以下内容为本人原创,欢迎大家观看学习,禁止用于商业用途,转载请说明出处,谢谢合作!
大噶好!我是python练习时长一个月的Yhen.很高兴能在这里和大家分享我的学习经验。今天要分享给大家的一个内容是爬取知乎大佬“张佳玮”的文章,并将它们保存到本地。会把源码提供给大家,因为比较详细,老规矩,如果只想知道结果的同学,可以直接去看源码。下面的文章我会先告诉大家正确的做法流程是什么。在文章结尾我会分享我自己爬的过程中出现过的问题以及解决方法作为彩蛋。毕竟爬虫的过程也不是一帆风顺的哈哈哈。
我感觉这篇文章代码还是很简单的,重点是如何找到接口,所以个人觉得这份彩蛋还是比较有价值的,大家有耐心的话可以去看看!我是花了很大的心血去写的,如果能真正给大家带来价值,我也会觉得很开心,头发没白掉哈哈哈
好啦,准备好了么,走起!
今天我们要爬取知乎大佬的文章
怎么爬呢?
来跟着我的步骤走,看仔细了,别走错了哦
找错接口,满盘皆输哦
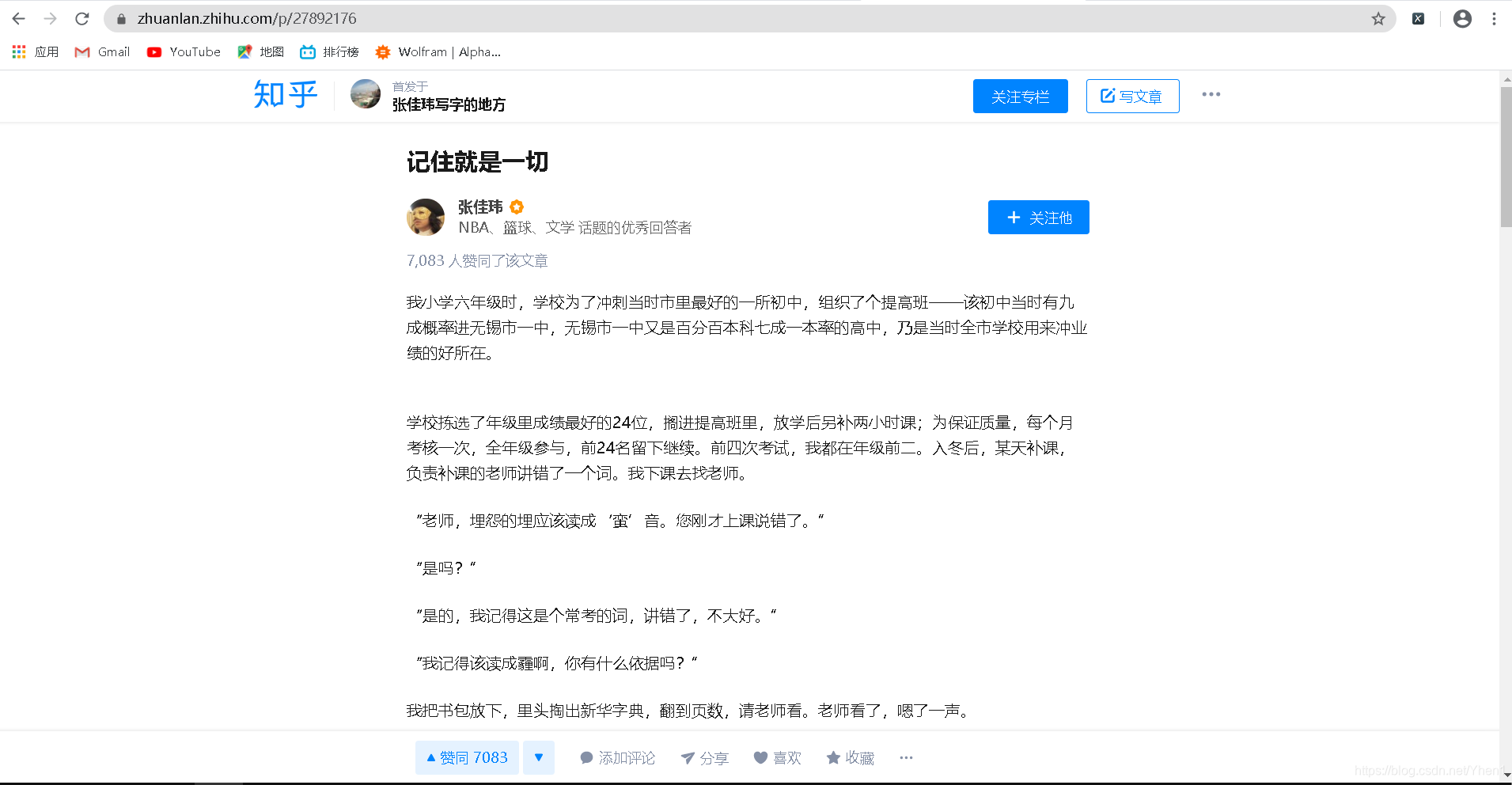
首先,在知乎首页搜索“张佳玮”
然后点击第一个结果
进入张佳玮个人页面后
按F12,然后点击“文章”
如图
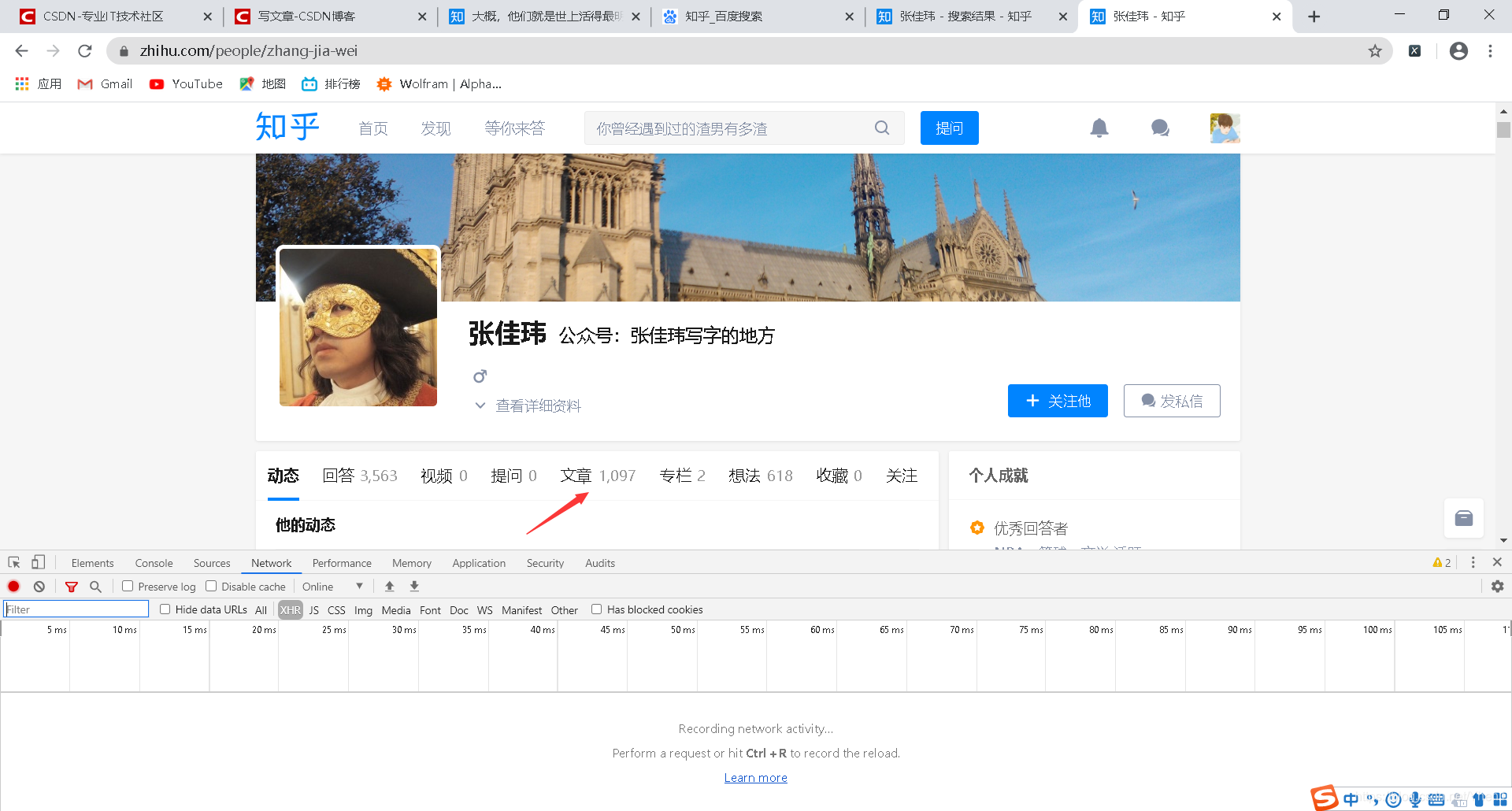
此时下面控制台会给我们返回一些数据
然后这里重点来了,错了一步可能都得不到我们想要的数据啦
