C API 纵览
Lua 是一个嵌入式的语言,意味着 Lua 不仅可以是一个独立运行的程序包也可以是一个用来嵌入其他应用的程序库。你可能觉得奇怪:如果 Lua 不只是独立的程序,为什么到目前为止贯穿整本书我们都是在使用 Lua 独立程序呢?这个问题的答案在于 Lua 解释器(可执行的 lua)。Lua 解释器是一个使用 Lua 标准库实现的独立的解释器,她是一个很小的应用(总共不超过 500 行的代码)。解释器负责程序和使用者的接口:从使用者那里获取文件或者字符串,并传给 Lua 标准库,Lua 标准库负责最终的代码运行。
Lua 可以作为程序库用来扩展应用的功能,也就是 Lua 可以作为扩展性语言的原因所在。同时,Lua 程序中可以注册有其他语言实现的函数,这些函数可能由 C 语言(或其他语言)实现,可以增加一些不容易由 Lua 实现的功能。这使得 Lua 是可扩展的。与上面两种观点(Lua 作为扩展性语言和可扩展的语言)对应的 C 和 Lua 中间有两种交互方式。
第一种,C 作为应用程序语言,Lua 作为一个库使用;
第二种,反过来,Lua 作为程序语言,C 作为库使用。这两种方式,C 语言都使用相同的 API 与 Lua 通信,因此 C 和Lua 交互这部分称为 C API。
C API 是一个 C 代码与 Lua 进行交互的函数集。他有以下部分组成:读写 Lua 全局变量的函数,调用 Lua 函数的函数,运行 Lua 代码片断的函数,注册 C 函数然后可以在Lua 中被调用的函数,等等。(本书中,术语函数实际上指函数或者宏,API 有些函数为了方便以宏的方式实现)
C API 遵循 C 语言的语法形式,这 Lua 有所不同。当使用 C 进行程序设计的时候,我们必须注意,类型检查,错误处理,内存分配都很多问题。API 中的大部分函数并不检查他们参数的正确性;你需要在调用函数之前负责确保参数是有效的。如果你传递了错误的参数,可能得到 “segmentation fault” 这样或者类似的错误信息,而没有很明确的错误信息可以获得。另外,API 重点放在了灵活性和简洁性方面,有时候以牺牲方便实用为代价的。一般的任务可能需要涉及很多个 API 调用,这可能令人烦恼,但是他给你提供了对细节的全部控制的能力,比如错误处理,缓冲大小,和类似的问题。如本章的标题所示,这一章的目标是对当你从 C 调用 Lua 时将涉及到哪些内容的预览。如果不能理解某些细节不要着急,后面我们会一一详细介绍。不过,在 Lua 参考手册中有对指定函数的详细描述。另外,在 Lua 发布版中你可以看到 API 的应用的例子,Lua 独立的解释器(lua.c)提供了应用代码的例子,而标准库(lmathlib.c、lstrlib.c 等等)提供了程
序库代码的例子。
从现在开始,你戴上了 C 程序员的帽子,当我们谈到“你/你们”,我们意思是指当你使用 C 编程的时候。在 C 和 Lua 之间通信关键内容在于一个虚拟的栈。几乎所有的API 调用都是对栈上的值进行操作,所有 C 与 Lua 之间的数据交换也都通过这个栈来完成。另外,你也可以使用栈来保存临时变量。栈的使用解决了 C 和 Lua 之间两个不协调的问题:
第一,Lua 会自动进行垃圾收集,而 C 要求显示的分配存储单元,两者引起的矛盾。
第二,Lua 中的动态类型和 C 中的静态类型不一致引起的混乱。我们将在 24.2 节详细地介绍栈的相关内容。
第一个示例程序
通过一个简单的应用程序让我们开始这个预览:一个独立的 Lua 解释器的实现。我们写一个简单的解释器,代码如下:
#include <stdio.h>
#include <lua.h>
#include <lauxlib.h>
#include <lualib.h>
int main (void)
{
char buff[256];
int error;
lua_State *L = lua_open(); /* opens Lua */
luaopen_base(L); /* opens the basic library */
luaopen_table(L); /* opens the table library */
luaopen_io(L); /* opens the I/O library */
luaopen_string(L); /* opens the string lib. */
luaopen_math(L); /* opens the math lib. */
