一、OushuDB AI简介
OushuDB可集成MADlib机器学习库作为其AI组件。现在OushuDB通过MADlib已经支持了大部分机器学习算法,正在研发一个新的组件以支持深度学习。OushuDB对MADlib进行了增强和优化,并在此基础上提出了AI-in-Database的概念。MADlib是Pivotal公司与伯克利大学合作开发的一个开源机器学习库,提供了多种数据转换、数据探索、统计、数据挖掘和机器学习方法,使用它能够简易地对结构化数据进行分析和挖掘。用户可以非常方便地将MADlib加载到数据库中,扩展数据库的分析功能。2015年7月MADlib成为Apache软件基金会的孵化器项目,经过两年的发展,于2017年8月毕业成为Apache顶级项目。其当前最新版本为MADlib 1.12,可以与PostgreSQL、Greenplum、HAWQ和OushuDB等数据库系统无缝集成。
1. 基本概念
无论是经典的SAS、SPSS,还是时下流行的MATLAB、R、Python,所有这些机器学习或数据挖掘软件,都是自成系统的。具体说就是具有一套完整的程序语言及其集成开发环境,提供了丰富的数学和统计分析函数,具备良好的人机交互界面,支持从数据准备、数据探索、数据预处理,到开发和实现模型算法、数据可视化,再到最终结果的验证与模型部署到应用的全过程。它们都是面向程序员的系统或语言,重点在于由程序员自己利用系统提供的基本计算方法或函数,通过编程的方式实现所需的模型算法。表1给出了5种常用数据挖掘工具在功能、特点、适用场景方面的比较,从中可以看出,每种工具都有自己的特点和适应条件。工具名称 |
功能 |
特点 |
适用场景 |
MATLAB |
不仅具有较强的数据统计、科学计算功能,还具有金融、经济等众多的行业应用工具箱 |
擅长矩阵计算和仿真模拟; 具有丰富的数学函数,适合算法开发或自主的程序开发; 具有强大的绘图功能 |
适合学习研究算法和灵活的产品开发 |
SAS |
功能强大的统计分析软件 |
具有较强的大数据处理能力; 支持二次开发 |
有一些行业标准,适合工业使用 |
SPSS |
侧重统计分析 |
使用方便,但不适合自己开发代码,就是说扩展上受限,如果要求不高,已经足够 |
界面友好,使用简单,但功能强大,也可以编程,能解决大部分统计学问题,适合初学者 |
WEKA |
具有丰富数据挖掘函数,包括分类、聚类、关联分析等主流算法 |
Java开发的开源数据分析、机器学习工具 |
适合于具有一定程序开发经验的工程师,尤其适合于用Java进行二次开发 |
R |
类似MATLAB,具有丰富的数学和统计分析函数 |
开源并支持二次开发 |
适合算法学习、小项目的产品研发 |
表1 常用数据挖掘工具的比较
对用户而言,MADlib仅提供了可在SQL查询语句中调用的函数。其中不但包括基本的线性代数运算和统计函数,而且还提供了常用的、现成的机器学习或数据挖掘模型函数。用户不需要深入了解算法的程序实现细节,只要搞清楚各函数中相关参数的含义,从而提供正确的入参,并且能够理解和解释函数的输出结果即可。这种使用方式无疑会极大地提高开发效率,节约开发成本。在MADlib的世界里,一切皆函数,就是这么简单。
然而任何事物都具有两面性,MADlib提供了使用方便性,但相对于其它数据挖掘系统而言,灵活性、扩展性与功能完备性显然是其短板。这很好理解,首先,模型已经被封装在SQL函数中,性能优劣完全依赖于函数本身,基本没有留给用户进行性能调整的空间。其次,函数只能在SQL中调用,而SQL依赖于数据库系统,也就是说单独的MADlib函数库是无意义的,它必须与PostgreSQL、Greenplum、HAWQ或OushuDB等数据库系统结合使用。最后,既然MADlib是SQL中的机器学习库,注定它不关心数据可视化,本身不带数据的图形化表示功能。由此可见,MADlib作为工具,并不是传统意义上的数据挖掘系统软件,而只是一套可在SQL中调用的函数库,其出发点是让数据库技术人员用SQL快速完成简单的数据挖掘工作。
即便如此,MADlib的易用性已经足以引起我们的兴趣。在了解了MADlib是什么及其优缺点后,用户就能根据自己的实际情况和需求,有针对性地选择和使用MADlib来实现特定业务目标。
2. 架构
MADlib架构如图1所示。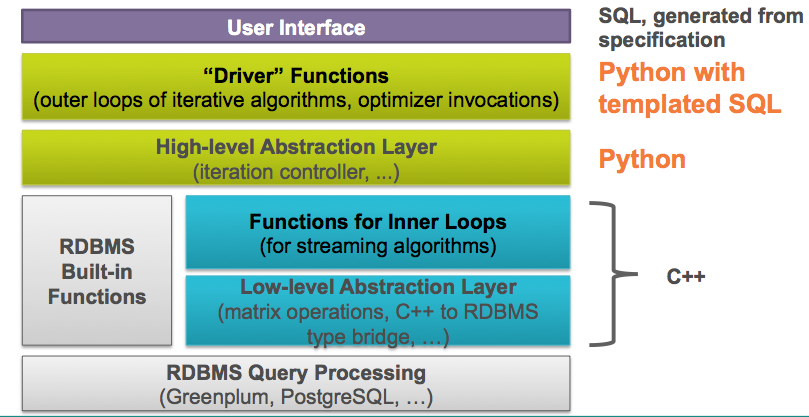
图1 MADlib架构
从图1中看到,MADlib系统架构自上至下由以下四个主要组件构成:
- Python调用SQL模板实现的驱动函数
- Python实现的高级抽象层
- C++实现的核心函数
- C++实现的低级数据库抽象层
驱动函数是用户输入的主入口点,调用优化器执行迭代算法的外层循环。
(2)Python实现的高级抽象层
高级抽象层负责算法的流程控制。与驱动函数一起实现输入参数验证、SQL语句执行、结果评估,并可能在循环中自动执行更多的SQL语句直到达到某些收敛标准。
(3)C++实现的核心函数