(经验之谈,后面的彩蛋会和大家分享我尝试过的结果和最后是怎么找到我们想要的接口的,有兴趣的同学可以去看看)
我们要点击上方这个像“禁止”符号的按钮,把这些数据清空
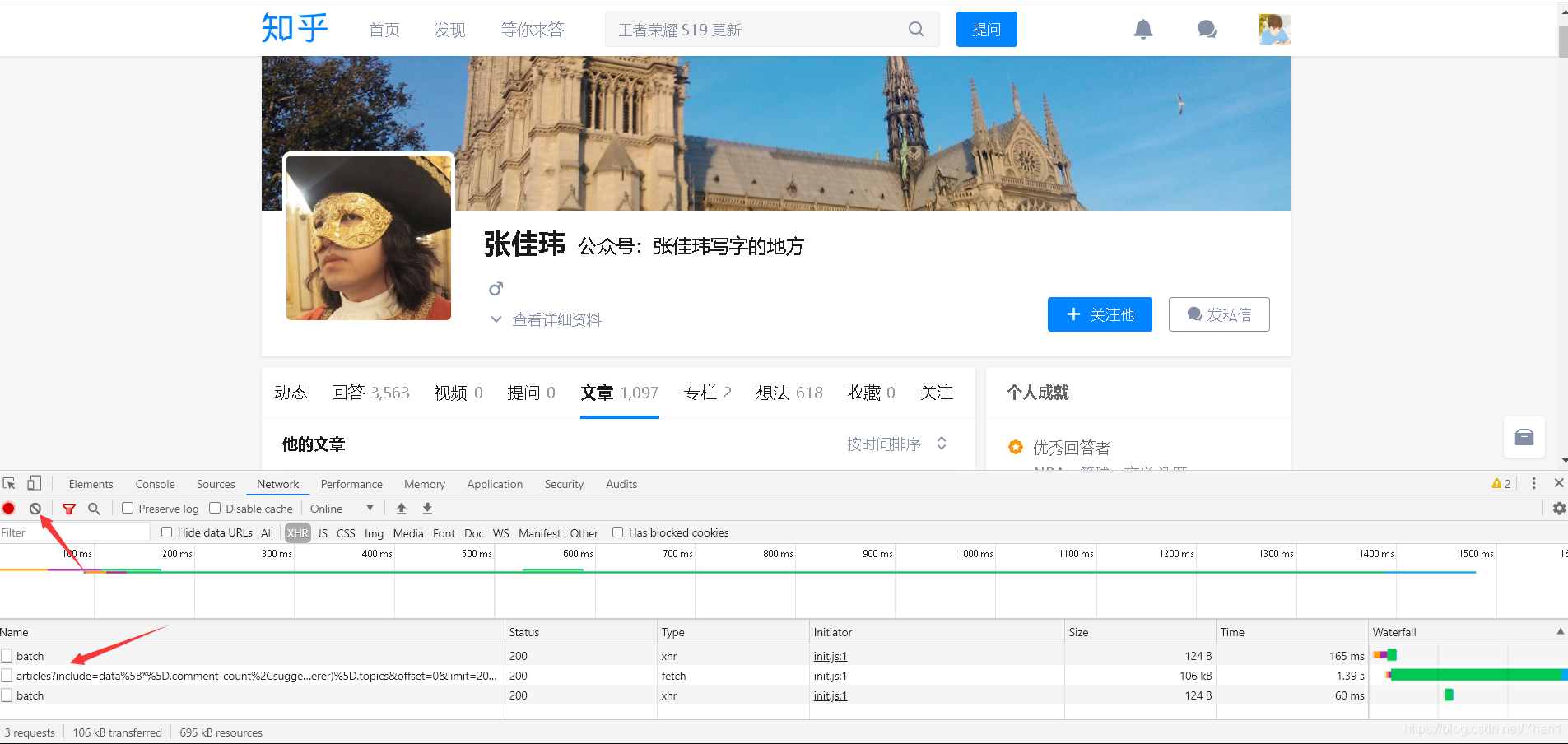
然后把排序方式改为按点赞量排序

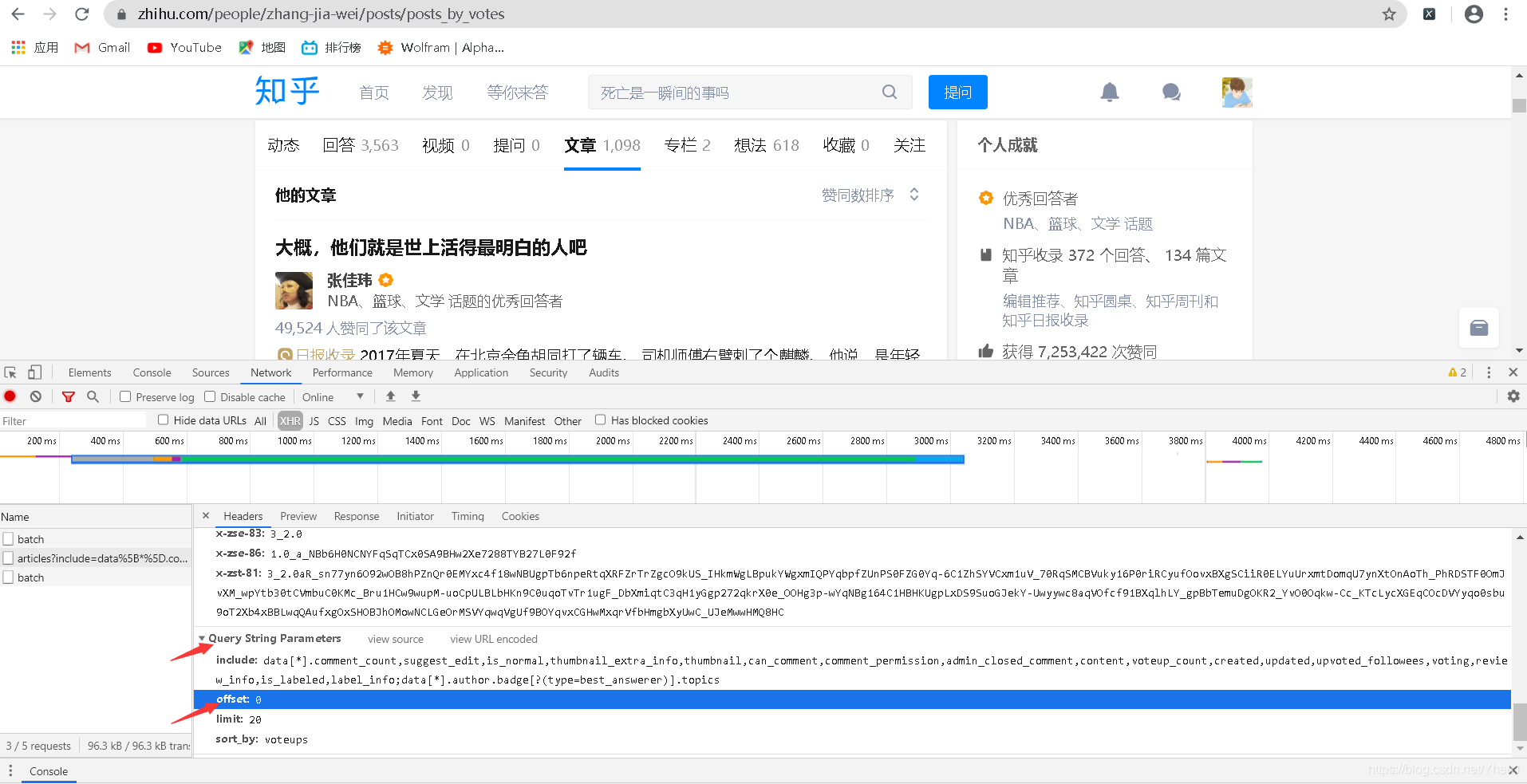
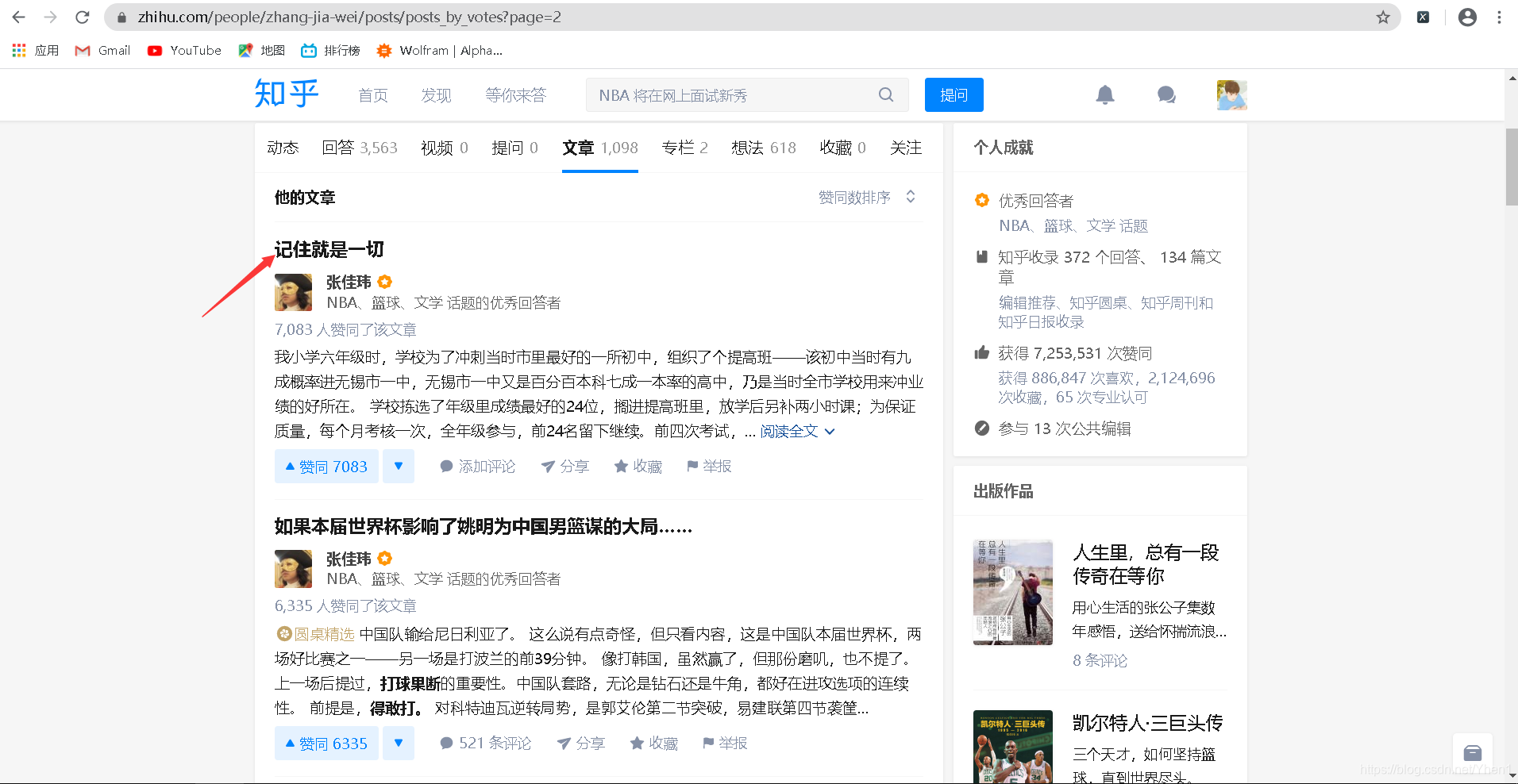
然后得到了3个数据接口
然后我们点击有article这个接口

然后我们按箭头从上到下的顺序依次点击
最后我们可以得到一个title,里面对应的“大概,他们就是世上活得最明白的人吧”
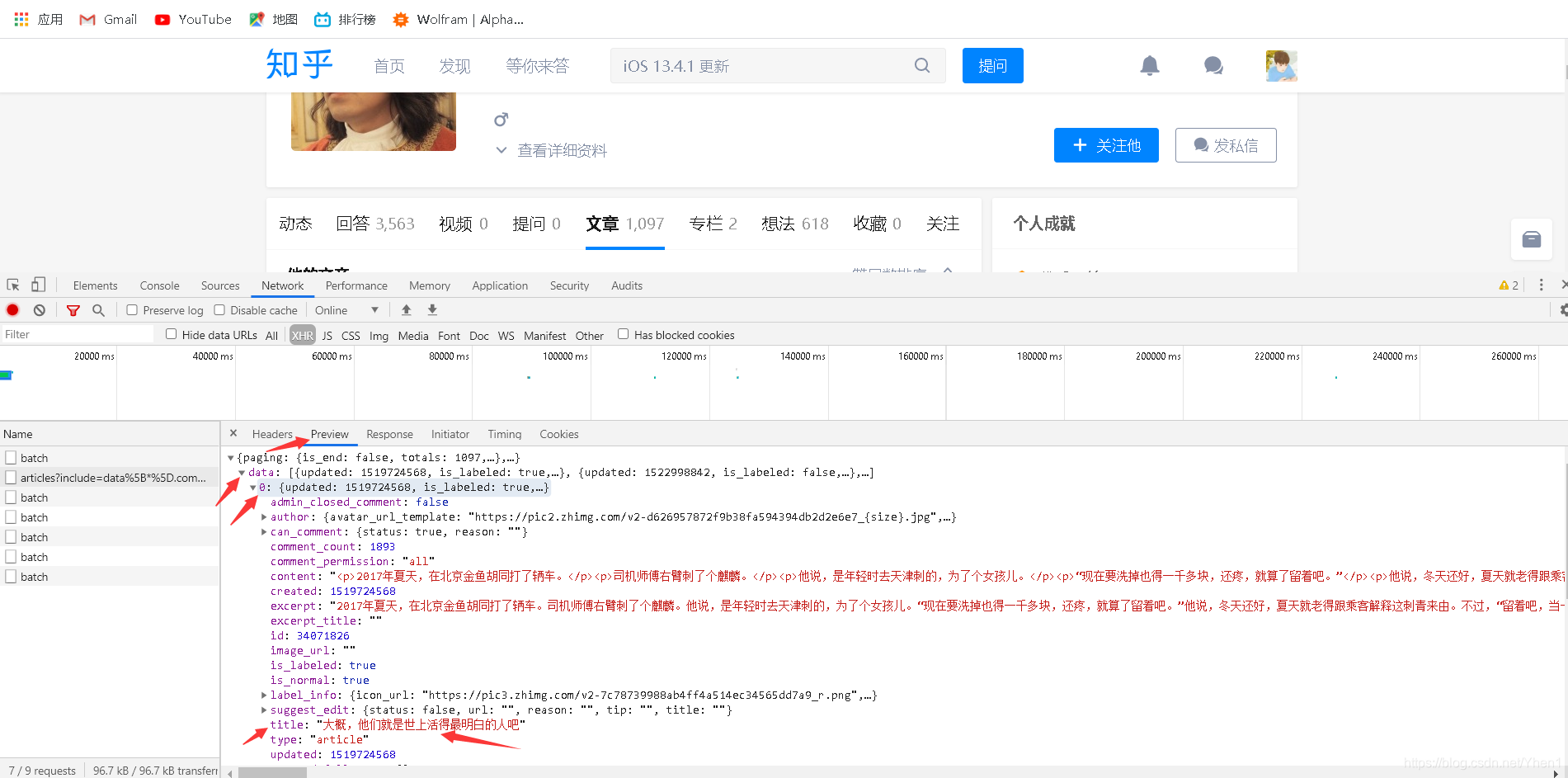
对应着的是第一篇文章的标题
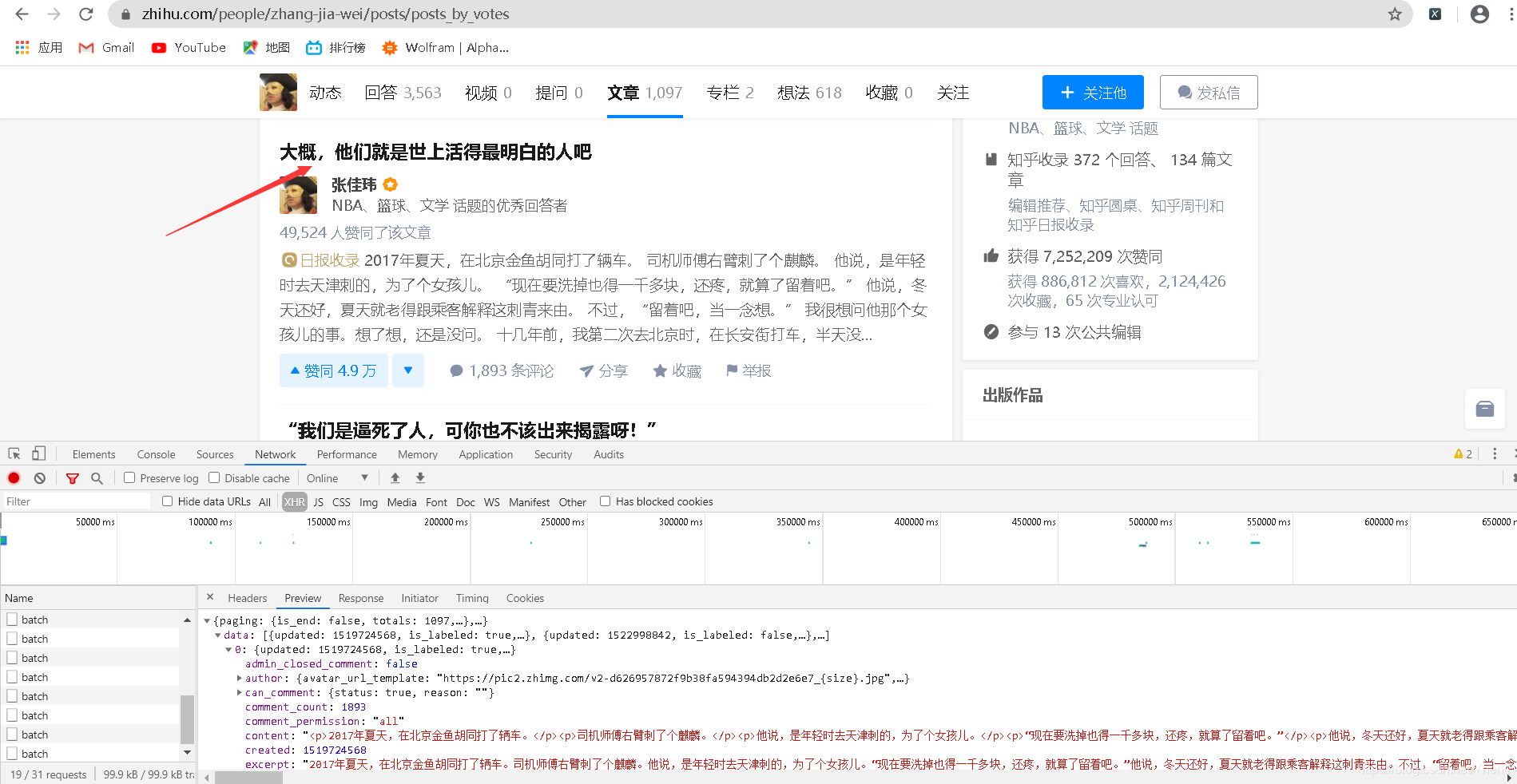
如果你觉得这只是巧合
那我们打开最后一个数据再比较下
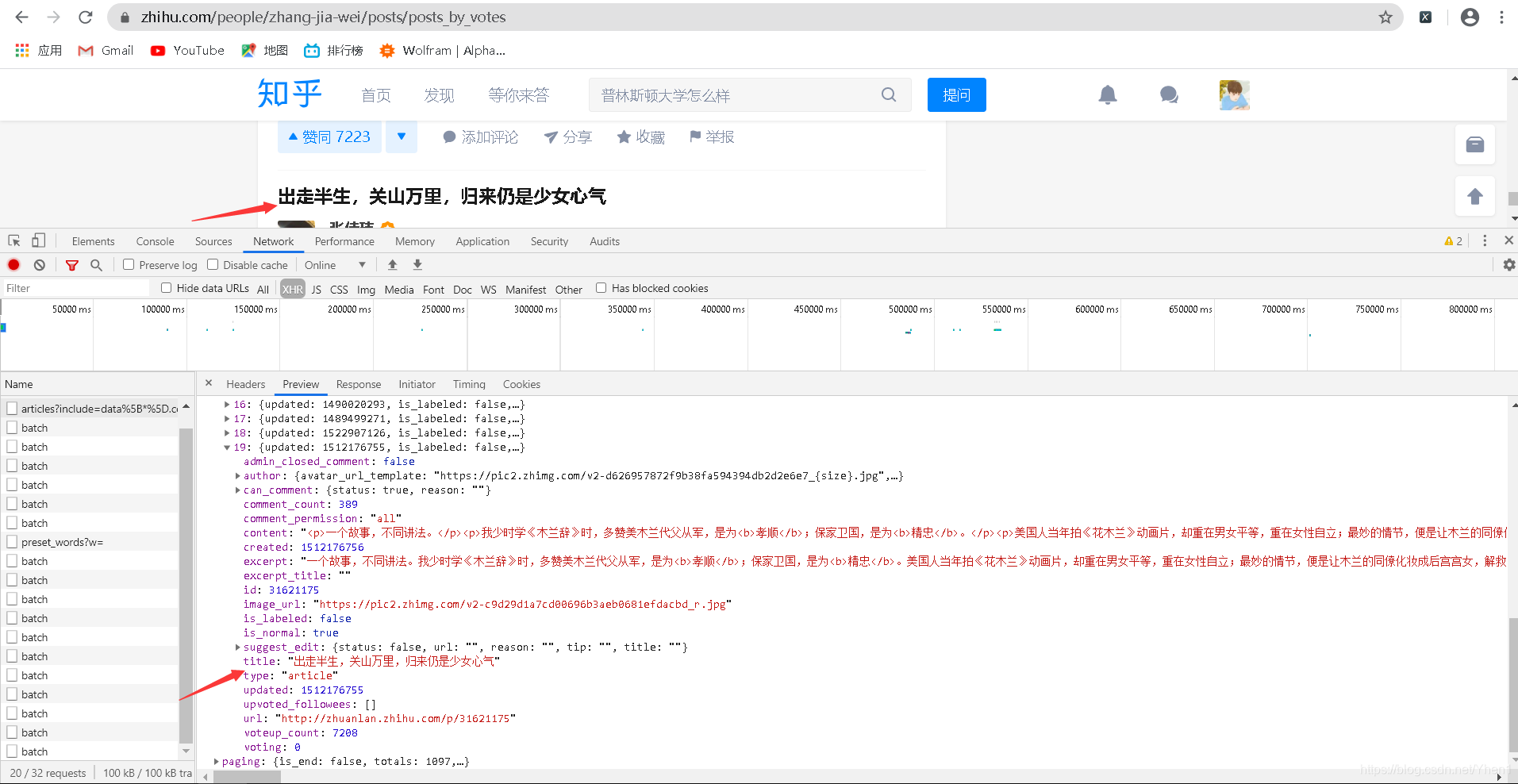
怎么样?信了吧哈哈哈
那么看来我们就可以从这个接口入手,来获取我们的一个数据啦。
在这里可能有同学会问,那要获取这些数据我直接像我上一篇博客爬千千小说一样,直接定位到网页元素,然后用xpath提取不就好了吗?何必这么麻烦呢!!!