while (fgets(buff, sizeof(buff), stdin) != NULL) {
error = luaL_loadbuffer(L, buff, strlen(buff),
"line") || lua_pcall(L, 0, 0, 0);
if (error) {
fprintf(stderr, "%s", lua_tostring(L, -1));
lua_pop(L, 1);/* pop error message from the stack */
}
}
lua_close(L);
return 0;
}
头文件 lua.h 定义了 Lua 提供的基础函数。其中包括创建一个新的 Lua 环境的函数(如 lua_open),调用 Lua 函数(如 lua_pcall)的函数,读取/写入 Lua 环境的全局变量的函数,注册可以被 Lua 代码调用的新函数的函数,等等。所有在 lua.h 中被定义的都有一个 lua_前缀。
头文件 lauxlib.h 定义了辅助库(auxlib)提供的函数。同样,所有在其中定义的函数等都以 luaL_打头(例如,luaL_loadbuffer)。辅助库利用 lua.h 中提供的基础函数提供了更高层次上的抽象;所有 Lua 标准库都使用了 auxlib。基础 API 致力于 economy and orthogonality,相反 auxlib 致力于实现一般任务的实用性。当然,基于你的程序的需要而创建其它的抽象也是非常容易的。需要铭记在心的是,auxlib 没有存取 Lua 内部的权限。它完成它所有的工作都是通过正式的基本 API。
Lua 库没有定义任何全局变量。它所有的状态保存在动态结构 lua_State 中,而且指向这个结构的指针作为所有 Lua 函数的一个参数。这样的实现方式使得 Lua 能够重入(reentrant)且为在多线程中的使用作好准备。
函数 lua_open 创建一个新环境(或 state)。lua_open 创建一个新的环境时,这个环境并不包括预定义的函数,甚至是 print。为了保持 Lua 的苗条,所有的标准库以单独的包提供,所以如果你不需要就不会强求你使用它们。头文件 lualib.h 定义了打开这些库的函数。例如,调用 luaopen_io,以创建 io table 并注册 I/O 函数(io.read,io.write 等等)到 Lua 环境中。
创建一个 state 并将标准库载入之后,就可以着手解释用户的输入了。对于用户输入的每一行,C 程序首先调用 luaL_loadbuffer 编译这些 Lua 代码。如果没有错误,这个调用返回零并把编译之后的 chunk 压入栈。(记住,我们将在下一节中讨论魔法般的栈)之后,C 程序调用 lua_pcall,它将会把 chunk 从栈中弹出并在保护模式下运行它。和luaL_laodbuffer 一样,lua_pcall 在没有错误的情况下返回零。在有错误的情况下,这两个函数都将一条错误消息压入栈;我们可以用 lua_tostring 来得到这条信息、输出它,用lua_pop 将它从栈中删除。
注意,在有错误发生的情况下,这个程序简单的输出错误信息到标准错误流。在 C中,实际的错误处理可能是非常复杂的而且如何处理依赖于应用程序本身。Lua 核心决不会直接输出任何东西到任务输出流上;它通过返回错误代码和错误信息来发出错误信号。每一个应用程序都可以用最适合它们自己的方式来处理这些错误。为了讨论的简单,现在我们假想一个简单的错误处理方式,就象下面代码一样,它只是输出一条错误信息、关闭 Lua state、退出整个应用程序。
#include <stdarg.h>
#include <stdio.h>
#include <stdlib.h>
void error (lua_State *L, const char *fmt, ...) {
va_list argp;
va_start(argp, fmt);
vfprintf(stderr, argp);
va_end(argp);
lua_close(L);
exit(EXIT_FAILURE);
}
稍候我们再详细的讨论关于在应用代码中如何处理错误.因为你可以将Lua和C/C++代码一起编译,lua.h 并不包含这些典型的在其他 C 库中出现的整合代码:
#ifdef __cplusplus
extern "C" {
#endif
...
