反爬与反反爬一直是一个相互博弈的游戏。道高一尺,魔高一丈,知己知彼方能百战不殆,想要突破网站的反爬机制,你必须深入了解当下的前端开发技术,才能在这个游戏中生存下去。
本人是一名爬虫爱好者,最近在爬一个小说网站时,通过抓包分析,发现小说正文被加密过了,如图所示:
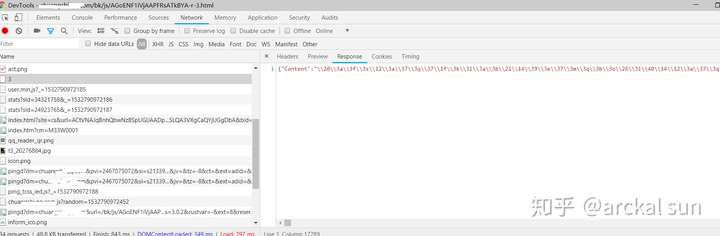
获取小说正文的响应数据

小说正文加密数据
根据字面意思可以看到,小说正文是编码保存在Content这个键中,但这种字符编码不能显示解码出来,遂认定它经过了加密处理。这个时候我们就要查看网页js代码分析编码转换过程了。但是一个网页的js代码是非常多的,并且也经过编译混淆压缩,所以直接通篇看是耗费精力的。所以我们要掌握一定的技巧,才能更有效率的解决问题。
接下来,我分享下我查看js代码的一些经验。
首先,看这个请求地址,可以发现"index.php/Bookreader"是这个url中固定的部分,
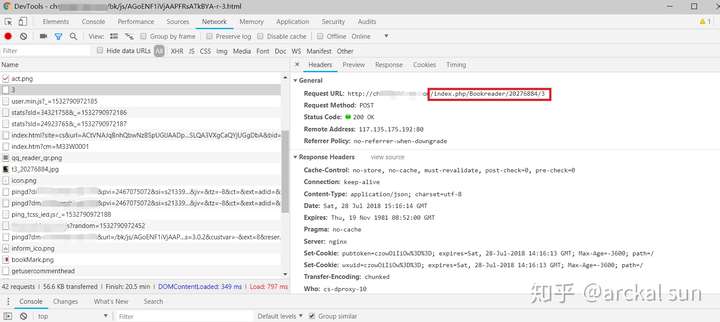
然后,我们按快捷键Ctrl+Shift+F 搜索,结果如下
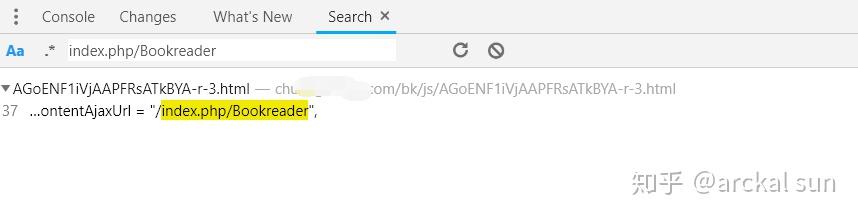
点击这条结果,定位位置
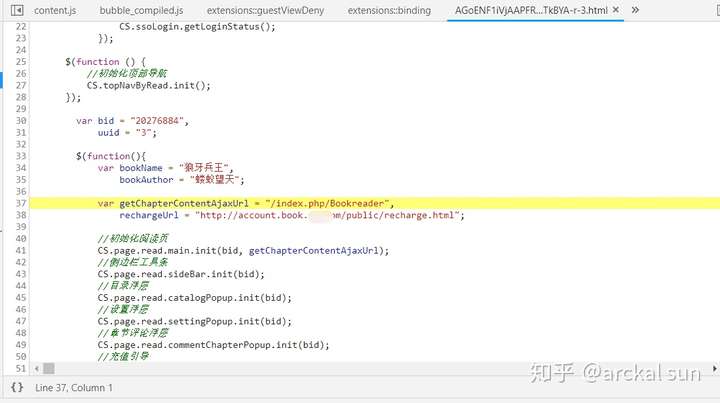
可以看到,这个接口路径赋值给了变量getChapterContentAjaxUrl,接下来,搜索这个变量,看它被调用的位置。
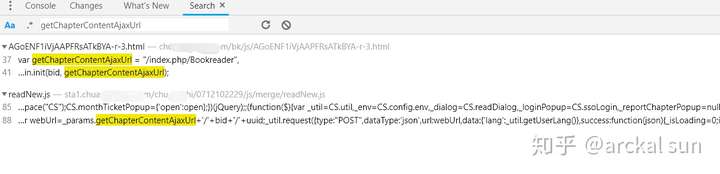
由经验知,点击最下面这个,打开js代码页面
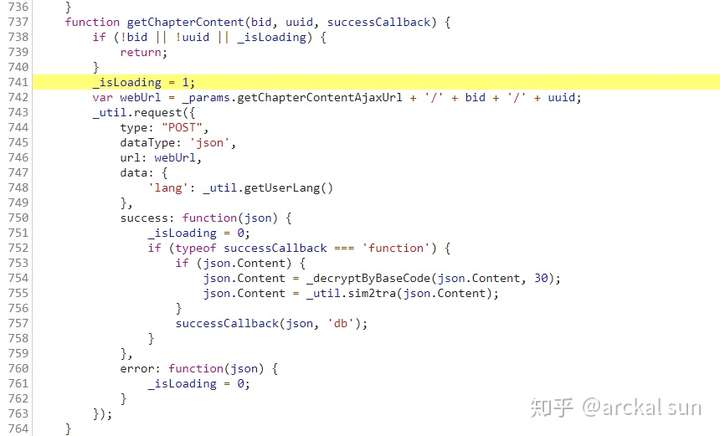