哈哈哈你们想到的方法我都想过用过。结果当然是失败了,至于为什么失败了?我会在彩蛋写到,有兴趣的同学可以去看看!
好了,知道了从哪里入手,我们现在来分析下思路
方向分析一波
我们的目标是要获取里面的文章
所以我们首先要从刚刚的接口中提取到文章详情页的标题名(就是刚刚的title)和网址。
然后对网址进行请求
再提取网址中的文章内容
最后把文章的标题名和文章内容对应起来并保存到本地
OK,有了思路了,开始敲代码叭!
开始就是基本操作,导requests包,然后发送请求
oh,对了这里大家注意一下,就是我们要发送请求的网址是下图这个哦
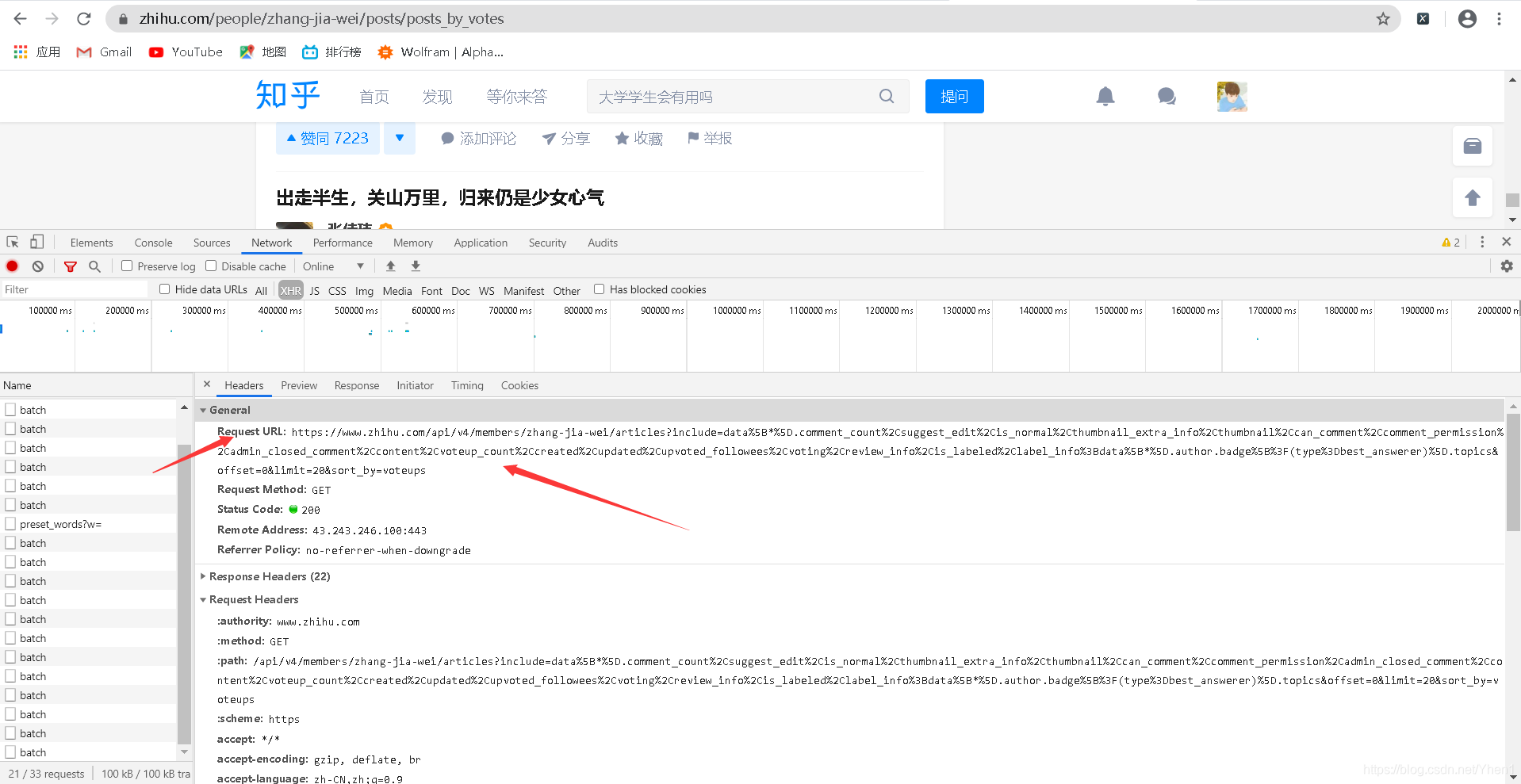
千万千万不要写成写成上方网址栏那个了,不然我们做了这么多前期准备工作就白费了啦
import requests
from pyquery import PyQuery as pq
# 张佳玮文章页面的网址
url = 'https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?include=data%5B*%5D.comment_count%2Csuggest_edit%2Cis_normal%2Cthumbnail_extra_info%2Cthumbnail%2Ccan_comment%2Ccomment_permission%2Cadmin_closed_comment%2Ccontent%2Cvoteup_count%2Ccreated%2Cupdated%2Cupvoted_followees%2Cvoting%2Creview_info%2Cis_labeled%2Clabel_info%3Bdata%5B*%5D.author.badge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20&sort_by=voteups'
# 添加请求头 浏览器类型
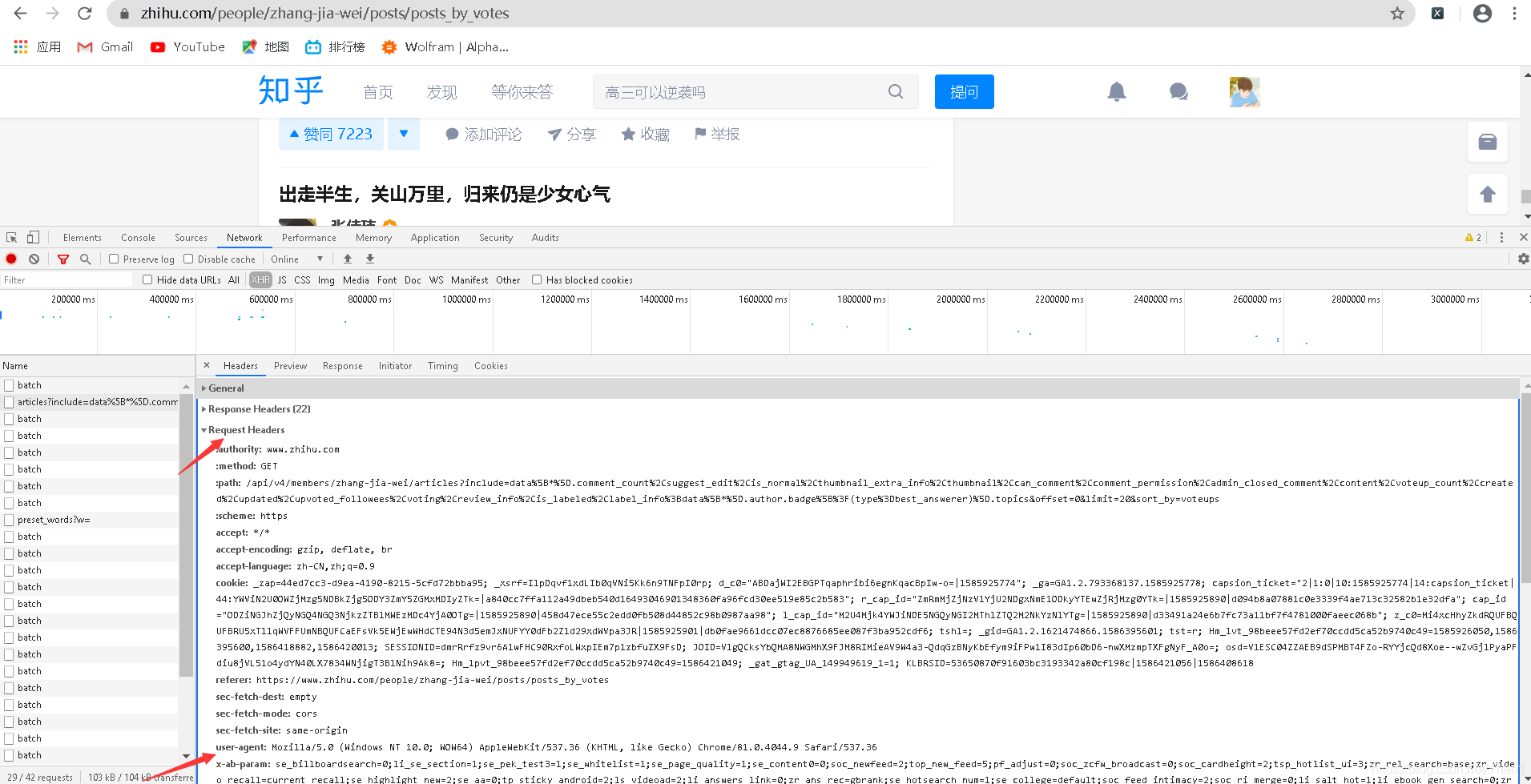
headers ={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36'}
# 加上请求头对网址进行请求
response = requests.get(url,headers=headers).json()
这里注意一下,就是知乎有反爬机制,所以要在请求的时候加上一个浏览器信息的请求头,避免网站知道我们是爬虫在访问
因为这里接口里面的是json数据,所以我们加个.json(),这样我们的python也能够处理这种数据啦。记得不要忘了json后面的括号哦,不然下面的操作会报错
浏览器类型在这里看
我们来分析下这个json数据的结构
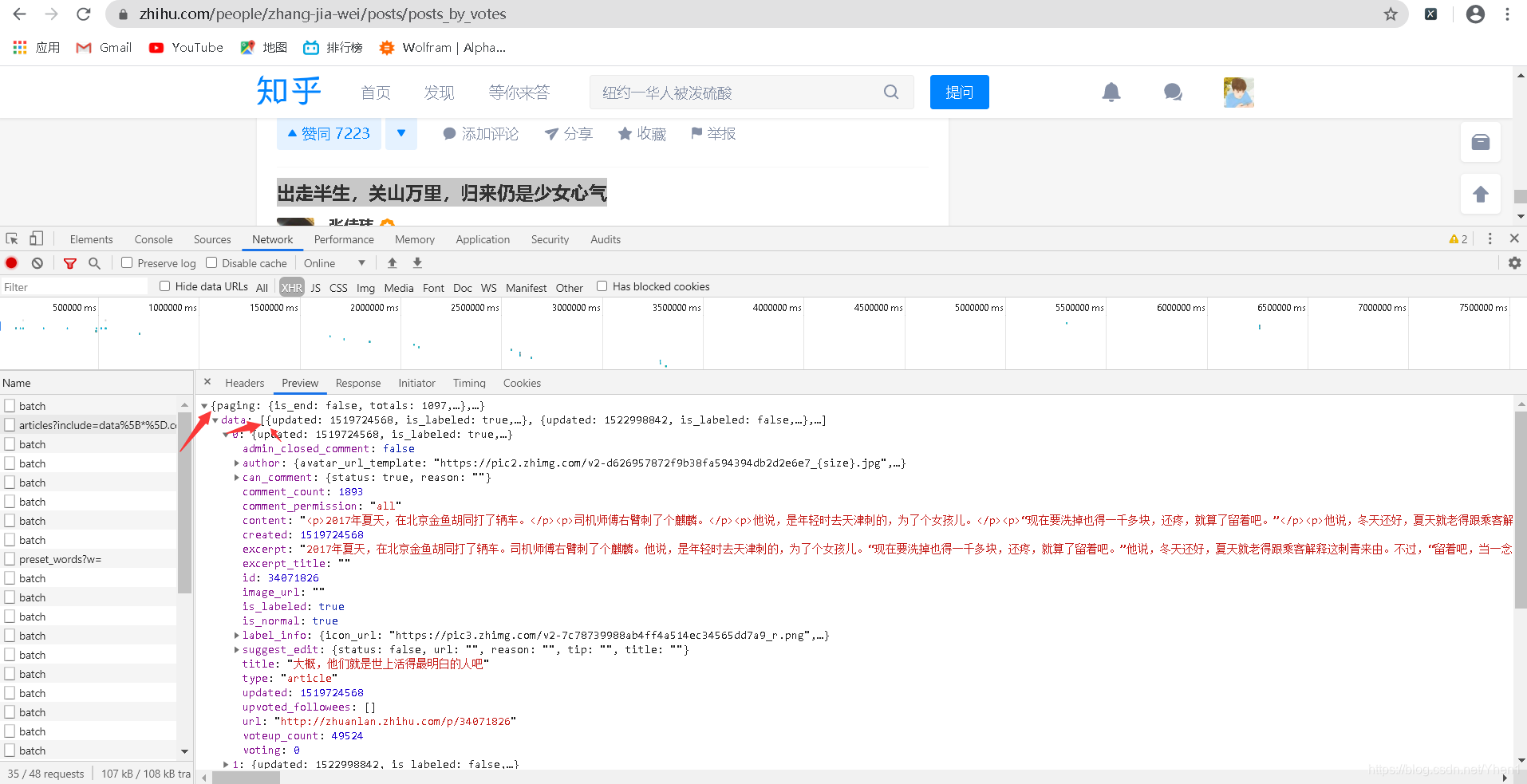
最外层是一个大括号,data里面是一个中括号一个括号
说明这是字典–列表–字典
首先我们用字典提取的方法把data的数据取出来
因为得到的数据是一个列表,所以用for遍历提取
新建一个空字典
遍历后得到的数据是一个字典,取出字典中以title为键对应的数 据得到文章的标题,并把数据装进新建的字典里
取出字典中以url为键对应的数据,得到文章的网址,并把数据装 进新建的字典里。
# 取出字典中以data为键对应的数据
data =response["data"]
# 因为得到的数据是一个列表,所以用for遍历提取
for x in data:
# 新建一个空字典
dict={}
# 遍历后得到的数据是一个字典,取出字典中以title为键对应的数据,得到文章的标题,并把数据装进新建的字典里
dict["title"]=x["title"]