这部分函数是由C++编写的核心函数,在内层循环中实现特定机器学习或数据挖掘算法。出于性能考虑,这些函数使用C++而不是Python编写。
(4)C++实现的低级数据库抽象层
这些函数提供一个编程接口,将所有的Postgres数据库内核实现细节进行抽象。它们提供了一种机制,使得MADlib能够支持不同的后端平台,从而将关注点集中在内部功能而不是平台集成上。
3. 设计思想
驱动MADlib架构的主要设计思想与Hadoop是一致的,体现在以下方面:- 操作数据库内的本地数据,不在多个运行时环境中进行不必要的数据移动。
- 充分利用数据库引擎功能,但将数据挖掘逻辑从特定数据库的实现细节中分离出来。
- 利用MPP无共享技术提供的并行性和可扩展性,如Greenplum、HAWQ或OushuDB数据库系统。
- 执行的维护活动对Apache社区和正在进行的学术研究开放。
二、MADlib支持的模型类型
MADlib支持以下常用的数据挖掘与机器学习模型类型,其中大部分模型都包含训练和预测两组函数。(1)回归
如果所需的输出具有连续性,我们使用回归方法建立模型,预测输出值。例如,如果有真实的描述房地产属性的数据,我们就可以建立一个模型,预测基于房屋已知特征的售价。因为输出反应了连续的数值而不是分类,所以该场景是一个回归问题。
(2)分类
如果所需的输出实质上是分类的,可以使用分类方法建立模型,预测新数据会属于哪一类。分类的目标是能够将输入记录标记为正确的类别。例如,假设有描述人口统计的数据,以及个人申请贷款和贷款违约历史数据,那么我们就能建立一个模型,描述新的人口统计数据集合贷款违约的可能性。此场景下输出的分类为“违约”和“正常”两类。
(3)关联规则挖掘
有时又叫做购物篮分析或频繁项集挖掘。相对于随机发生,确定哪些事项更经常一起发生,指出事项之间的潜在关系。例如,在一个网店应用中,关联规则挖掘可用于确定哪些商品倾向于被一起售出,然后将这些商品输入到客户推荐引擎中,提供促销机会,就像著名的啤酒与尿布的故事。
(4)聚类
识别数据分组,一组中的数据项比其它组的数据项更相似。例如,在客户细分分析中,目标是识别客户行为相似特征组,以便针对不同特征的客户设计各种营销活动,以达到市场目的。如果提前了解客户细分情况,这将是一个受控的分类任务。当我们让数据识别自身分组时,这就是一个聚类任务。
(5)主题建模
主题建模与聚类相似,也是确定彼此相似的数据组。但这里的相似通常特指在文本领域中,具有相同主题的文档。
(6)描述性统计
描述性统计不提供模型,因此不被认为是一种机器学习方法。但描述性统计有助于向分析人员提供信息以了解基础数据,为数据提供有价值的解释,可能影响数据模型的选择。例如,计算数据集中每个变量内的数据分布,可以帮助分析理解哪些变量应被视为分类变量,哪些变量是连续性变量,以及值的分布情况。描述性统计通常是数据探索的组成部分。
(7)模型验证
如果不了解一个模型的准确性就开始使用它,很容易导致糟糕的结果。正因如此,理解模型存在的问题,并用测试数据评估模型的精度尤为重要。需要将训练数据和测试数据分离,频繁进行数据分析,验证统计模型的有效性,评估模型不过分拟合训练数据。N-fold交叉验证方法经常被使用。
三、MADlib的功能
MADlib的功能特色如图2所示。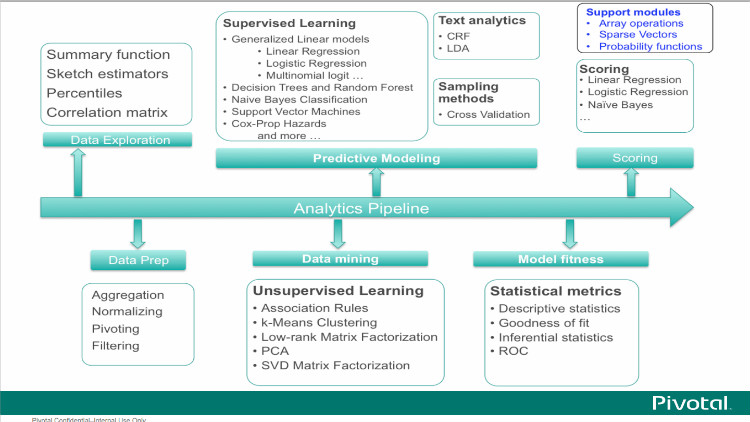
图2 MADlib功能
(1)Data Types andTransformations(数据类型与转换)
Arraysand Matrices(数组与矩阵)
ArrayOperations(数组运算)
MatrixOperations(矩阵运算)
MatrixFactorization(矩阵分解)
Low-rankMatrix Factorization(低阶矩阵分解)
SingularValue Decomposition(SVD,奇异值分解)
Normsand Distance functions(范数和距离函数)
SparseVectors(稀疏向量)
DimensionalityReduction(降维)
PrincipalComponent Analysis(PCA主成分分析)
PrincipalComponent Projection(PCP主成分投影)
Pivot(透视表)
EncodingCategorical Variables(分类变量编码)
Stemming(词干提取)
(2)Graph(图)
SingleSource Shortest Path(单源最短路径)
(3)Model Evaluation(模型评估)
CrossValidation(交叉验证)
PredictionMetrics(指标预测)
(4)Statistics(统计)
DescriptiveStatistics(描述性统计)
Pearson’s Correlation(皮尔逊相关系数)
Summary(摘要汇总)
InferentialStatistics(推断性统计)