#ifdef __cplusplus
}
#endif
因此,如果你用 C 方式来编译它,但用在 C++中,那么你需要象下面这样来包含 lua.h头文件。
extern "C" {
#include <lua.h>
}
一个常用的技巧是建立一个包含上面代码的 lua.hpp 头文件,并将这个新的头文件包含进你的 C++程序。
堆栈
当在 Lua 和 C 之间交换数据时我们面临着两个问题:动态与静态类型系统的不匹配和自动与手动内存管理的不一致。
在 Lua 中,我们写下 a[k]=v 时,k 和 v 可以有几种不同的类型(由于 metatables 的存在,a 也可能有不同的类型)。如果我们想在 C 中提供类似的操作,无论怎样,操作表的函数(settable)必定有一个固定的类型。我们将需要几十个不同的函数来完成这一个的操作(三个参数的类型的每一种组合都需要一个函数)。
我们可以在 C 中声明一些 union 类型来解决这个问题,我们称之为 lua_Value,它能够描述所有类型的 Lua 值。然后,我们就可以这样声明 settable void lua_settable (lua_Value a, lua_Value k, lua_Value v);
这个解决方案有两个缺点。
第一,要将如此复杂的类型映射到其它语言可能很困难;Lua 不仅被设计为与 C/C++易于交互,Java,Fortran 以及类似的语言也一样。
第二,Lua负责垃圾回收:如果我们将 Lua 值保存在 C 变量中,Lua 引擎没有办法了解这种用法;它可能错误地认为某个值为垃圾并收集他。
因此,Lua API 没有定义任何类似 lua_Value 的类型。替代的方案,它用一个抽象的栈在 Lua 与 C 之间交换值。栈中的每一条记录都可以保存任何 Lua 值。无论你何时想要从 Lua 请求一个值(比如一个全局变量的值),调用 Lua,被请求的值将会被压入栈。无论你何时想要传递一个值给 Lua,首先将这个值压入栈,然后调用 Lua(这个值将被弹出)。我们仍然需要一个不同的函数将每种 C 类型压入栈和一个不同函数从栈上取值(译注:只是取出不是弹出),但是我们避免了组合式的爆炸(combinatorial explosion)。另外,因为栈是由 Lua 来管理的,垃圾回收器知道那个值正在被 C 使用。
几乎所有的 API函数都用到了栈。正如我们在第一个例子中所看到的,luaL_loadbuffer 把它的结果留在了栈上(被编译的 chunk 或一条错误信息);lua_pcall 从栈上获取要被调用的函数并把任何临时的错误信息放在这里。
Lua 以一个严格的 LIFO 规则(后进先出;也就是说,始终存取栈顶)来操作栈。当你调用 Lua 时,它只会改变栈顶部分。你的C代码却有更多的自由;更明确的来讲,你可以查询栈上的任何元素,甚至是在任何一个位置插入和删除元素。
压入元素
API 有一系列压栈的函数,它将每种可以用 C 来描述的 Lua 类型压栈:空值(nil)用 lua_pushnil,数值型(double)用 lua_pushnumber,布尔型(在 C 中用整数表示)用lua_pushboolean,任意的字符串(char类型,允许包含’\0’字符)用 lua_pushlstring,C语言风格(以’\0’结束)的字符串(const char)用 lua_pushstring:
void lua_pushnil (lua_State *L);
void lua_pushboolean (lua_State *L, int bool);
void lua_pushnumber (lua_State *L, double n);
void lua_pushlstring (lua_State *L, const char *s,
size_t length);
void lua_pushstring (lua_State *L, const char *s);
同样也有将 C 函数和 userdata 值压入栈的函数,稍后会讨论到它们。
Lua 中的字符串不是以零为结束符的;它们依赖于一个明确的长度,因此可以包含任意的二进制数据。将字符串压入串的正式函数是 lua_pushlstring,它要求一个明确的长度作为参数。对于以零结束的字符串,你可以用 lua_pushstring(它用 strlen 来计算字符串长度)。Lua 从来不保持一个指向外部字符串(或任何其它对象,除了 C 函数——它总是静态指针)的指针。对于它保持的所有字符串,Lua 要么做一份内部的拷贝要么重新利用已经存在的字符串。因此,一旦这些函数返回之后你可以自由的修改或是释放你的缓冲区。
无论你何时压入一个元素到栈上,你有责任确保在栈上有空间来做这件事情。记住,你现在是 C 程序员;Lua 不会宠着你。当 Lua 在起始以及在 Lua 调用 C 的时候,栈上至少有 20 个空闲的记录(lua.h 中的 LUA_MINSTACK 宏定义了这个常量)。对于多数普通的用法栈是足够的,所以通常我们不必去考虑它。无论如何,有些任务或许需要更多的栈空间(如,调用一个不定参数数目的函数)。在这种情况下,或许你需要调用下面这个函数:
int lua_checkstack (lua_State *L, int sz);
它检测栈上是否有足够你需要的空间(稍后会有关于它更多的信息)。
查询元素
API 用索引来访问栈中的元素。在栈中的第一个元素(也就是第一个被压入栈的)有索引 1,下一个有索引 2,以此类推。我们也可以用栈顶作为参照来存取元素,利用负索引。在这种情况下,-1 指出栈顶元素(也就是最后被压入的),-2 指出它的前一个元素,以此类推。例如,调用 lua_tostring(L, -1)以字符串的形式返回栈顶的值。我们下面将看到,在某些场合使用正索引访问栈比较方便,另外一些情况下,使用负索引访问栈更方便。
API 提供了一套 lua_is*函数来检查一个元素是否是一个指定的类型,*可以是任何Lua 类型。因此有 lua_isnumber,lua_isstring,lua_istable 以及类似的函数。所有这些函数都有同样的原型:
int lua_is... (lua_State *L, int index);
lua_isnumber 和 lua_isstring 函数不检查这个值是否是指定的类型,而是看它是否能被转换成指定的那种类型。例如,任何数字类型都满足 lua_isstring。