# 取出字典中以url为键对应的数据,得到文章的网址,并把数据装进新建的字典里
dict["url"]= x["url"]
我们打印下结果看看
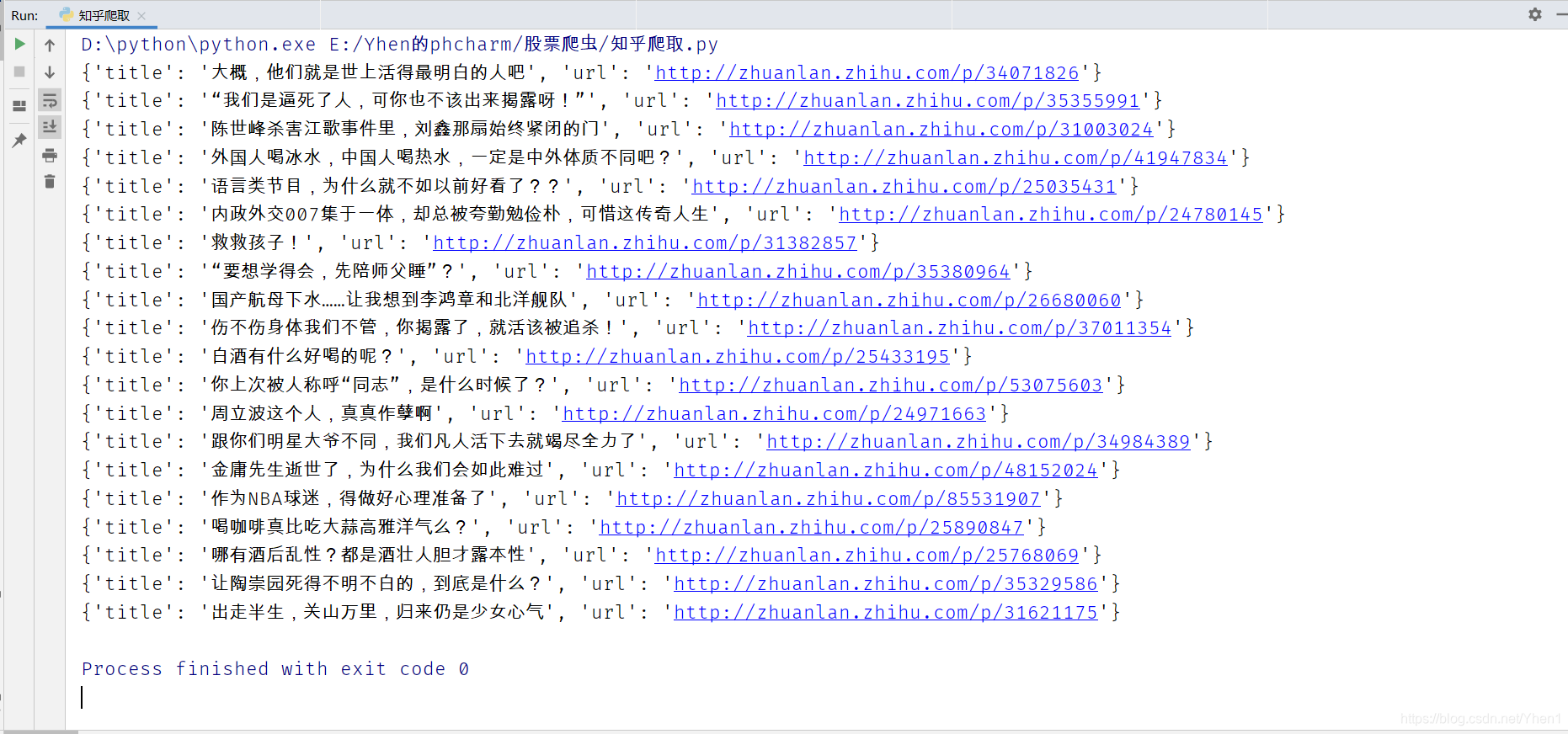
很nice,我们想要的都有了,而且也对应起来了
接下来是对网址发送请求
# 对文章网址进行请求
res =requests.get(dict["url"]).text
print(res)
看看结果
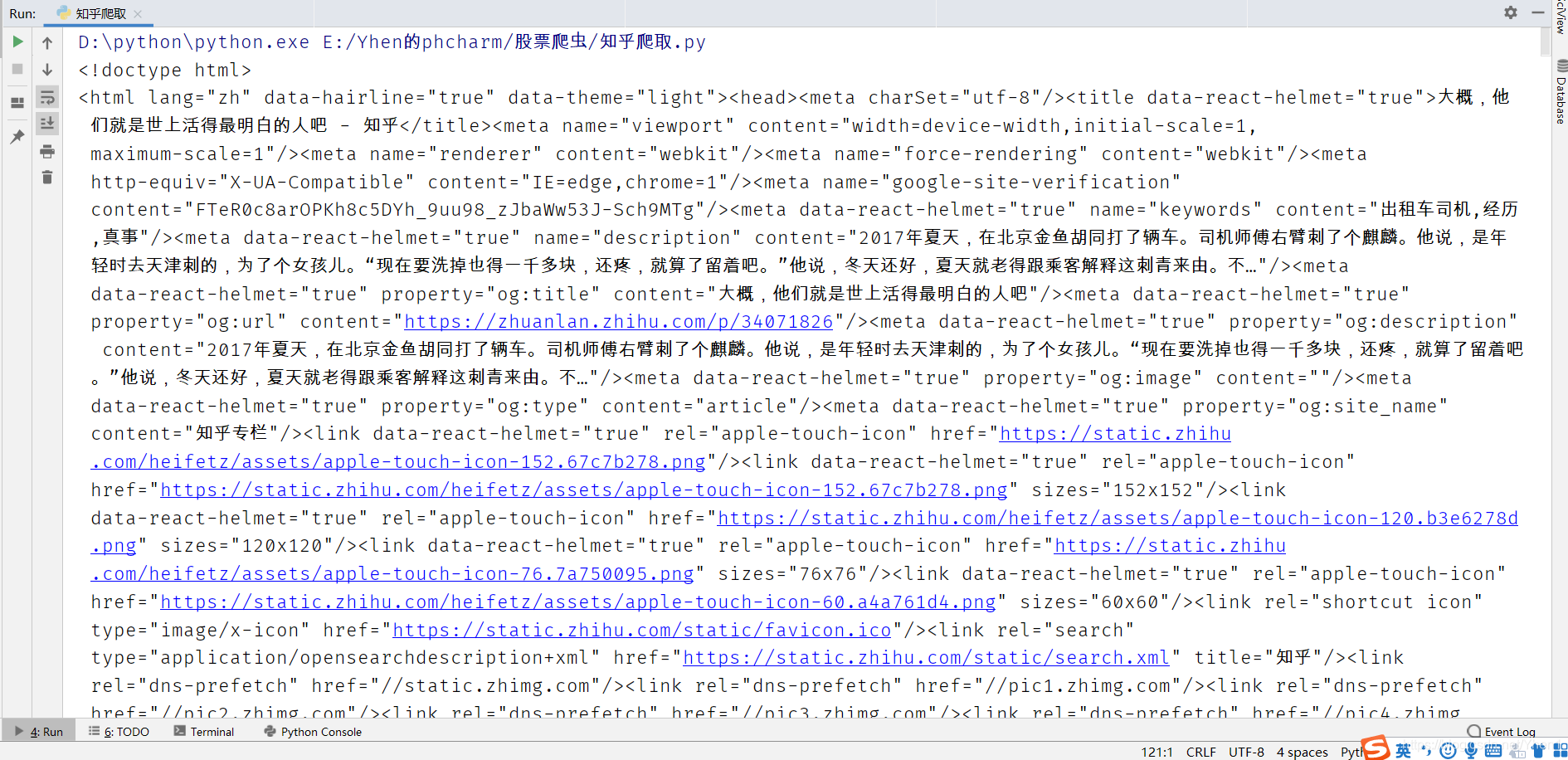
成功得到数据,说明请求成功了
好了,下面就是剩下抓取文章内容和保存到本地了
上一篇爬小说的时候向大家介绍了xpath
我们今天不用它了
向大家一种更加简单的数据提取方式:pyquery
我们先来分析下页面的数据
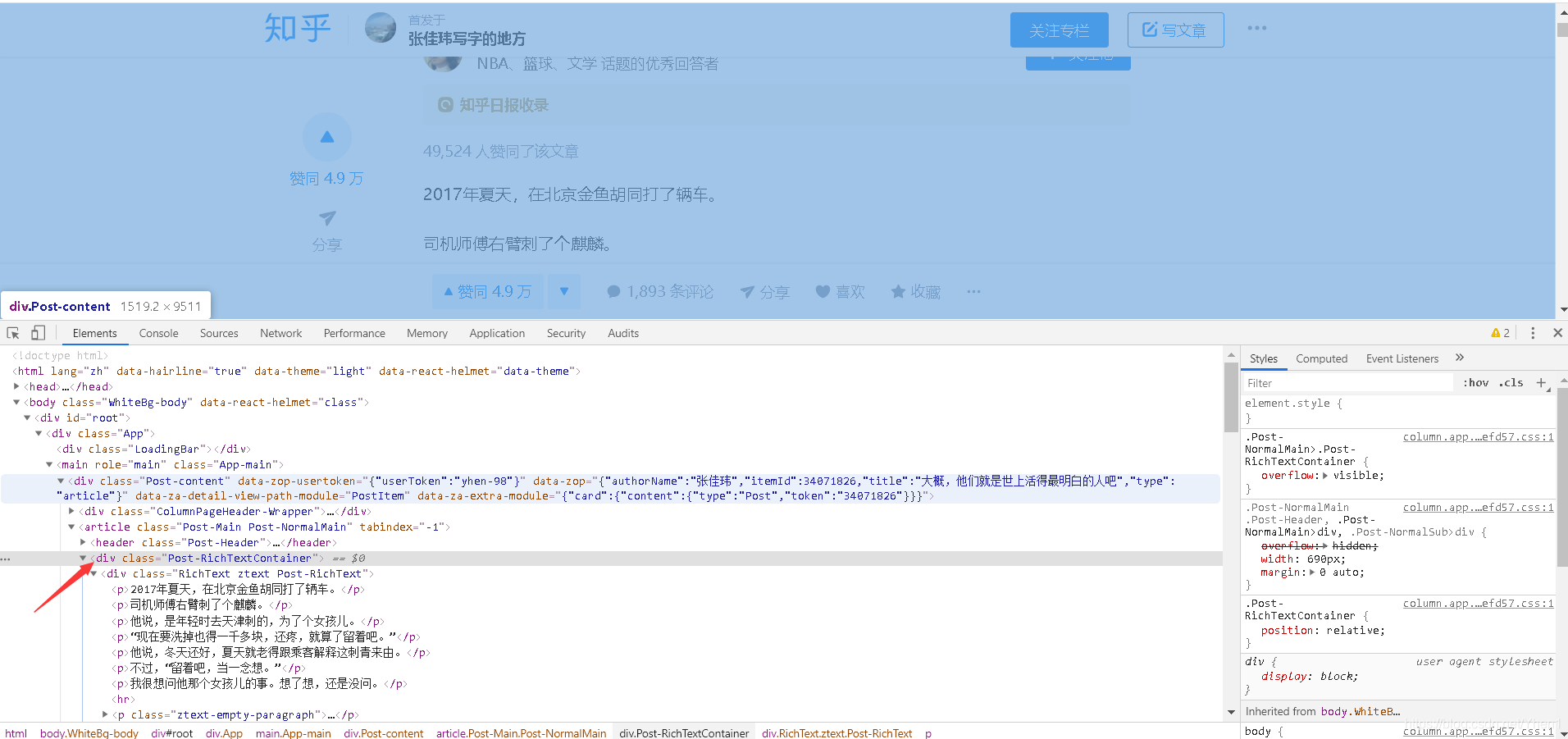
定位到文章文字后,我们可以看到,元素的最上级div标签对应的class(类选择器)为Post-RichTextContainer
OK,我们用pyquery把他们提取出来
首先导包
说一下,这个pq是别名的意思
用pyquery数据初始化后
用class类选择器来定位数据
from pyquery import PyQuery as pq
# 数据初始化
doc = pq(res)
# .是按类选择器定位数据
article = doc(".Post-RichTextContainer").items()
运行的结果是得到的是一组对象数据

然后我们遍历这组数据,并把得到的结果转换为文本的形式
for x in article:
v = x.text()
我们看下获取的数据
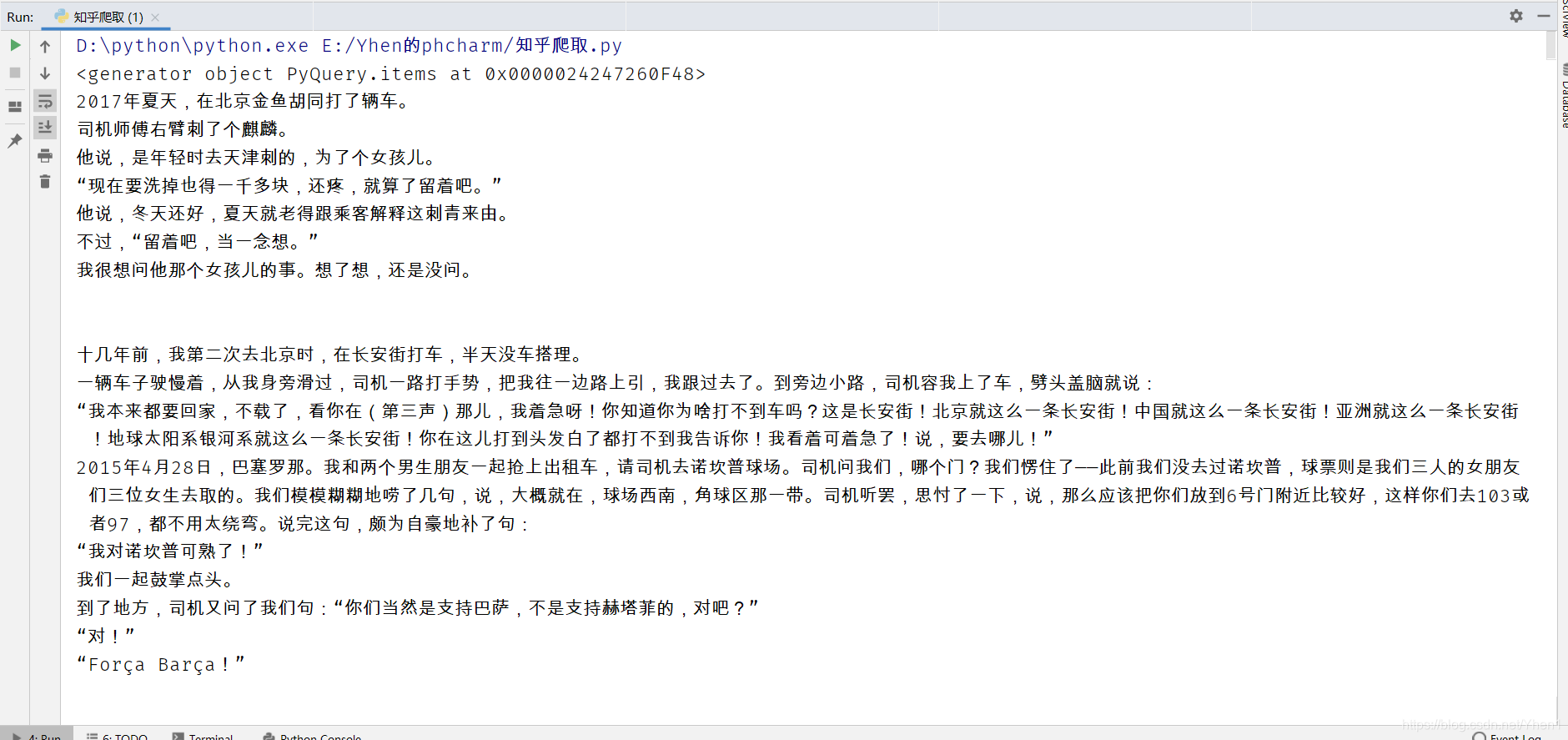
欧耶!是不是和刚刚在网页上看到的第一篇文章内容一样
说明我们成功爬下来了
接下来把他们保存成txt到本地
# 打开文件夹“知乎”,保存为“标题名.txt”,以“a”追加的方式写入,编码为“utf-8”
f = open("知乎/" + dict["title"] + ".txt", "a", encoding="utf-8")
# 写入
f.write(v)
# 关闭写入
f.close()
看看结果
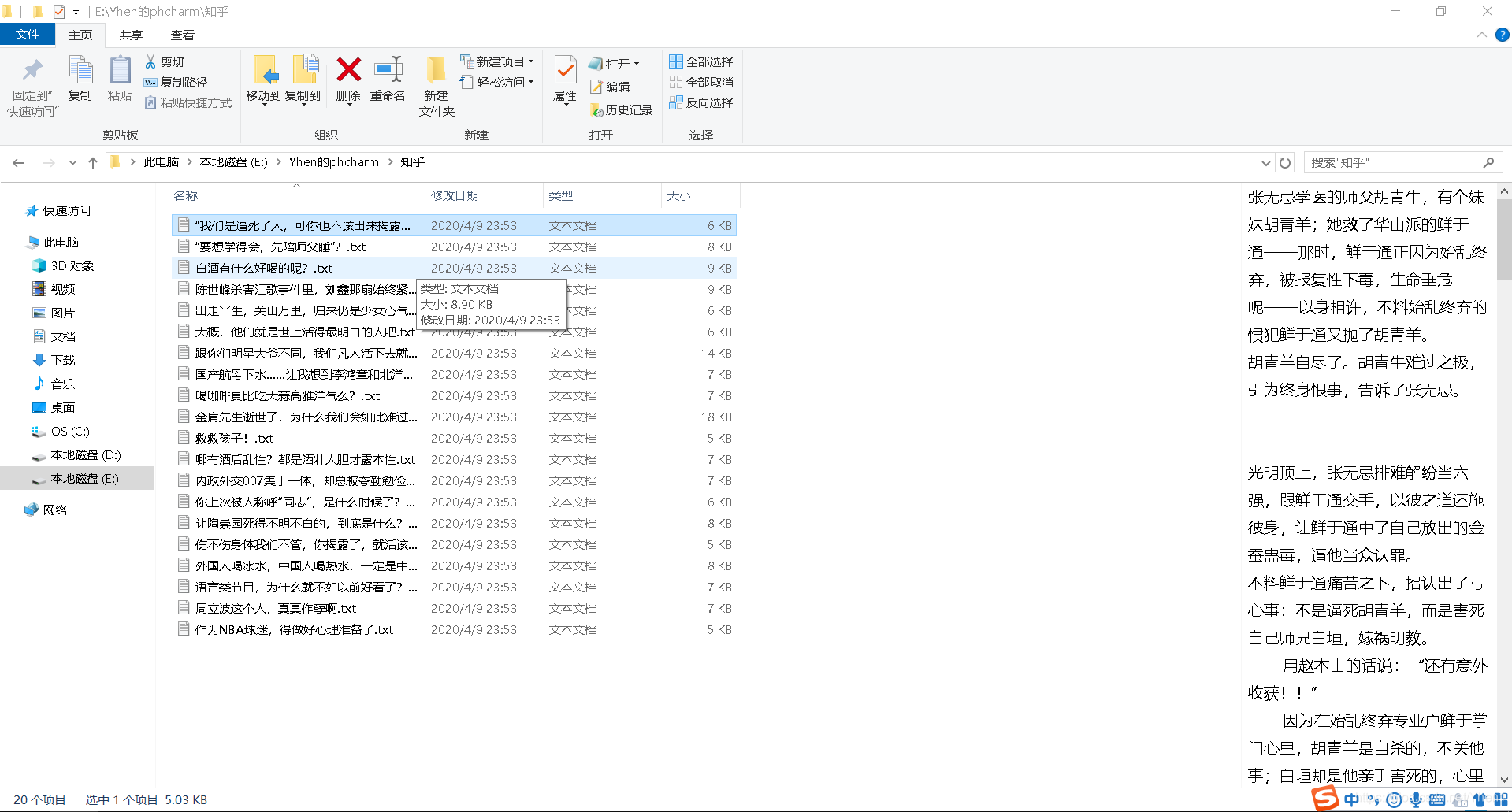
妙哉!大功告成啦
撒花撒花!
这里给大家拓展一下吧,我们刚刚获取的数据只是一页的,如果我们想要获取多页的怎么办呢?
这里给大家个提示

上面两张图分别是第一页和第二页的article接口
大家可以比较下他们的数据有什么不同
网页的url改变,他们的值也是会改变的
那么如果我们可以将他们的值改为我们想要的值,是不是就可以获取到我们想要的任意页面的数据了呢?
OK,就提示到这,下面的源码是没有这个功能的,大家可以自己思考下如何去做哦。
毕竟我不建议大家一次性爬取太多页的数据,这样会给服务器带来压力,虽然是爬虫,但是也要做一直友好的爬虫,不能给人家服务器带来太大的压力。人家都把数据给你爬了,你也要对人家好点是不是。
如果你真的要爬很多页,我建议你在请求的时候加个timeout延时,这样可以减轻服务器的压力。不然小心人家服务器生气了,直接禁止你ip访问你就GG了。
下面把源码提供给大家
import requests
from pyquery import PyQuery as pq