HypothesisTests(假设检验)
ProbabilityFunctions(概率函数)
(5)Supervised Learning(监督学习)
ConditionalRandom Field(条件随机场)
RegressionModels(回归模型)
ClusteredVariance(聚类方差)
Cox-ProportionalHazards Regression(Cox比率风险回归)
ElasticNet Regularization(弹性网络回归)
GeneralizedLinear Models(广义线性回归)
LinearRegression(线性回归)
LogisticRegression(逻辑回归)
MarginalEffects(边际效应)
MultinomialRegression(多分类逻辑回归)
OrdinalRegression(有序回归)
RobustVariance(鲁棒方差)
SupportVector Machines(支持向量机)
TreeMethods(树方法)
DecisionTree(决策树)
RandomForest(随机森林)
(6)Time Series Analysis(时间序列分析)
ARIMA(自回归积分滑动平均)
(7)UnsupervisedLearning(无监督学习)
AssociationRules(关联规则)
AprioriAlgorithm(Apriori算法)
Clustering(聚类)
k-MeansClustering(k-Means)
TopicModelling(主题模型)
LatentDirichlet Allocation(LDA)
(8)Utility Functions(应用函数)
DeveloperDatabase Functions(开发者数据库函数)
LinearSolvers(线性求解器)
DenseLinear Systems(稠密线性系统)
SparseLinear Systems(稀疏线性系统)
PathFunctions(路径函数)
PMMLExport(PMML导出)
Sessionize(会话化)
TextAnalysis(文本分析)
TermFrequency(词频)
四、安装与卸载MADlib
在OushuDB中安装MADlib非常简单,下面简述在OushuDB 3.1.1上安装MADlib 1.11的过程。1. 下载软件包
从下面地址下载MADlib的rpm包:
http://yum.oushu-tech.com/oushurepo/yumrepo/release/ai/centos7/1.11.0/ai-1.11.0-652.el7.x86_64.rpm
2. 在OushuDB集群中的所有节点上安装MADlib rpm包
# 所有节点都执行 rpm - ivh ai-1.11.0-652.el7.x86_64.rpm
3. 在指定数据库中部署MADlib
su - gpadmin /usr/local/madlib/bin/madpack -p oushu -c gpadmin@localhost:5432/dm install该命令在OushuDB的dm数据库中建立madlib schema,-p参数指定平台为oushu。命令执行后可以查看在madlib schema中创建的数据库对象。
dm=# set search_path=madlib;
SET
dm=# \dt
List of relations
Schema | Name | Type | Owner | Storage
--------+------------------+-------+---------+-------------
madlib | migrationhistory | table | gpadmin | append only
(1 row)
dm=# \ds
List of relations
Schema | Name | Type | Owner | Storage
--------+-------------------------+----------+---------+---------
madlib | migrationhistory_id_seq | sequence | gpadmin | heap
(1 row)
dm=# select type,count(*)
dm-# from (select p.proname as name,
dm(# case when p.proisagg then 'agg'
dm(# when p.prorettype = 'pg_catalog.trigger'::pg_catalog.regtype then 'trigger'
dm(# else 'normal'
dm(# end as type
dm(# from pg_catalog.pg_proc p, pg_catalog.pg_namespace n