看到这个代码逻辑,相信你已经看懂了,在这个POST请求成功后,返回json数据,然后对json的Content字段进行解码,在第754行有一个函数“_decryptByBaseCode”是实现解码功能的函数,OK,接下来看这是函数的具体实现就好了。
在这地方下断点,命中断点后
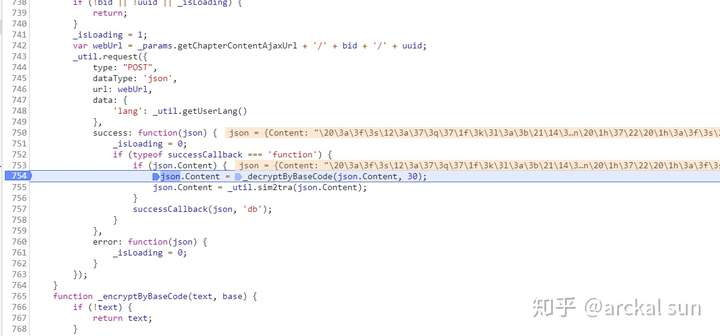
点击F9单步执行,跟踪进去
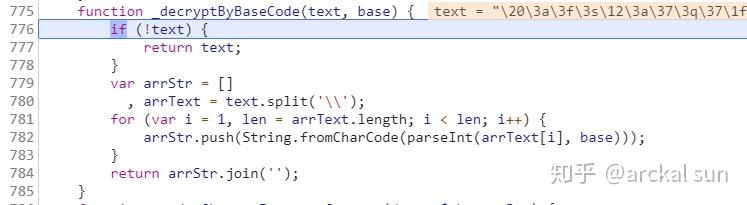
函数_decryptByBaseCode的实现代码
可以看到,这个解码逻辑非常简单,将text用反斜杠分割为数据,然后逐个进行解码。
这里有两个函数String.fromCharCode和parseInt,第一个是将int转为unicode字符,第二个是将字符串按指定进制转为int,这里他们用的是30进制进行编码加密的。
所以这个函数我们完全可以用python实现。实现代码如下,
# 解码
def decrypt_by_basecode(text,base):
if not text:
return
# base=30
arrStr = []
arrText = text.split('\\')
for i in arrText:
if i:
s = chr(int(i,base))
arrStr.append(s)
objStr = ''.join(arrStr)
return objStr
写好解码函数后,我们就可以在程序中调用这是接口,然后解码小说内容了。
通过以上的实战演示,可以看到一名优秀的爬虫工程师,也必是一名资深前端工程师。
欢迎大家关注我的知乎账号
我会不定期的分享一些技术经验的。^_^