# 张佳玮文章页面的网址
url = 'https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?include=data%5B*%5D.comment_count%2Csuggest_edit%2Cis_normal%2Cthumbnail_extra_info%2Cthumbnail%2Ccan_comment%2Ccomment_permission%2Cadmin_closed_comment%2Ccontent%2Cvoteup_count%2Ccreated%2Cupdated%2Cupvoted_followees%2Cvoting%2Creview_info%2Cis_labeled%2Clabel_info%3Bdata%5B*%5D.author.badge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20&sort_by=voteups'
# 添加请求头 浏览器类型
headers ={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36'}
# 加上请求头对网址进行请求
response = requests.get(url,headers=headers).json()
# 取出字典中以data为键对应的数据
data =response["data"]
# 因为得到的数据是一个列表,所以用for遍历提取
for x in data:
# 新建一个空字典
dict={}
# 遍历后得到的数据是一个字典,取出字典中以title为键对应的数据,得到文章的标题,并把数据装进新建的字典里
dict["title"]=x["title"]
# 取出字典中以url为键对应的数据,得到文章的网址,并把数据装进新建的字典里
dict["url"]= x["url"]
# 对文章网址进行请求
res =requests.get(dict["url"],headers=headers).text
# 数据初始化
doc = pq(res)
# .是按类选择器选取数据
article = doc(".Post-RichTextContainer").items()
print(article)
# 遍历文章数据
for x in article:
v = x.text()
# 打开文件夹“知乎”,保存为“标题名.txt”,以“a”追加的方式写入,编码为“utf-8”
f = open("知乎/" + dict["title"] + ".txt", "a", encoding="utf-8")
# 写入
f.write(v)
# 关闭写入
f.close()
好啦!到这里主要的部分就完成啦!如果觉得写得可以的话,可以点个赞加关注嘛!谢谢大家的支持。有什么写得不好的地方也欢迎大家在评论区指出
ok 下面到我的吹水环节
Yhen说
呼~终于写完啦!不过这篇文章写起来感觉比第一篇要轻松。一是可能因为代码没有这么复杂,二也是可能我写熟练了哈哈哈。昨天下午想到要写一篇爬知乎文章的教程的。于是下午一点多开始写代码。在写代码的过程中也遇到了一些问题,所以耽误了一些时间。不过其实从我自己演习写代码开始到写完这篇教程,一个下午加一个晚上是足够的。不过因为要处理一些事情,所以才拖到现在。不过没事,我又不是写小说的,又没人催我交稿哈哈哈。我想写纯粹是因为我的兴趣还有希望得到你们的支持。好啦,废话不多说。下面看看我做的时候遇到的一些问题,我帮你们踩雷了,大家以此为鉴哦
彩蛋
大家一开始拿到要爬取文章这么一个需求的时候,最先想到的方法是什么?
有没有和我一样想的:这不是和我爬小说差不多嘛,用xpath通过首页的数据来获取到文章的url,然后再对这个url发送请求,再用一次xpath提取数据。就是这么简单粗暴,轻轻松松搞定,收工!

但是,结果真的会是我们想的这样吗?