还有一个 lua_type 函数,它返回栈中元素的类型。(lua_is中的有些函数实际上是用了这个函数定义的宏)在 lua.h 头文件中,每种类型都被定义为一个常量:LUA_TNIL、LUA_TBOOLEAN 、 LUA_TNUMBER 、 LUA_TSTRING 、 LUA_TTABLE 、LUA_TFUNCTION、LUA_TUSERDATA 以及 LUA_TTHREAD。这个函数主要被用在与一个 switch 语句联合使用。当我们需要真正的检查字符串和数字类型时它也是有用的为了从栈中获得值,这里有 lua_to函数:
int lua_toboolean (lua_State *L, int index);
double lua_tonumber (lua_State *L, int index);
const char * lua_tostring (lua_State *L, int index);
size_t lua_strlen (lua_State *L, int index);
即使给定的元素的类型不正确,调用上面这些函数也没有什么问题。在这种情况下,lua_toboolean、lua_tonumber 和 lua_strlen 返回 0,其他函数返回 NULL。由于 ANSI C 没有提供有效的可以用来判断错误发生数字值,所以返回的 0 是没有什么用处的。对于其他函数而言,我们一般不需要使用对应的 lua_is函数:我们只需要调用 lua_is,测试返回结果是否为 NULL 即可。
Lua_tostring 函数返回一个指向字符串的内部拷贝的指针。你不能修改它(使你想起那里有一个 const)。只要这个指针对应的值还在栈内,Lua 会保证这个指针一直有效。
当一个 C 函数返回后,Lua 会清理他的栈,所以,有一个原则:永远不要将指向 Lua 字符串的指针保存到访问他们的外部函数中。
Lua_string 返回的字符串结尾总会有一个字符结束标志 0,但是字符串中间也可能包含 0,lua_strlen 返回字符串的实际长度。特殊情况下,假定栈顶的值是一个字符串,下面的断言(assert)总是有效的:
const char *s = lua_tostring(L, -1); /* any Lua string */
size_t l = lua_strlen(L, -1); /* its length */
assert(s[l] == '\0');
assert(strlen(s) <= l);
其他堆栈操作
除开上面所提及的 C 与堆栈交换值的函数外,API 也提供了下列函数来完成通常的堆栈维护工作:
int lua_gettop (lua_State *L);
void lua_settop (lua_State *L, int index);
void lua_pushvalue (lua_State *L, int index);
void lua_remove (lua_State *L, int index);
void lua_insert (lua_State *L, int index);
void lua_replace (lua_State *L, int index);
函数 lua_gettop 返回堆栈中的元素个数,它也是栈顶元素的索引。注意一个负数索引-x 对应于正数索引 gettop-x+1。lua_settop 设置栈顶(也就是堆栈中的元素个数)为一个指定的值。如果开始的栈顶高于新的栈顶,顶部的值被丢弃。否则,为了得到指定的大小这个函数压入相应个数的空值(nil)到栈上。特别的,lua_settop(L,0)清空堆栈。你也可以用负数索引作为调用 lua_settop 的参数;那将会设置栈顶到指定的索引。利用这种技巧,API 提供了下面这个宏,它从堆栈中弹出 n 个元素:
#define lua_pop(L,n) lua_settop(L, -(n)-1)
函数 lua_pushvalue 压入堆栈上指定索引的一个抟贝到栈顶;lua_remove 移除指定索引位置的元素,并将其上面所有的元素下移来填补这个位置的空白;lua_insert 移动栈顶元素到指定索引的位置,并将这个索引位置上面的元素全部上移至栈顶被移动留下的空隔;最后,lua_replace 从栈顶弹出元素值并将其设置到指定索引位置,没有任何移动操作。注意到下面的操作对堆栈没有任何影响:
lua_settop(L, -1); /* set top to its current value */
lua_insert(L, -1); /* move top element to the top */
为了说明这些函数的用法,这里有一个有用的帮助函数,它 dump 整个堆栈的内容:
static void stackDump (lua_State *L) {
int i;
int top = lua_gettop(L);
for (i = 1; i <= top; i++) { /* repeat for each level */
int t = lua_type(L, i);
switch (t) {
case LUA_TSTRING: /* strings */
printf("`%s'", lua_tostring(L, i));
break;
case LUA_TBOOLEAN: /* booleans */
printf(lua_toboolean(L, i) ? "true" : "false");
break;
case LUA_TNUMBER: /* numbers */
printf("%g", lua_tonumber(L, i));
break;
default: /* other values */
printf("%s", lua_typename(L, t));
break;
}
printf(" "); /* put a separator */
}
printf("\n"); /* end the listing */
}
这个函数从栈底到栈顶遍历了整个堆栈,依照每个元素自己的类型打印出其值。它用引号输出字符串;以%g 的格式输出数字;对于其它值(table,函数,等等)它仅仅输出它们的类型(lua_typename 转换一个类型码到类型名)。
下面的函数利用 stackDump 更进一步的说明了 API 堆栈的操作。
#include <stdio.h>
#include <lua.h>
static void stackDump (lua_State *L) {
...