dm(# where n.oid = p.pronamespace and n.nspname='madlib') t
dm-# group by rollup (type);
type | count
--------+-------
agg | 135
normal | 1335
| 1470
(3 rows) 可以看到,MADlib部署应用程序madpack首先创建数据库模式madlib,然后在该模式中创建数据库对象,1.11版本包括一个表,一个序列,1335个普通函数,135个聚合函数。所有的机器学习和数据挖掘模型、算法、操作和功能都是通过调用这些函数实际执行的。
4. 验证安装
/usr/local/madlib/bin/madpack install-check -c /dm -s madlib -p oushu该命令通过执行27个模块的68个案例,验证所有模块都能正常工作。相同配置的集群下,该检查过程比HAWQ 2.1.1上的MADlib 1.10快了将近一倍。命令输出如下:
[gpadmin@hdp2~]$/usr/local/madlib/bin/madpack install-check -c /dm -s madlib -p oushu madpack.py : INFO : Detected OUSHU version 3.1. TEST CASE RESULT|Module: array_ops|array_ops.sql_in|PASS|Time: 7732 milliseconds TEST CASE RESULT|Module: bayes|gaussian_naive_bayes.sql_in|PASS|Time: 11219 milliseconds TEST CASE RESULT|Module: bayes|bayes.sql_in|PASS|Time: 33970 milliseconds TEST CASE RESULT|Module: crf|crf_train_small.sql_in|PASS|Time: 11005 milliseconds TEST CASE RESULT|Module: crf|crf_train_large.sql_in|PASS|Time: 13705 milliseconds TEST CASE RESULT|Module: crf|crf_test_small.sql_in|PASS|Time: 9771 milliseconds TEST CASE RESULT|Module: crf|crf_test_large.sql_in|PASS|Time: 10714 milliseconds TEST CASE RESULT|Module: elastic_net|elastic_net_install_check.sql_in|PASS|Time: 481479 milliseconds TEST CASE RESULT|Module: graph|sssp.sql_in|PASS|Time: 31614 milliseconds TEST CASE RESULT|Module: graph|pagerank.sql_in|PASS|Time: 27443 milliseconds TEST CASE RESULT|Module: linalg|svd.sql_in|PASS|Time: 35420 milliseconds TEST CASE RESULT|Module: linalg|matrix_ops.sql_in|PASS|Time: 16492 milliseconds TEST CASE RESULT|Module: linalg|linalg.sql_in|PASS|Time: 1217 milliseconds TEST CASE RESULT|Module: prob|prob.sql_in|PASS|Time: 990 milliseconds TEST CASE RESULT|Module: sketch|support.sql_in|PASS|Time: 118 milliseconds TEST CASE RESULT|Module: sketch|mfv.sql_in|PASS|Time: 248 milliseconds TEST CASE RESULT|Module: sketch|fm.sql_in|PASS|Time: 4441 milliseconds TEST CASE RESULT|Module: sketch|cm.sql_in|PASS|Time: 14443 milliseconds TEST CASE RESULT|Module: svm|svm.sql_in|PASS|Time: 82863 milliseconds TEST CASE RESULT|Module: tsa|arima_train.sql_in|PASS|Time: 