先用xpath在网页中定位到所以的标题

然后敲代码
import requests
from lxml import etree
# 首页的url
url ='https://www.zhihu.com/people/zhang-jia-wei/posts/posts_by_votes?page=1'
# 请求头
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 对首页发送请求
res = requests.get(url,headers=headers).text
# 获取网页html数据
Html = etree.HTML(res)
# 用xpath提取数据源
title = Html.xpath('//div[@class="ContentItem ArticleItem"]/h2/a/text()')
for x in title:
print(x)
大家的想法这样没错吧
当我们自信满满的打印结果时
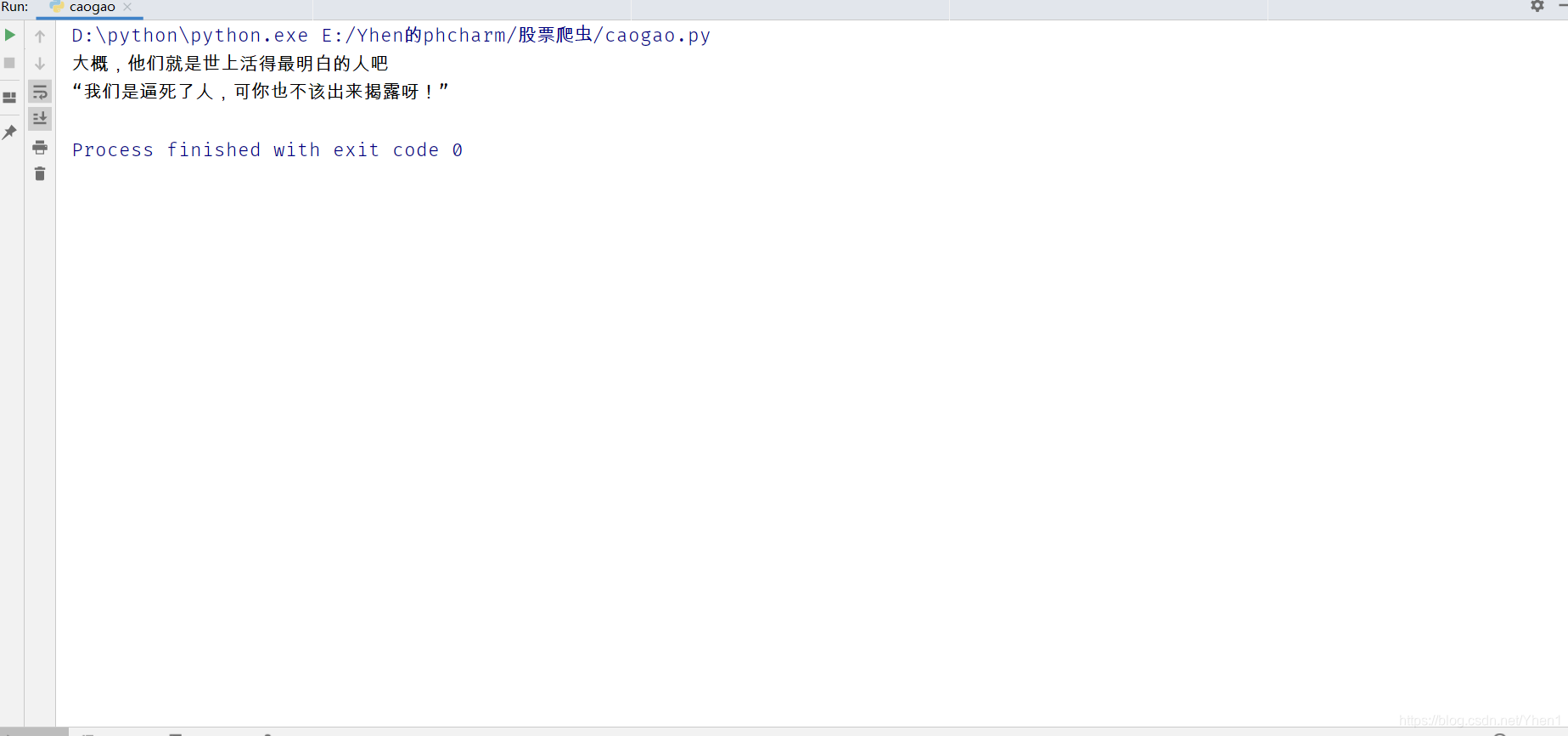
???????????????????????
??????小朋友你是否有很多的问号??????
刚刚明明页面上提取了这么多数据,怎么就剩两个了
再检查一下我们的xpath,写的没错啊!
见鬼了?
既然不是我们的数据提取有问题
那么很可能是因为我们发送请求后收到的数据里只有这两个标题,剩下的当然取不到啦
我们来检查下我们的请求信息