}
int main (void) {
lua_State *L = lua_open();
lua_pushboolean(L, 1); lua_pushnumber(L, 10);
lua_pushnil(L); lua_pushstring(L, "hello");
stackDump(L);
/* true 10 nil `hello' */
lua_pushvalue(L, -4); stackDump(L);
/* true 10 nil `hello' true */
lua_replace(L, 3); stackDump(L);
/* true 10 true `hello' */
lua_settop(L, 6); stackDump(L);
/* true 10 true `hello' nil nil */
lua_remove(L, -3); stackDump(L);
/* true 10 true nil nil */
lua_settop(L, -5); stackDump(L);
/* true */
lua_close(L);
return 0;
}
C API 的错误处理
不象 C++或者 JAVA 一样,C 语言没有提供一种异常处理机制。为了改善这个难处,Lua 利用 C 的 setjmp 技巧构造了一个类似异常处理的机制。(如果你用 C++来编译 Lua,那么修改代码以使用真正的异常并不困难。)
Lua 中的所有结构都是动态的:它们按需增长,最终当可能时又会缩减。意味着内存分配失败的可能性在 Lua 中是普遍的。几乎任意操作都会面对这种意外。Lua 的 API中用异常发出这些错误而不是为每步操作产生错误码。这意味着所有的 API 函数可能抛出一个错误(也就是调用 longjmp)来代替返回。
当我们写一个库代码时(也就是被 Lua 调用的 C 函数)长跳转(long jump)的用处几乎和一个真正的异常处理一样的方便,因为 Lua 抓取了任务偶然的错误。当我们写应用程序代码时(也就是调用 Lua 的 C 代码),无论如何,我们必须提供一种方法来抓取这些错误。
应用程序中的错误处理
典型的情况是应用的代码运行在非保护模式下。由于应用的代码不是被 Lua 调用的,Lua 根据上下文情况来捕捉错误的发生(也就是说,Lua 不能调用 setjmp)。在这些情况下,当 Lua 遇到像 “not enough memory” 的错误,他不知道如何处理。他只能调用一个panic 函数退出应用。(你可以使用 lua_atpanic 函数设置你自己的 panic 函数)
不是所有的 API 函数都会抛出异常,lua_open、lua_close、lua_pcall 和 lua_load 都是安全的,另外,大多数其他函数只能在内存分配失败的情况下抛出异常:比如,luaL_loadfile 如果没有足够内存来拷贝指定的文件将会失败。有些程序当碰到内存不足时,他们可能需要忽略异常不做任何处理。对这些程序而言,如果 Lua 导致内存不足,panic 是没有问题的。
如果你不想你的应用退出,即使在内存分配失败的情况下,你必须在保护模式下运行你的代码。大部分或者所有你的 Lua 代码通过调用 lua_pcall 来运行,所以,它运行在保护模式下。即使在内存分配失败的情况下,lua_pcall 也返回一个错误代码,使得 lua解释器处于和谐的(consistent)状态。如果你也想保护所有你的与 Lua 交互的 C 代码,你可以使用 lua_cpcall。(请看参考手册,有对这个函数更深的描述,在 Lua 的发布版的lua.c 文件中有它应用的例子)
类库中的错误处理
Lua 是安全的语言,也就是说,不管你些什么样的代码,也不管代码如何错误,你都可以根据 Lua 本身知道程序的行为。另外,错误也会根据 Lua 被发现和解释。你可以与 C 比较一下,C 语言中很多错误的程序的行为只能依据硬件或者由程序计数器给出的错误出现的位置被解释。
不论什么时候你向 Lua 中添加一个新的 C 函数,你都可能打破原来的安全性。比如,一个类似 poke 的函数,在任意的内存地址存放任意的字节,可能使得内存瘫痪。你必须想法设法保证你的插件(add-ons)对于 Lua 来讲是安全的,并且提高比较好的错误处理。
正如我们前面所讨论的,每一个 C 程序都有他自己的错勿处理方式,当你打算为Lua 写一个库函数的时候,这里有一些标准的处理错误的方法可以参考。不论什么时候,C 函数发现错误只要简单的调用 lua_error(或者 luaL_error,后者更好,因为她调用了前者并格式化了错误信息)。Lua_error 函数会清理所有在 Lua 中需要被清理的,然后和错误信息一起回到最初的执行 lua_pcall 的地方。
