我们经常会拿selenium进行自动登录来搭建cookie池,对于不想自己网站被爬的站主/开发人员来说,防止自动化脚本操作网站自然是反爬必须要做的工作。那么,他们究竟有哪些手段来检测用户是否是selenium呢?今天就来总结一下常见的识别selenium的方法以及各种解决之道。
WebDriver识别
爬虫程序可以借助渲染工具从动态网页中获取数据,“借助”其实是通过对应的浏览器驱动(及Webdriver)向浏览器发出指令的行为。也就是说,开发者可以根据客户端是否包含浏览器驱动这一特征来区分正常用户和爬虫程序。
识别的原理
网页只要设置了检查webdriver的Javascript方法,就很容易发现爬虫。使用的方法就是Navigator对象的webdriver属性,用这个属性来判断客户端是否通过WebDriver驱动浏览器。如果监测到客户端的webdriver属性存在,则无法继续操作获取数据。selenium,Puppeteer都存在WebDriver属性。
监测结果有3种,分别是
-
true
-
false
-
undefind。
最广为人知的识别是否是selenium的方法就是 window.navigator.webdriver,当浏览器被打开后,js就会给当前窗口一个window属性,里面存放着用户的各种"信息"。
使用渲染工具有 webdriver 属性时,navigation.webdriver的返回值时true。反之则会返回false或者undefind。
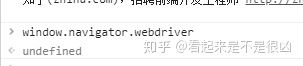
正常用户访问时的 webdriver 为 undefined

selenium访问时为true
简单的js来反爬 selenium
<script>
if(window.navigator.webdriver == true){
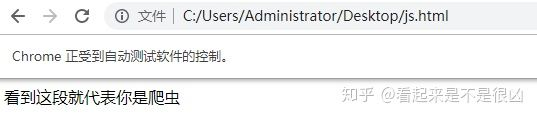
document.write("<span>看到这段就代表你是爬虫</span>")
}else{
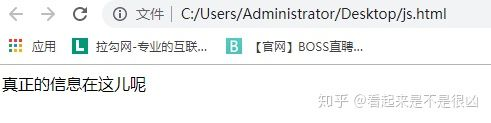
document.write("<span>真正的信息在这儿呢</span>")
}
</script>
- 现在把这段代码保存到HTML中分别正常打开和selenium打开
-
selenium打开
-
正常浏览器打开
其实,不只是webdriver,selenium打开浏览器后,还会有这些特征码:
webdriver
__driver_evaluate
__webdriver_evaluate
__selenium_evaluate
__fxdriver_evaluate
__driver_unwrapped
__webdriver_unwrapped
__selenium_unwrapped
__fxdriver_unwrapped
_Selenium_IDE_Recorder
_selenium
calledSelenium
_WEBDRIVER_ELEM_CACHE
ChromeDriverw
driver-evaluate
webdriver-evaluate
selenium-evaluate
webdriverCommand
webdriver-evaluate-response
__webdriverFunc
__webdriver_script_fn
__$webdriverAsyncExecutor
__lastWatirAlert
__lastWatirConfirm
__lastWatirPrompt
只要识别到这些,那么该用户就是selenium无误了
WebDriver识别的绕过方法
了解了WebDriver识别的原理和返回值后,我们就能相处应对的办法。既然 Web Driver 的识别依赖navigation.webdriver的返回值,那么我们在触发Javascript办法前将navigation.webdriver的返回值改为false或者undefind,问题就解决了。
script = 'Object.defineProperty(navigator,"webdriver",{get:() => false,});'
示例:
from selenium.webdriver import Chrome
import time
brower = Chrome(executable_path=r'D:\python\chromedriver_win32\chromedriver.exe')
url = 'http://www.porters.vip/features/webdriver.html'
brower.get(url)
script = 'Object.defineProperty(navigator,"webdriver",{get:() => false,});'
#运行Javascript
brower.execute_script(script)
#定位按钮并点击
brower.find_element_by_css_selector('.btn.btn-primary.btn-lg').click()
#定位到文章内容元素
elements = brower.find_element_by_css_selector('#content')
time.sleep(1)
print(elements.text)
brower.close()
值得一提的是,淘宝的登录滑块验证页面也是用到了这个方法,使用selenium套件操作滑块后会出现“哎呀,出错了,点击刷新再来一次”这样的提示。
注意: 这种修改该属性值的办法只在当前页面有效,当浏览器打开新标签或新窗口时需要重新执行改变navigator.webdriver值的JavaScript代码。
其他的解决办法
- 使用火狐浏览器
-