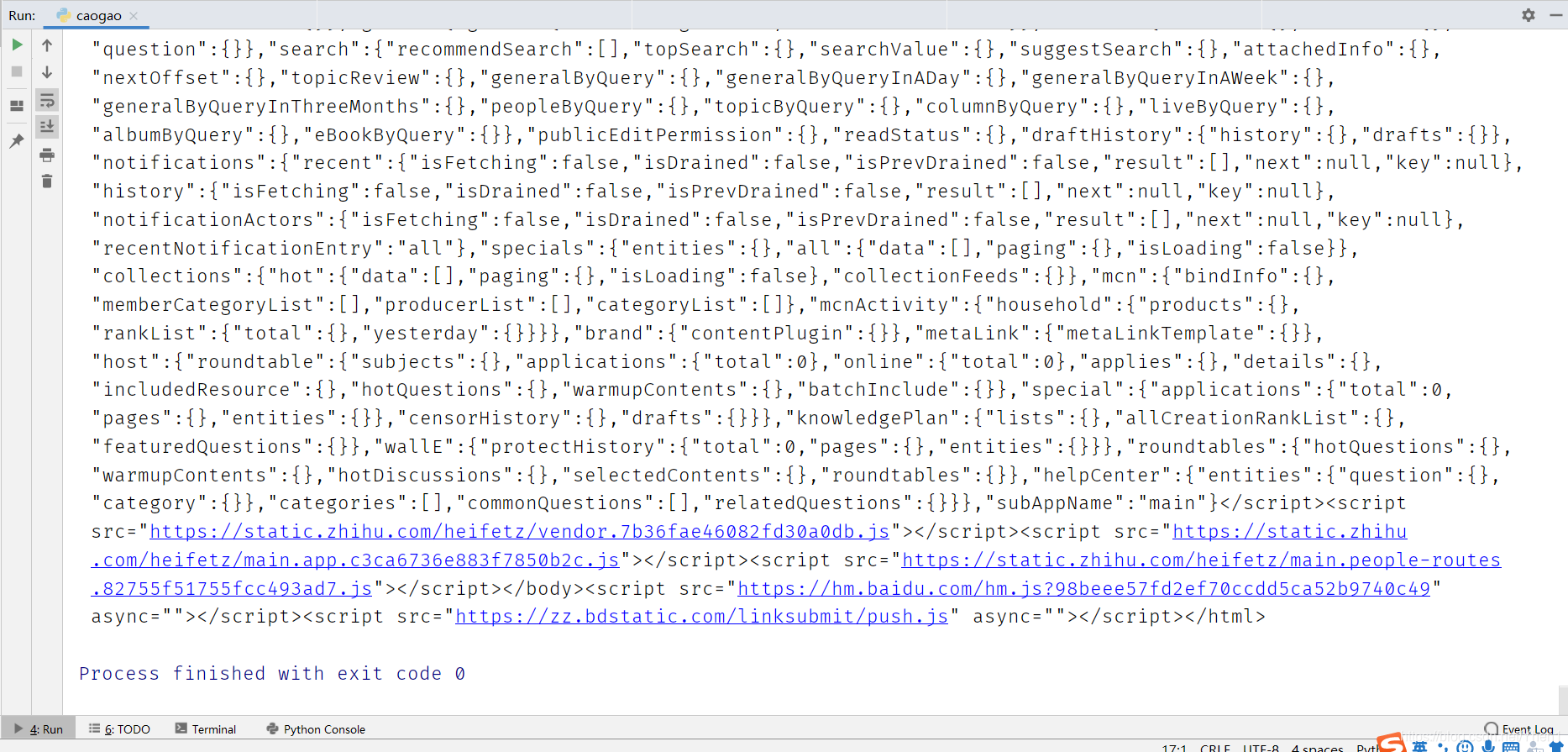
在这一堆数据里我们搜索最后一个标题:
出走半生,关山万里,归来仍是少女心气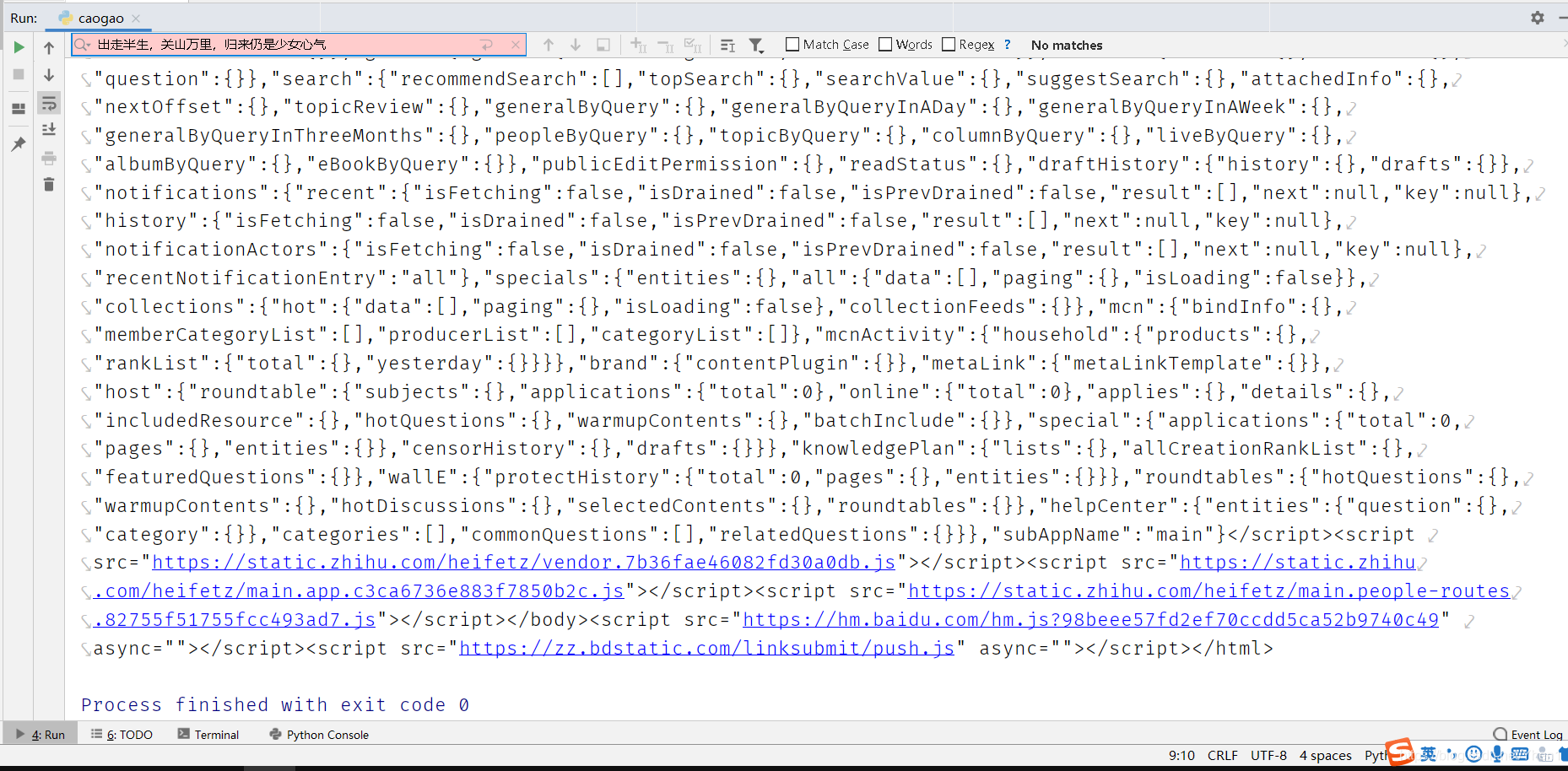
呵呵,冒红了,说明不存在这个数据
现在我们可以肯定我们请求错了
所以我们现在要找别的接口进行请求
然后我从页面渲染而来的数据入手
点击f12,找到network,点击xhr,点击preview
然后把他们的接口点开来看
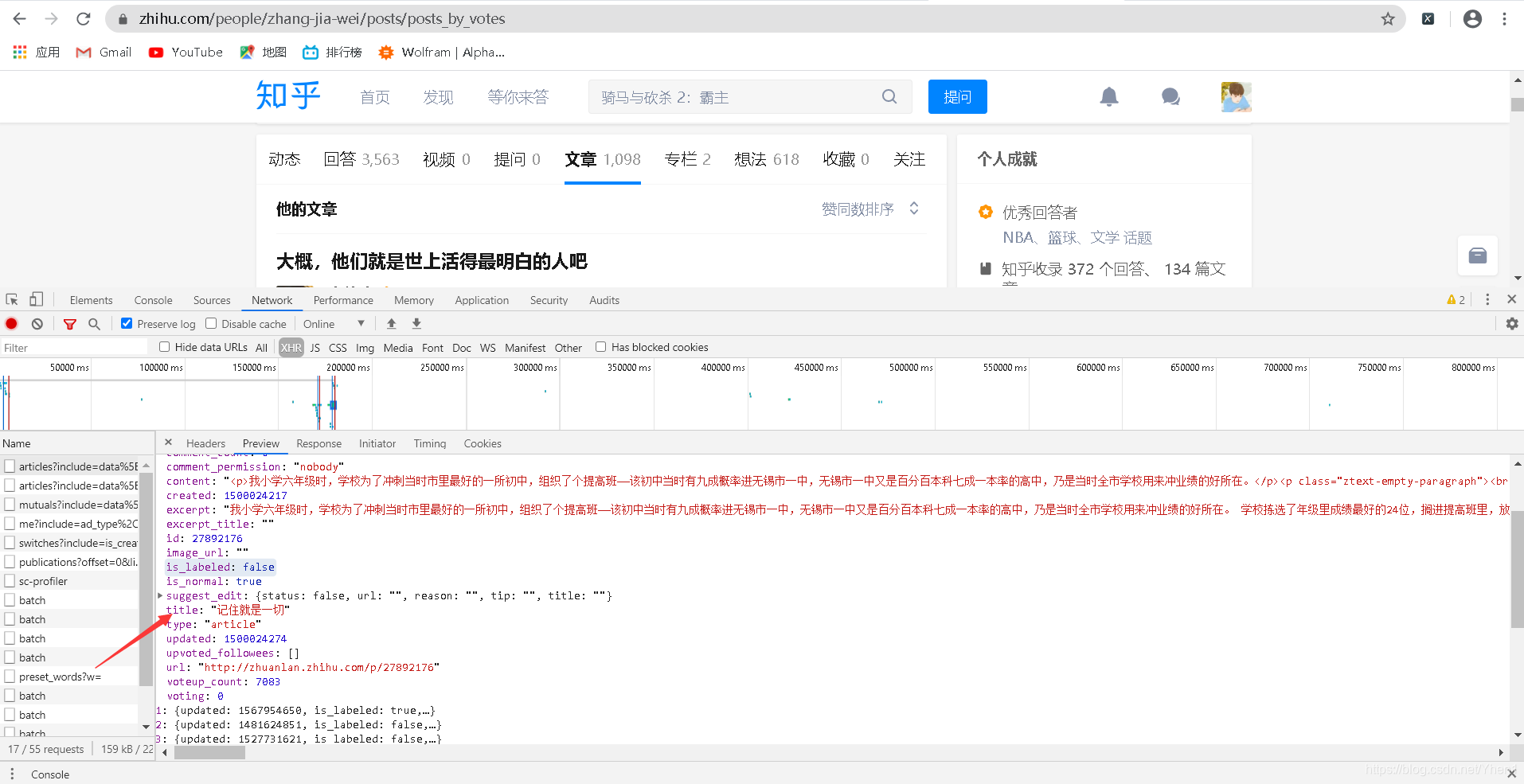
点开第一个,发现有一个叫title的,里面的内容:记住就是一切很可能就是我们要找的标题
然而,我浏览一遍网页,都没有发现这个标题。。gg还是找错了
于是我点开第二个和他长得差不多的
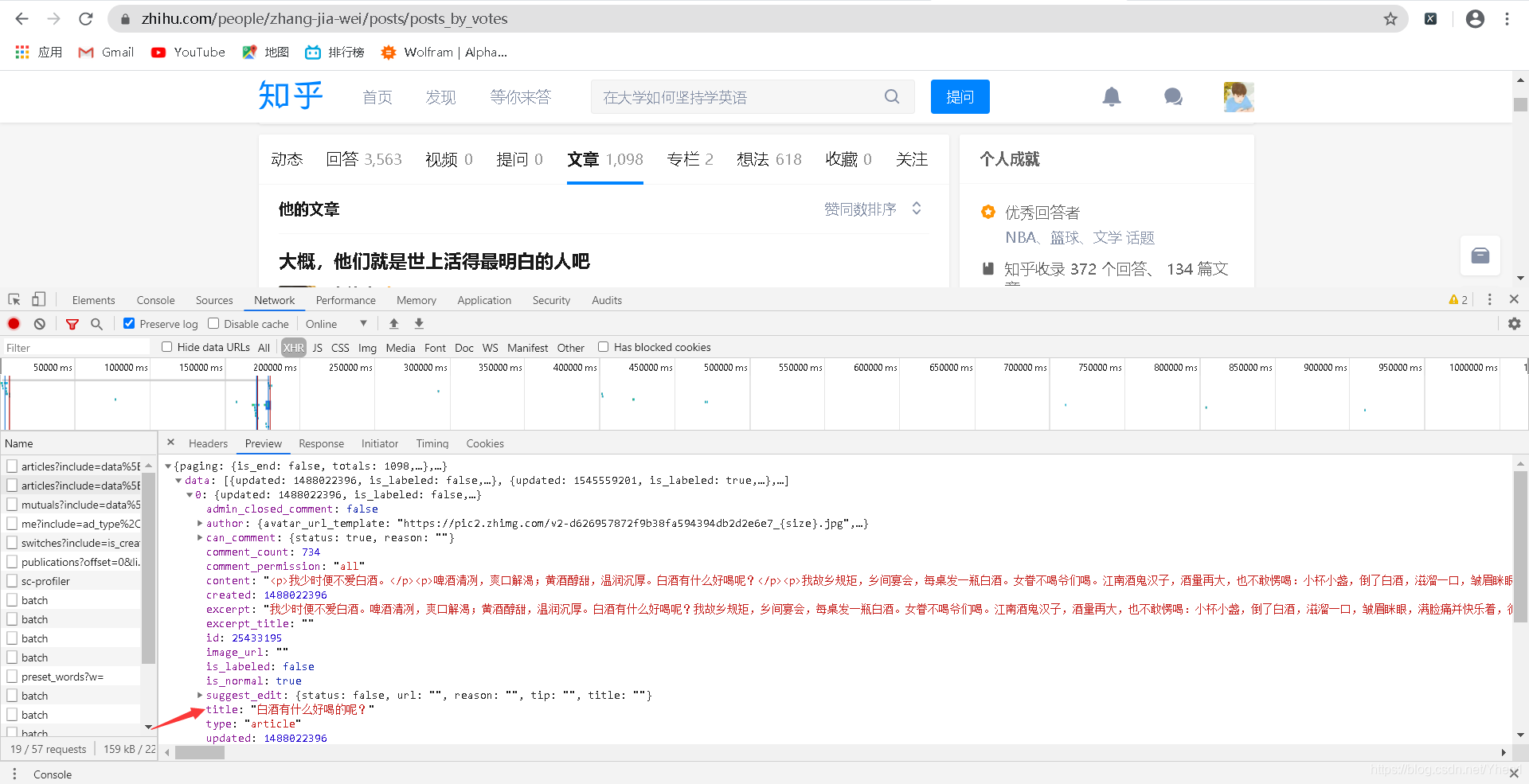
发现这里面同样有个title
我又浏览了一遍
发现了大收获

果然有这么一个内容
欧耶!这一定就是我们要的接口了,太棒了
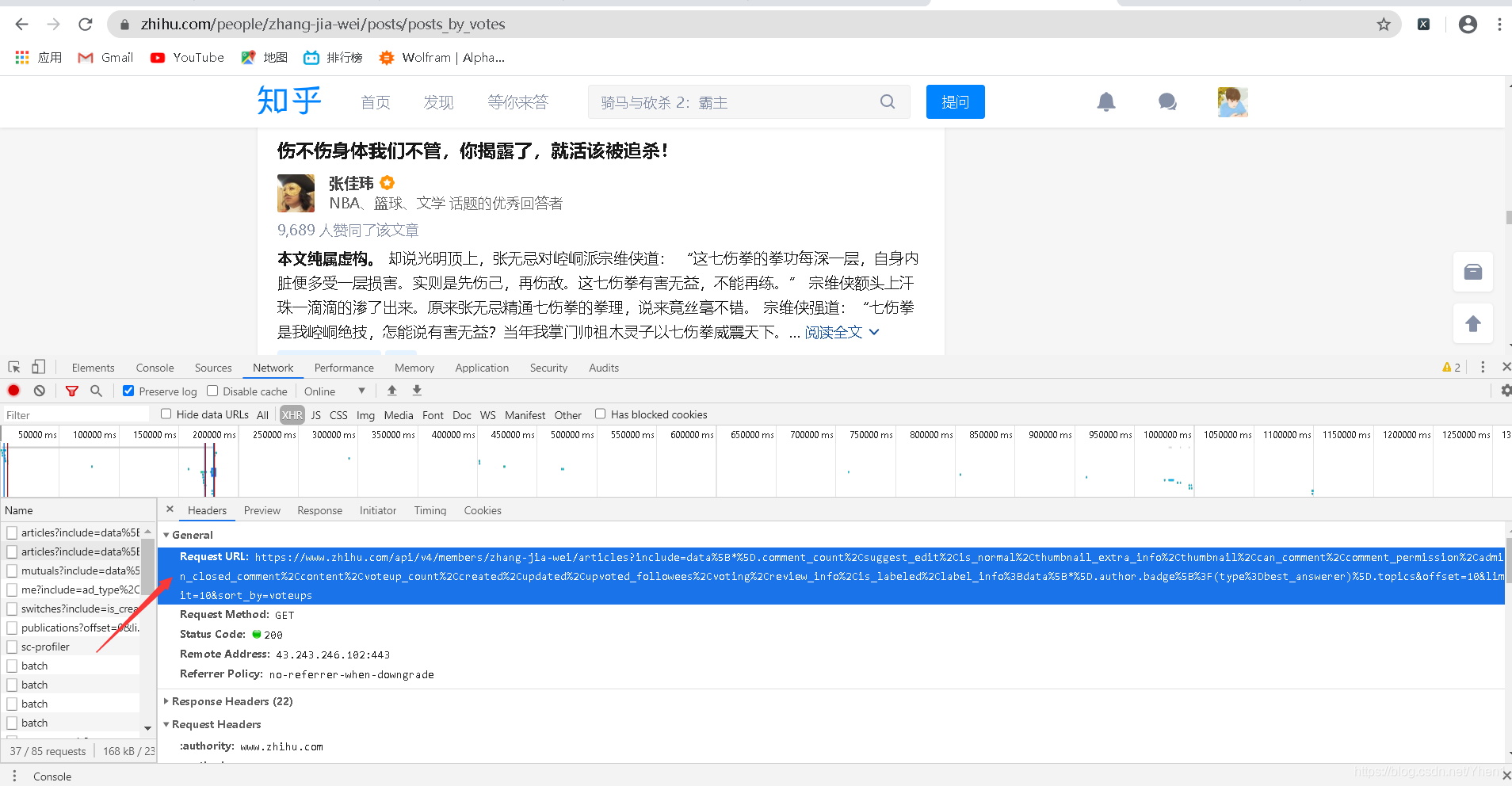
于是我兴致勃勃的对上方的这个网址发送请求,进行了一系列我教程里面的操作,按下执行键,翘起二郎腿,坐等丰收
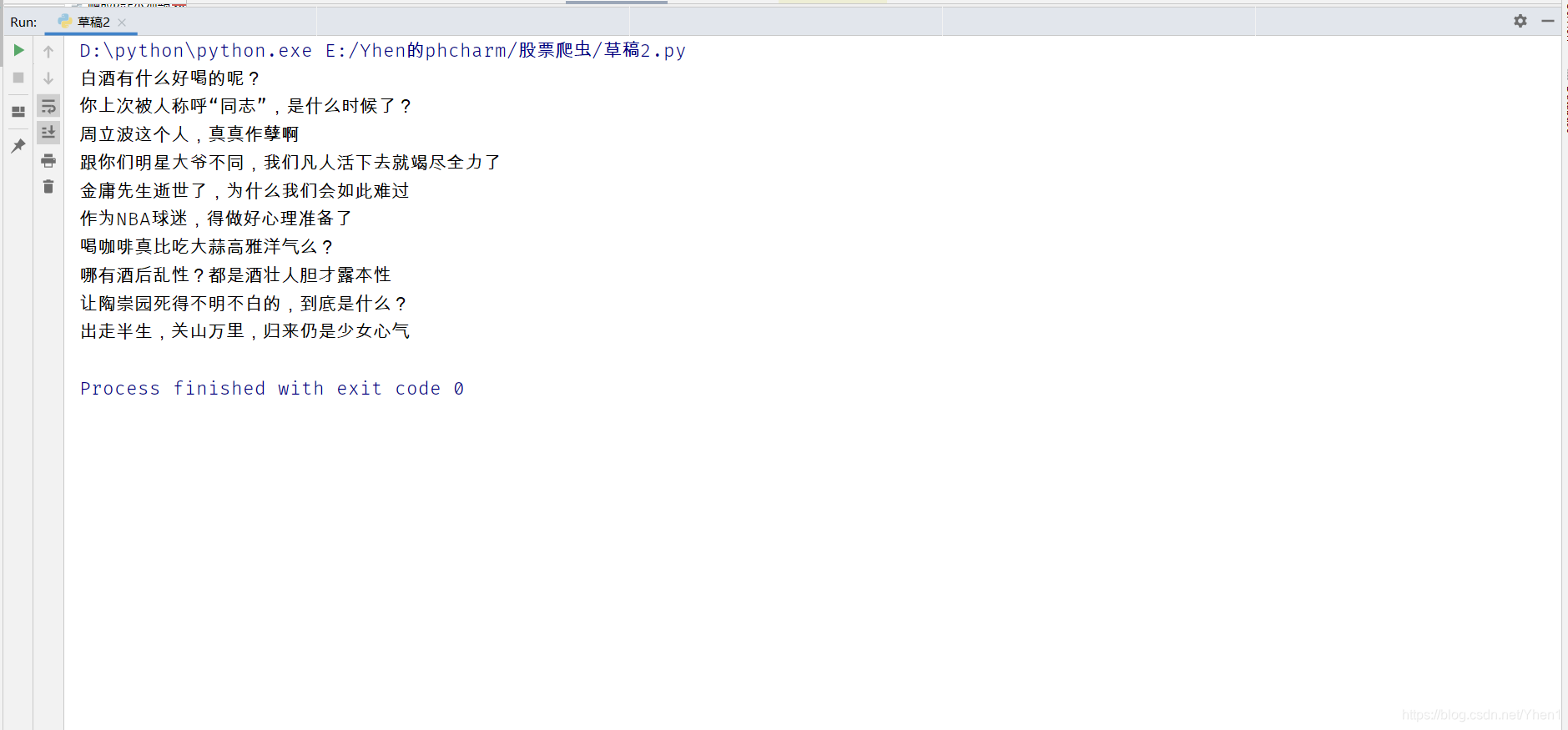
然而…只获取到了这些数据,虽然和刚刚的两条比起来好多了。但是第一页整个页面有20条啊,你这缩水了一半…无良商家啊!!!
我当时真有点奔溃了啊啊啊哈哈哈!!!我容易么我!