扩展你的程序
作为配置语言是 LUA 的一个重要应用。在这个章节里,我们举例说明如何用 LUA 设置一个程序。让我们用一个简单的例子开始然后展开到更复杂的应用中。
首先,让我们想象一下一个简单的配置情节:你的 C 程序(程序名为 PP)有一个窗口界面并且可以让用户指定窗口的初始大小。显然,类似这样简单的应用,有多种解决方法比使用 LUA 更简单,比如环境变量或者存有变量值的文件。但,即使是用一个简单的文本文件,你也不知道如何去解析。所以,最后决定采用一个 LUA 配置文件(这就是 LUA 程序中的纯文本文件)。在这种简单的文本形式中通常包含类似如下的信息行:
-- configuration file for program `pp'
-- define window size
width = 200
height = 300
现在,你得调用 LUA API 函数去解析这个文件,取得 width 和 height 这两个全局变量的值。下面这个取值函数就起这样的作用:
#include <lua.h>
#include <lauxlib.h>
#include <lualib.h>
void load (char *filename, int *width, int *height) {
lua_State *L = lua_open();
luaopen_base(L);
luaopen_io(L);
luaopen_string(L);
luaopen_math(L);
if (luaL_loadfile(L, filename) || lua_pcall(L, 0, 0, 0))
error(L, "cannot run configuration file: %s", lua_tostring(L, -1));
lua_getglobal(L, "width");
lua_getglobal(L, "height");
if (!lua_isnumber(L, -2))
error(L, "`width' should be a number\n");
if (!lua_isnumber(L, -1))
error(L, "`height' should be a number\n");
*width = (int)lua_tonumber(L, -2);
*height = (int)lua_tonumber(L, -1);
lua_close(L);
}
首先,程序打开 LUA 包并加载了标准函数库(虽然这是可选的,但通常包含这些库是比较好的编程思想)。然后程序使用 luaL_loadfile 方法根据参数 filename 加载此文件中的信息块并调用 lua_pcall 函数运行,这些函数运行时若发生错误(例如配置文件中有语法错误),将返回非零的错误代码并将此错误信息压入栈中。通常,我们用带参数 index值为-1 的 lua_tostring 函数取得栈顶元素(error 函数我们已经在 24.1 章节中定义)。
解析完取得的信息块后,程序会取得全局变量值。为此,程序调用了两次lua_getglobal 函数,其中一参数为变量名称。每调用一次就把相应的变量值压入栈顶,所以变量 width 的 index 值是-2 而变量 height 的 index 值是-1(在栈顶)。(因为先前的栈是空的,需要从栈底重新索引,1 表示第一个元素 2 表示第二个元素。由于从栈顶索引,不管栈是否为空,你的代码也能运行)。接着,程序用 lua_isnumber 函数判断每个值是否为数字。lua_tonumber 函数将得到的数值转换成 double 类型并用(int)强制转换成整型。最后,关闭数据流并返回值。
Lua 是否值得一用?正如我前面提到的,在这个简单的例子中,相比较于 lua 用一个只包含有两个数字的文件会更简单。即使如此,使用 lua 也带来了一些优势。首先,它为你处理所有的语法细节(包括错误);你的配置文件甚至可以包含注释!其次,用可以用 lua 做更多复杂的配置。例如,脚本可以向用户提示相关信息,或者也可以查询环境变量以选择合适的大小:
-- configuration file for program 'pp'
if getenv("DISPLAY") == ":0.0" then
width = 300; height = 300
else
width = 200; height = 200
end
在这样简单的配置情节中,很难预料用户想要什么;不过只要脚本定义了这两个变量,你的 C 程序无需改变就可运行。
最后一个使用 lua 的理由:在你的程序中很容易的加入新的配置单元。方便的属性添加使程序更具有扩展性。
