前言
在SLR分析的最后,介绍了SLR依然可能存在语法冲突。为什么呢?
原因:SLR只是简单地考察下一个输入符号b是否属于与归约项目A→α相关联的FOLLOW(A),但b∈FOLLOW(A)只是归约α的一个必要条件,而非充分条件
海轰的理解:如果输入下一个字符是b,我们采用了归约操作,那么就一定可以说明b属于A的FOLLOW集。但是我们不能说:如果b属于A的FOLLOW集,那么就一定可以对A采用归约操作。不好理解的小伙伴可以参考下面的具体实例:

从上图右边生成树可以我们得知,此时 L=R 中的R后面跟着的终结符只能是$,不可能是=,但是R的FOLLOW中却包含了=。又比如说下一行中的 * R,R下一个终结符只可以是=,不会是 $ 。所以只凭FOLLOW集合判断是否采用归约是不合适。【如果使用FOLLOW 相当于归约的条件放宽了】所以,引入了LR(1)分析,用来解决这种问题。
LR(1)项目
在LR(0)分析的时候,我们引入了LR(0)项目【传送门】。其实简单说来就是通过一个小圆点标记字符状态(圆点前字符表示已经读入,圆点后表示未读入)。但是在LR(0)分析的时候,我们并没有考虑下一个输入的字符。而对于LR(1),我们就需要对每一个项目多考虑一项:下一个输入字符(也就是:展望符)
LR(1)项目定义:将一般形式为 [A→α·β, a]的项称为 LR(1) 项,其中A→αβ 是一个产生式,a 是一个终结符(这里将$视为一个特殊的终结符)它表示在当前状态下,A后面必须紧跟的终结符,称为该项的展望符(lookahead)
- LR(1) 中的1指的是项的第二个分量的长度,也就是:往后多看一个字符
- 在形如[A→α·β, a]且β ≠ ε的项中,展望符a没有任何作用(β中可能含有其他的终结符)
- 但是一个形如[A→α·, a]的项在只有在下一个输入符号等于a时才可以按照A→α 进行归约:这样的a的集合总是FOLLOW(A)的子集,而且它通常是一个真子集
LR(1)自动机
举例说明,文法如下:

步骤一:分析是否需要使用增广文法,确保最终接收状态只有一个
步骤二:写出FOLLOW集(可以全写 也可以不用 部分也行)
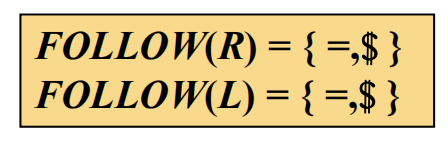
步骤三:分析初始状态,再根据下个可能输入的符号分析出之后的状态(类似LR(0)分析)

解释:

由0)可以推导出1式【0):左边橙色框中的式子 1:右边蓝色框中的式子】,有1式中的S是非终结符,所以又可以继续推出等价项目2和3。又2式中圆点后面的L属于非终结符,继续推出4、5式【注意:4、5中的展望符是=,因为2式中L后面有终结符=】然后继续对左边橙色框中的式子进行相同算法的推导即可。
最终:
注1:同一个项目中,若两个或多个式子,只是展望符不同,其他都一样,那么是可以写在一起的,就把展望符合在一起写即可
注2:如果除展望符外,两个LR(1)项目集是相同的,则称这两个LR(1)项目集是同心的

该文法的LR(1)分析表如下:
注:分析表构造方法总体与LR(0)分析表类似。只是在归约的时候,比如对于例子中的I5状态,只有下个输入符为 =/$ 时,才会进行归约。

LR分析表构造算法

LR(1)文法
定义:如果LR(1)分析表中没有语法分析动作冲突,那么给定的文法就称为LR(1)文法