冷静下来后,我回到刚刚的接口看
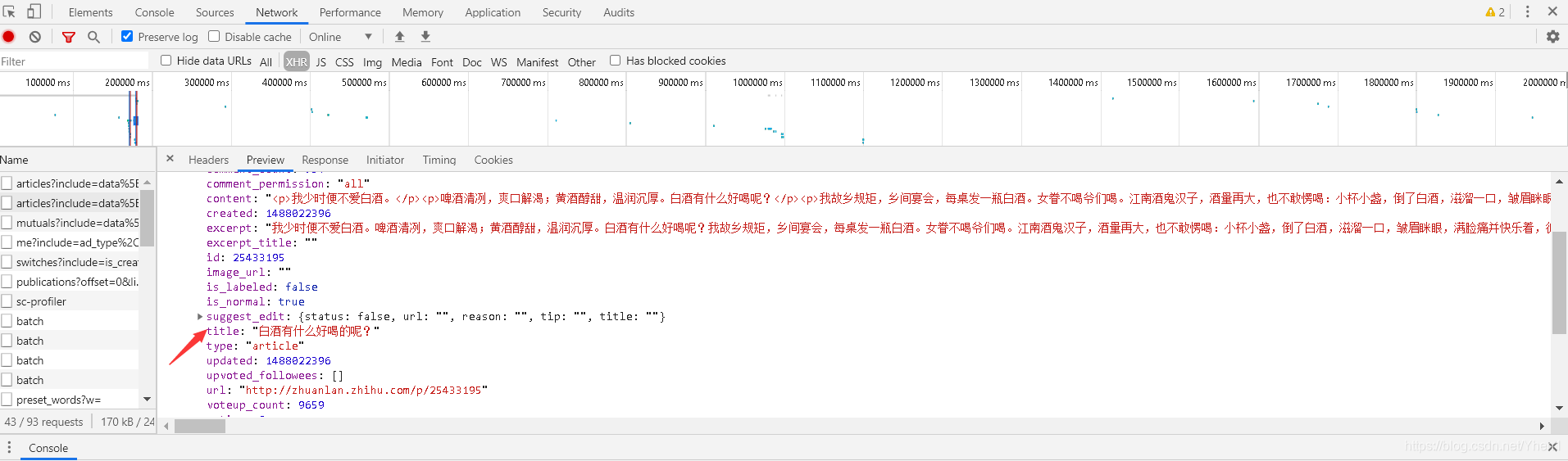
第0个,这个标题对应的是页面中的第11个标题,而我们刚刚爬下来的标题数据也是从这个开始,到最后一个。说明这个接口请求只能获取到这里有的也就是第11个开始的数据。
醉了,找了这么久还是找错了
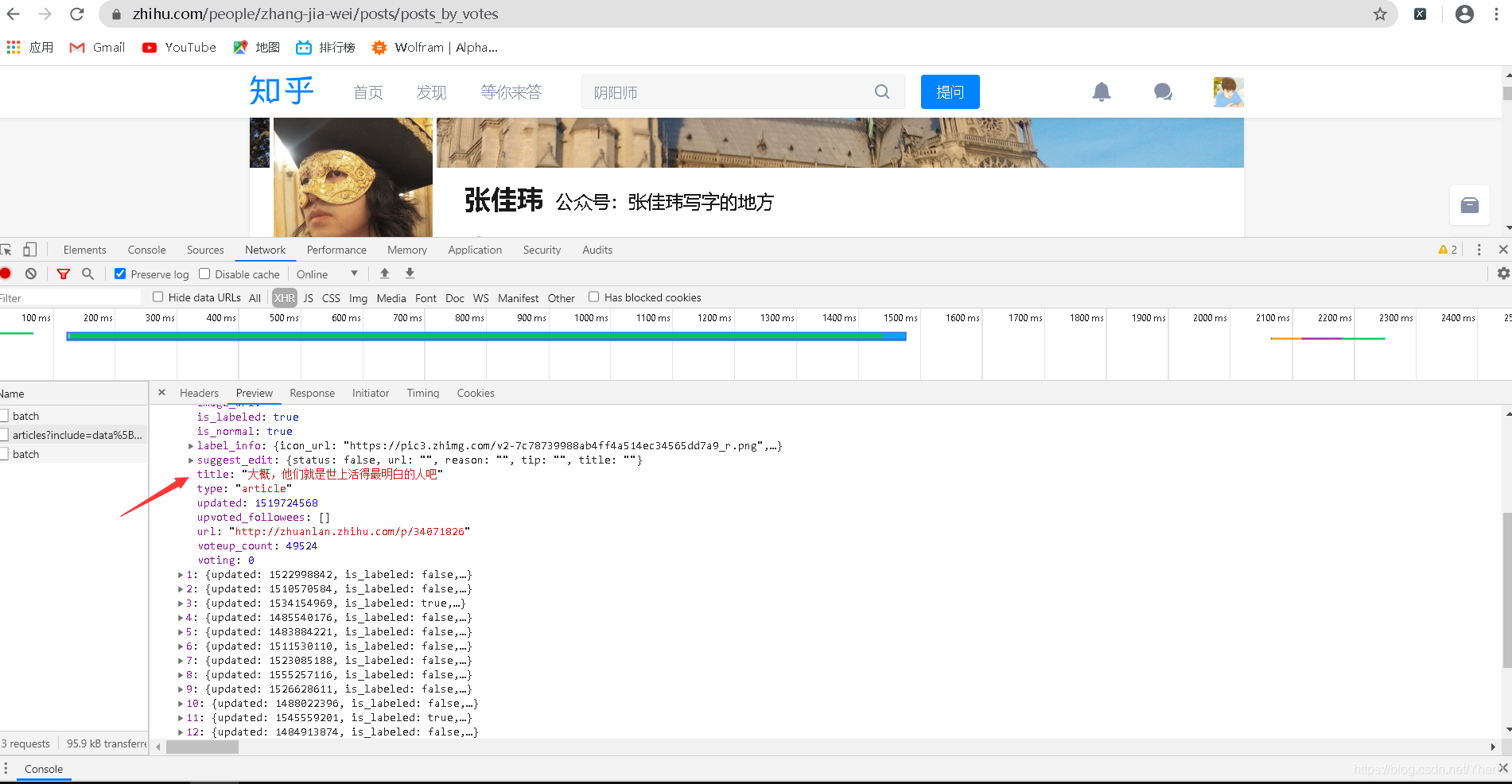
我又点开第一个接口数据,看看这个到底是个什么
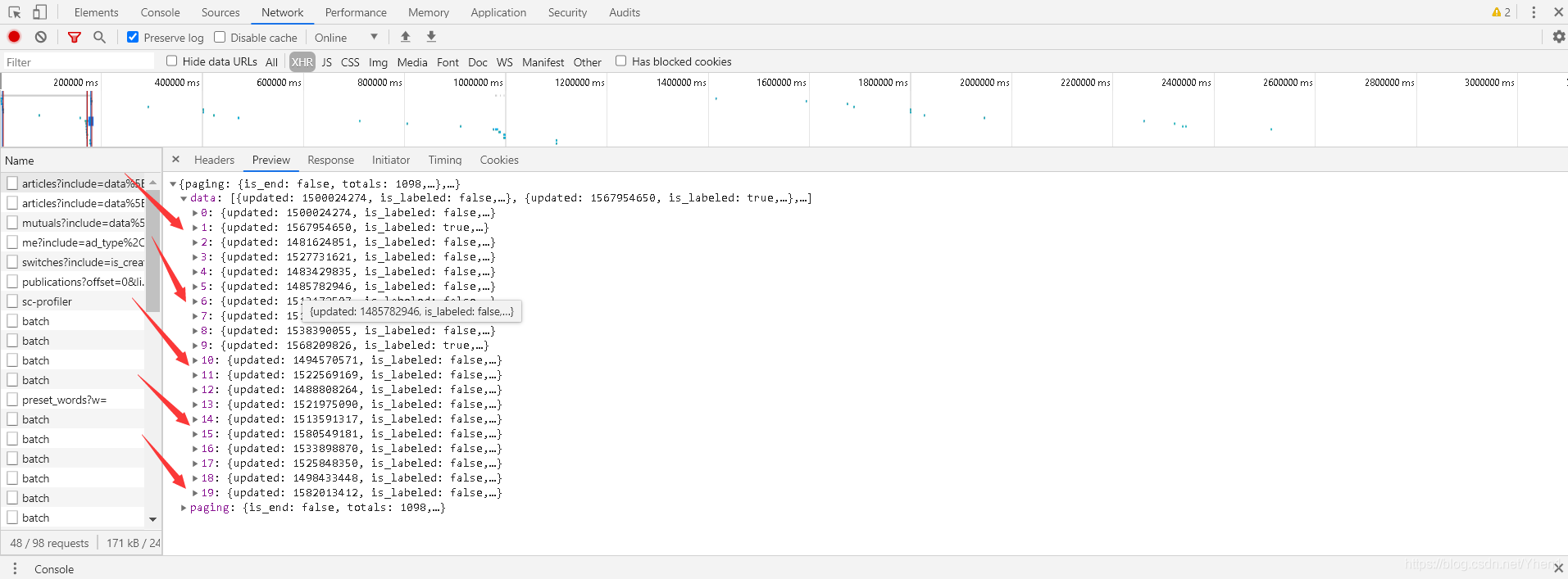
首先我们可以看到比刚刚第一个数据的接口多很多
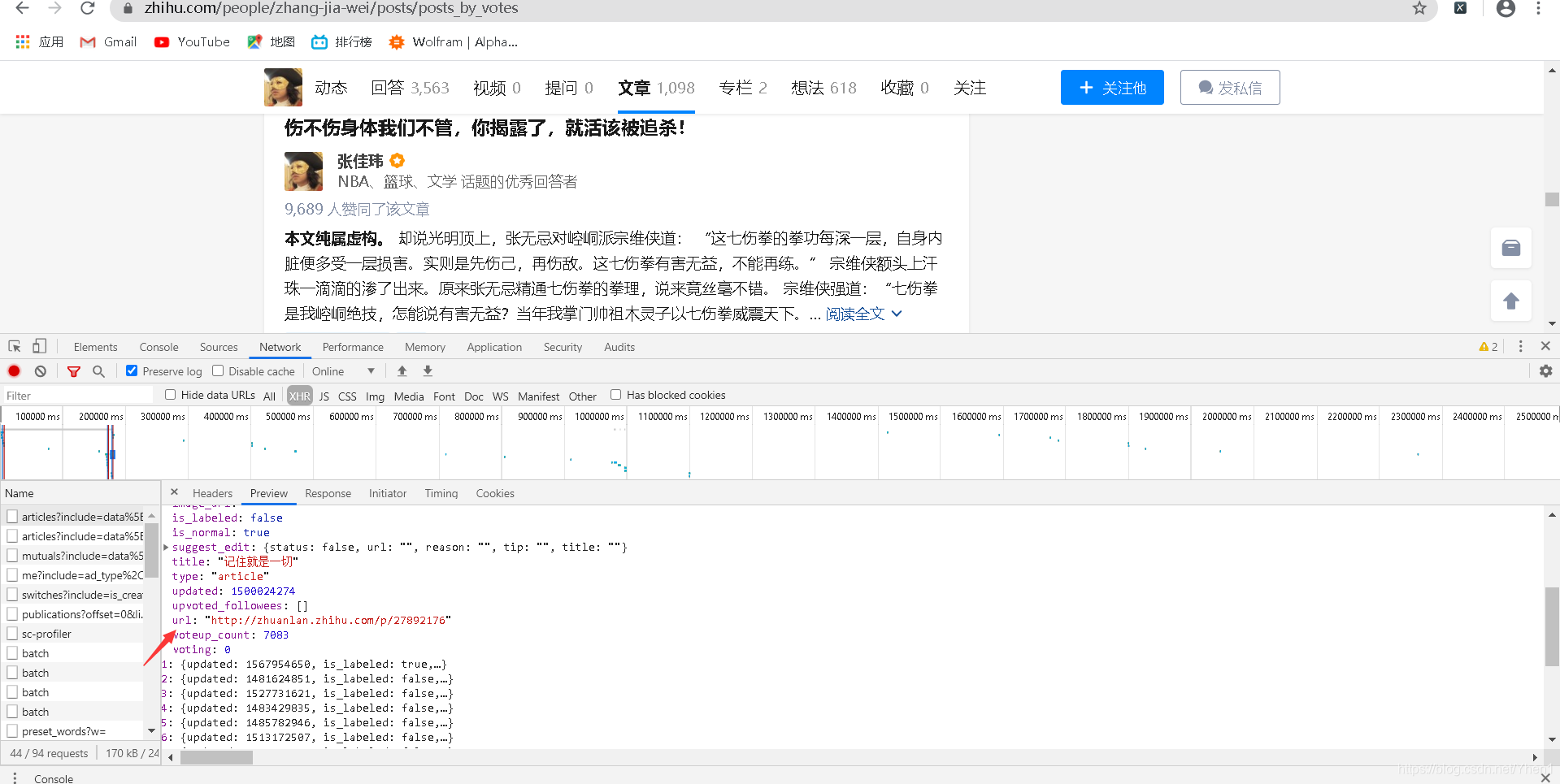
发现这里有个url,我复制网址栏,请求他
哦豁,原来这也是张佳玮文章的数据接口
但是这篇文章并不在第一页,那会不会在第二页呢
于是我打开第二页
真的在第二页!!!于是我对比了这个接口其他的接口,发现他们都是第二页标题
于是我不禁猜测到,既然第二页的完整数据在第一页,那么很有可能这些数据就是在加载第一页的时候一起加载出来的
所以我们要的第一页数据很有可能就在加载第0页的时候产生
但是大家都知道,是不存在第0页的
但是,是不是只要页面能跳转到这个页面就会产生数据呢?这样想,我们想要的数据应该会出现在第一页跳转前的页面
大家还记得一开始的文章是按什么排序的嘛?
没错,是按时间,因为我们点击了按点赞数排序,才会出现我们现在看到的第一页的数据
所以,我猜测,只要回到按时间排序的页面,打开f12抓包,就能得到我们想要的数据了
于是
我就用了上面教程找接口的方法,成功找到了含有所有我们第一页数据的接口,我就不重复操作了(忘了的同学可以在上面 复习下)
在这里贴下我们的成果
好啦,到这里我们的彩蛋也要结束了
呼~怎么感觉写彩蛋比写正文还累啊哈哈哈哈哈
不过没事,大家看的开心看的明白就好
就怕没人看或者没人能够耐心看到这咯
如果看到这的小伙伴可以在评论区扣个1嘛?
让我知道我这么辛苦写出来的东西还是有人看的。
好啦,又是时候说再见了
如果大家觉得我写的可以的话,可以点个赞或者关注下嘛,点赞关注一起来就更好啦!就当是给小弟一个鼓励嘛哈哈
很开心能在这和大家分享,希望大家能够有所收获,有什么建议或者疑问可在评论区留言。
以后我也会出其他的教程,把我会的分享给大家,谢谢!
我是Yhen ,我们下期见
上期回顾;“【爬虫】Yhen手把手带你用python爬小说网站,全网打尽,想看就看!(这可能会是你看过最详细的教程)”https://blog.csdn.net/Yhen1/article/details/105345343