很多时候selenium+谷歌打不开目标网站,都可以用火狐试试。
-
因为selenium只是一个控制浏览器的工具,而chromedriver和geckodriver都不是selenium官方发布的(鬼知道谁发布的),因此在控制浏览器方面会有不同的差异,具体原理不再赘述,总之很多网站不能用selenium+chrome就可以试试firefox。
(理论上IE也可能会达到相应效果,但IE内核实在太烂了,selenium+IE=龟速爬虫)
- 给 webdriver 的 options增加参数
-
谷歌浏览器的设置中有一个参数名为excludeSwitches,它的值是一个数组,向里面添加chrome的命令就可以在selenium打开chrome后自动执行数组内的指令,我们向里面添加一个enable-automation
from selenium import webdriver from selenium.webdriver import ChromeOptions option = ChromeOptions() option.add_experimental_option('excludeSwitches', ['enable-automation']) brower = webdriver.Chrome(options=option) brower.get('file:///C:/Users/Administrator/Desktop/js.html')此时运行这段代码,发现可以拿到正确的信息

- 中间人代理mitmproxy
mitmproxy其实和 fiddler/charles 等抓包工具的原理有些类似,作为一个第三方,它会把自己伪装成你的浏览器向服务器发起请求,服务器返回的response会经由它传递给你的浏览器,你可以通过编写脚本来更改这些数据的传递,从而实现对服务器的“欺骗”和对客户端的“欺骗”。
具体原理和使用见此
下面提供一个防屏蔽selenium的简单demo
# my_demo.py
from mitmproxy import ctx
def response(flow):
# 'js'字符串为目标网站的相应js名
if 'js' in flow.request.url:
for i in ['webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate', '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped', '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium', '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate', 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc', '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert', '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo', '$cdc_asdjflasutopfhvcZLmcfl_']:
ctx.log.info('Remove %s from %s.' % (i, flow.request.url))
flow.response.text = flow.response.text.replace('"%s"' % (i), '"NO-SUCH-ATTR"')
flow.response.text = flow.response.text.replace('t.webdriver', 'false')
flow.response.text = flow.response.text.replace('ChromeDriver', '')
然后我们使用如下命令行启动脚本
mitmdump.exe -S my_demo.py
然后通过selenium就可以正常访问一些屏蔽selenium的网站了
- pyppeteer
它是一个基于node.js的chrome官方框架,主要用于操作谷歌无头模式进行各种操作,pyppeteer则是puppeteer的python版本。
它的作用和selenium是类似的,通过脚本操作无头谷歌,但是它并不会有selenium那么多的特征字符串,可以做到完全把“自己”当作真人操作。
当然,它还是有缺点的.虽然puppeteer一直在更新,但是pyppeteer已经停止更新将近一年了,所以无法保证它以后是否可用。同样因为它是基于谷歌无头的,因此它只能用于谷歌无头,不想selenium一样,编写完脚本只需改变少量代码,便可以在多种浏览器中运行。
- 下面是pyppeteer的官方文档:https://miyakogi.github.io/pyppeteer/
下面是一个简单的demo
import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('file:///C:/Users/Administrator/Desktop/js.html')
print(await page.content())
asyncio.get_event_loop().run_until_complete(main())
如果你电脑中没有chromium,执行这段代码后会自动帮你安装,然后再运行这段代码,但是非常慢,所以建议自己网上下载chromium后再执行脚本
参考原址:知乎大佬 https://blog.csdn.net/weixin_43870646/article/details/105418801
参考原址:CSDN道友 https://zhuanlan.zhihu.com/p/78368287?from_voters_page=true