表操作
现在,我们打算使用 Lua 作为配置文件,配置窗口的背景颜色。我们假定最终的颜色有三个数字(RGB)描述,每一个数字代表颜色的一部分。通常,在 C 语言中,这些数字使用[0,255]范围内的整数表示,由于在 Lua 中所有数字都是实数,我们可以使用更自然的范围[0,1]来表示。
一个粗糙的解决方法是,对每一个颜色组件使用一个全局变量表示,让用户来配置这些变量:
-- configuration file for program 'pp'
width = 200
height = 300
background_red = 0.30
background_green = 0.10
background_blue = 0
这个方法有两个缺点:第一,太冗余(为了表示窗口的背景,窗口的前景,菜单的背景等,一个实际的应用程序可能需要几十个不同的颜色);第二,没有办法预定义共同部分的颜色,比如,假如我们事先定义了WHITE,用户可以简单的写background = WHITE来表示所有的背景色为白色。为了避免这些缺点,我们使用一个 table 来表示颜色:
background = {r=0.30, g=0.10, b=0}
表的使用给脚本的结构带来很多灵活性,现在对于用户(或者应用程序)很容易预定义一些颜色,以便将来在配置中使用:
BLUE = {r=0, g=0, b=1}
...
background = BLUE
为了在 C 中获取这些值,我们这样做:
lua_getglobal(L, "background");
if (!lua_istable(L, -1))
error(L, "`background' is not a valid color table");
red = getfield("r");
green = getfield("g");
blue = getfield("b");
一般来说,我们首先获取全局变量 backgroud 的值,并保证它是一个 table。然后,我们使用 getfield 函数获取每一个颜色组件。这个函数不是 API 的一部分,我们需要自己定义他:
#define MAX_COLOR 255
/* assume that table is on the stack top */
int getfield (const char *key) {
int result;
lua_pushstring(L, key);
lua_gettable(L, -2); /* get background[key] */
//上面两行可以替换为:lua_gettable(L,-1,key)
if (!lua_isnumber(L, -1))
error(L, "invalid component in background color");
result = (int)lua_tonumber(L, -1) * MAX_COLOR;
lua_pop(L, 1); /* remove number */
return result;
}
这里我们再次面对多态的问题:可能存在很多个 getfield 的版本,key 的类型,value的类型,错误处理等都不尽相同。Lua API 只提供了一个 lua_gettable 函数,他接受 table在栈中的位置为参数,将对应 key 值出栈,返回与 key 对应的 value。
我们上面的 getfield函数假定 table 在栈顶,因此,lua_pushstring 将 key 入栈之后,table 在-2 的位置。返回之前,getfield 会将栈恢复到调用前的状态。
我们对上面的例子稍作延伸,加入颜色名。用户仍然可以使用颜色 table,但是也可以为共同部分的颜色预定义名字,为了实现这个功能,我们在 C 代码中需要一个颜色
table:
struct ColorTable {
char *name;
unsigned char red, green, blue;
} colortable[] = {
{"WHITE", MAX_COLOR, MAX_COLOR, MAX_COLOR},
{"RED", MAX_COLOR, 0, 0},
{"GREEN", 0, MAX_COLOR, 0},
{"BLUE", 0, 0, MAX_COLOR},
{"BLACK", 0, 0, 0},
...
{NULL, 0, 0, 0} /* sentinel */
};
我们的这个实现会使用颜色名创建一个全局变量,然后使用颜色 table 初始化这些全局变量。结果和用户在脚本中使用下面这几行代码是一样的:
WHITE = {r=1, g=1, b=1}
RED = {r=1, g=0, b=0}
...
