num, verbose_set):
model = Sequential()
model.add(Conv1D(filters=64, kernel_size=2, activation='relu',
strides=1, padding='valid', data_format='channels_last',
input_shape=(step_in, n_features)))
model.add(MaxPooling1D(pool_size=2, strides=None, padding='valid',
data_format='channels_last'))
model.add(Flatten())
model.add(Dense(units=50, activation='relu',
use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros',))
model.add(Dense(units=n_output))
model.compile(optimizer='adam', loss='mse',
metrics=['accuracy'], loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None)
print('\n',model.summary())
history = model.fit(X, y, batch_size=32, epochs=epoch_num, verbose=verbose_set)
yhat = model.predict(test_X, verbose=0)
print('\nyhat:', yhat)
return model, history
if __name__ == '__main__':
train_seq1 = [10, 20, 30, 40, 50, 60, 70, 80, 90]
train_seq2 = [15, 25, 35, 45, 55, 65, 75, 85, 95]
n_steps_in, n_steps_out = 3, 2
epoch_num = 7000
verbose_set = 0
train_X, train_y, n_feature, n_output = split_sequences(train_seq1, train_seq2, n_steps_in, n_steps_out)
# 预测
x_input = np.array([[60, 65, 125], [70, 75, 145], [80, 85, 165]])
x_input = x_input.reshape((1, n_steps_in, n_feature))
model, history = oned_cnn_model(n_steps_in, n_steps_out, n_feature, n_output, train_X, train_y, x_input, epoch_num, verbose_set)
print('\ntrain_acc:%s'%np.mean(history.history['accuracy']), '\ntrain_loss:%s'%np.mean(history.history['loss']))
输出:
dataset:
[[ 10 15 25]
[ 20 25 45]
[ 30 35 65]
[ 40 45 85]
[ 50 55 105]
[ 60 65 125]
[ 70 75 145]
[ 80 85 165]
[ 90 95 185]]
train_X:
[[[ 10 15 25]
[ 20 25 45]
[ 30 35 65]]
[[ 20 25 45]
[ 30 35 65]
[ 40 45 85]]
[[ 30 35 65]
[ 40 45 85]
[ 50 55 105]]
[[ 40 45 85]
[ 50 55 105]
[ 60 65 125]]
[[ 50 55 105]
[ 60 65 125]
[ 70 75 145]]]
train_y:
[[ 40 45 85 50 55 105]
[ 50 55 105 60 65 125]
[ 60 65 125 70 75 145]
[ 70 75 145 80 85 165]
[ 80 85 165 90 95 185]]
train_X.shape:(5, 3, 3),trian_y.shape:(5, 6)
n_features: 3
n_output: 6
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1d_6 (Conv1D) (None, 2, 64) 448
_________________________________________________________________
max_pooling1d_6 (MaxPooling1 (None, 1, 64) 0
_________________________________________________________________
flatten_6 (Flatten) (None, 64) 0
_________________________________________________________________
dense_12 (Dense) (None, 50) 3250
_________________________________________________________________
dense_13 (Dense) (None, 6) 306
=================================================================
Total params: 4,004
Trainable params: 4,004
Non-trainable params: 0
_________________________________________________________________
None
yhat: [[ 90.29059 95.43707 185.55986 100.08475 105.629974 205.868 ]]
train_acc:0.9925143
train_loss:33.875467088381
总结
这两篇文章,通过简单地序列数据,使用以TF2.1为后端的Keras来搭建模型进行不同类别的序列预测任务,介绍了如何为一系列标准时间序列预测问题开发一套CNN模型。具体来说,主要包括:
- 如何开发用于单变量时间序列预测的CNN模型。
- 如何建立多元时间序列预测的CNN模型。
- 如何开发用于多步时间序列预测的CNN模型。
下一篇讲解LSTM处理时间序列预测问题。