27969 milliseconds TEST CASE RESULT|Module: tsa|arima.sql_in|PASS|Time: 30725 milliseconds TEST CASE RESULT|Module: conjugate_gradient|conj_grad.sql_in|PASS|Time: 3450 milliseconds TEST CASE RESULT|Module: knn|knn.sql_in|PASS|Time: 3986 milliseconds TEST CASE RESULT|Module: lda|lda.sql_in|PASS|Time: 12444 milliseconds TEST CASE RESULT|Module: stats|wsr_test.sql_in|PASS|Time: 2426 milliseconds TEST CASE RESULT|Module: stats|t_test.sql_in|PASS|Time: 1873 milliseconds TEST CASE RESULT|Module: stats|robust_and_clustered_variance_coxph.sql_in|PASS|Time: 9217 milliseconds TEST CASE RESULT|Module: stats|pred_metrics.sql_in|PASS|Time: 11266 milliseconds TEST CASE RESULT|Module: stats|mw_test.sql_in|PASS|Time: 1169 milliseconds TEST CASE RESULT|Module: stats|ks_test.sql_in|PASS|Time: 1274 milliseconds TEST CASE RESULT|Module: stats|f_test.sql_in|PASS|Time: 1355 milliseconds TEST CASE RESULT|Module: stats|cox_prop_hazards.sql_in|PASS|Time: 18102 milliseconds TEST CASE RESULT|Module: stats|correlation.sql_in|PASS|Time: 7285 milliseconds TEST CASE RESULT|Module: stats|chi2_test.sql_in|PASS|Time: 1714 milliseconds TEST CASE RESULT|Module: stats|anova_test.sql_in|PASS|Time: 873 milliseconds TEST CASE RESULT|Module: svec_util|svec_test.sql_in|PASS|Time: 5192 milliseconds TEST CASE RESULT|Module: svec_util|gp_sfv_sort_order.sql_in|PASS|Time: 1421 milliseconds TEST CASE RESULT|Module: utilities|text_utilities.sql_in|PASS|Time: 2428 milliseconds TEST CASE RESULT|Module: utilities|sessionize.sql_in|PASS|Time: 1920 milliseconds TEST CASE RESULT|Module: utilities|pivot.sql_in|PASS|Time: 8198 milliseconds TEST CASE RESULT|Module: utilities|path.sql_in|PASS|Time: 4032 milliseconds TEST CASE RESULT|Module: utilities|encode_categorical.sql_in|PASS|Time: 3786 milliseconds TEST CASE RESULT|Module: utilities|drop_madlib_temp.sql_in|PASS|Time: 260 milliseconds TEST CASE RESULT|Module: assoc_rules|assoc_rules.sql_in|PASS|Time: 16333 milliseconds TEST CASE RESULT|Module: convex|lmf.sql_in|PASS|Time: 25161 milliseconds TEST CASE RESULT|Module: glm|poisson.sql_in|PASS|Time: 10049 milliseconds TEST CASE RESULT|Module: glm|ordinal.sql_in|PASS|Time: 8566 milliseconds TEST CASE RESULT|Module: glm|multinom.sql_in|PASS|Time: 8400 milliseconds TEST CASE RESULT|Module: glm|inverse_gaussian.sql_in|PASS|Time: 9039 milliseconds TEST CASE RESULT|Module: glm|gaussian.sql_in|PASS|Time: 9369 milliseconds TEST CASE RESULT|Module: glm|gamma.sql_in|PASS|Time: 55457 milliseconds TEST CASE RESULT|Module: glm|binomial.sql_in|PASS|Time: 15706 milliseconds TEST CASE RESULT|Module: linear_systems|sparse_linear_sytems.sql_in|PASS|Time: 3093 milliseconds TEST CASE RESULT|Module: linear_systems|dense_linear_sytems.sql_in|PASS|Time: 2671 milliseconds TEST CASE RESULT|Module: recursive_partitioning|random_forest.sql_in|PASS|Time: 201184 milliseconds TEST CASE RESULT|Module: recursive_partitioning|decision_tree.sql_in|PASS|Time: 43634 milliseconds TEST CASE RESULT|Module: regress|robust.sql_in|PASS|Time: 32059 milliseconds TEST CASE RESULT|Module: regress|multilogistic.sql_in|PASS|Time: 11548 milliseconds TEST CASE RESULT|Module: regress|marginal.sql_in|PASS|Time: 44736 milliseconds TEST CASE RESULT|Module: regress|logistic.sql_in|PASS|Time: 31461 milliseconds TEST CASE RESULT|Module: regress|linear.sql_in|PASS|Time: 4470 milliseconds TEST CASE RESULT|Module: regress|clustered.sql_in|PASS|Time: 17934 milliseconds TEST CASE RESULT|Module: sample|sample.sql_in|PASS|Time: 520 milliseconds TEST CASE RESULT|Module: summary|summary.sql_in|PASS|Time: 7028 milliseconds TEST CASE RESULT|Module: kmeans|kmeans.sql_in|PASS|Time: 37665 milliseconds TEST CASE RESULT|Module: pca|pca_project.sql_in|PASS|Time: 108473 milliseconds TEST CASE RESULT|Module: pca|pca.sql_in|PASS|Time: 254640 milliseconds TEST CASE RESULT|Module: validation|cross_validation.sql_in|PASS|Time: 17556 milliseconds [gpadmin@hdp2~]$可以看到,所有案例都已经正常执行,说明MADlib安装成功。
5. 卸载MADlib
卸载过程基本上是安装的逆过程。(1)删除madlib模式
使用SQL命令手工删除模式。
drop schema madlib cascade;(2)删除其它遗留数据库对象
- 删除模式:如果模型验证过程中途出错,数据库中可能包含测试的模式,这些模式名称的前缀都是madlib_installcheck_,只能手工执行SQL命令删除这些模式,如:
drop schema madlib_installcheck_kmeans cascade;
- 删除用户:如果存在遗留的测试用户,则删除它,如:
drop user if existsmadlib_111_installcheck;