脚本中用户定义的颜色和应用中(C 代码)定义的颜色不同之处在于:应用在脚本之前运行。
为了可以设置 table 域的值,我们定义个辅助函数 setfield;这个函数将 field 的索引和 field 的值入栈,然后调用 lua_settable:
/* assume that table is at the top */
void setfield (const char *index, int value) {
lua_pushstring(L, index);
lua_pushnumber(L, (double)value/MAX_COLOR);
lua_settable(L, -3);
//上下两行可以替换成:lua_setfield(L,-2,index);
}
与其他的 API 函数一样,lua_settable 在不同的参数类型情况下都可以使用,他从栈中获取所有的参数。lua_settable 以 table 在栈中的索引作为参数,并将栈中的 key 和 value出栈,用这两个值修改 table。Setfield 函数假定调用之前 table 是在栈顶位置(索引为-1)。 将 index 和 value 入栈之后,table 索引变为-3。
Setcolor 函数定义一个单一的颜色,首先创建一个 table,然后设置对应的域,然后将这个 table 赋值给对应的全局变量:
void setcolor (struct ColorTable *ct) {
lua_newtable(L); /* creates a table */
setfield("r", ct->red); /* table.r = ct->r */
setfield("g", ct->green); /* table.g = ct->g */
setfield("b", ct->blue); /* table.b = ct->b */
lua_setglobal(ct->name); /* 'name' = table */
}
lua_newtable 函数创建一个新的空 table 然后将其入栈,调用 setfield 设置 table 的域,最后 lua_setglobal 将 table 出栈并将其赋给一个全局变量名。
有了前面这些函数,下面的循环注册所有的颜色到应用程序中的全局变量:
int i = 0;
while (colortable[i].name != NULL)
setcolor(&colortable[i++]);
记住:应用程序必须在运行用户脚本之前,执行这个循环。
对于上面的命名颜色的实现有另外一个可选的方法。用一个字符串来表示颜色名,而不是上面使用全局变量表示,比如用户可以这样设置 background = “BLUE”。所以,background 可以是 table 也可以是 string。对于这种实现,应用程序在运行用户脚本之前不需要做任何特殊处理。但是需要额外的工作来获取颜色。当他得到变量 background 的值之后,必须判断这个值的类型,是 table 还是 string:
lua_getglobal(L, "background");
if (lua_isstring(L, -1)) {
const char *name = lua_tostring(L, -1);
int i = 0;
while (colortable[i].name != NULL &&
strcmp(colorname, colortable[i].name) != 0)
i++;
if (colortable[i].name == NULL) /* string not found? */
error(L, "invalid color name (%s)", colorname);
else { /* use colortable[i] */
red = colortable[i].red;
green = colortable[i].green;
blue = colortable[i].blue;
}
} else if (lua_istable(L, -1)) {
red = getfield("r");
green = getfield("g");
blue = getfield("b");
} else
error(L, "invalid value for `background'");
哪个是最好的选择呢?在 C 程序中,使用字符串表示不是一个好的习惯,因为编译器不会对字符串进行错误检查。然而在 Lua 中,全局变量不需要声明,因此当用户将颜色名字拼写错误的时候,Lua 不会发出任何错误信息。比如,用户将 WHITE 误写成 WITE,background 变量将为 nil(WITE 的值没有初始化),然后应用程序就认为 background 的值为 nil。没有其他关于这个错误的信息可以获得。另一方面,使用字符串表示,background的值也可能是拼写错了的字符串。因此,应用程序可以在发生错误的时候,定制输出的错误信息。应用可以不区分大小写比较字符串,因此,用户可以写"white",“WHITE”,甚至"White"。但是,如果用户脚本很小,并且颜色种类比较多,注册成百上千个颜色(需要创建成百上千个 table 和全局变量),最终用户可能只是用其中几个,这会让人觉得很怪异。在使用字符串表示的时候,应避免这种情况出现。
调用 Lua 函数
Lua 作为配置文件的一个最大的长处在于它可以定义个被应用调用的函数。比如,你可以写一个应用程序来绘制一个函数的图像,使用 Lua 来定义这个函数。
使用 API 调用函数的方法是很简单的:
首先,将被调用的函数入栈;
第二,依次将所有参数入栈;
第三,使用 lua_pcall 调用函数;
最后,从栈中获取函数执行返回的结果。
看一个例子,假定我们的配置文件有下面这个函数:
function f (x, y)
return (x^2 * math.sin(y))/(1 - x)
end
并且我们想在 C 中对于给定的 x,y 计算 z=f(x,y)的值。假如你已经打开了 lua 库并且运行了配置文件,你可以将这个调用封装成下面的 C 函数:
/* call a function `f' defined in Lua */
double f (double x, double y) {
double z;
/* push functions and arguments */
lua_getglobal(L, "f"); /* function to be called */
lua_pushnumber(L, x); /* push 1st argument */
lua_pushnumber(L, y); /* push 2nd argument */
/* do the call (2 arguments, 1 result) */
if (lua_pcall(L, 2, 1, 0) != 0)
error(L, "error running function `f': %s",
lua_tostring(L, -1));
/* retrieve result */
if (!lua_isnumber(L, -1))
error(L, "function `f' must return a number");
z = lua_tonumber(L, -1);
lua_pop(L, 1); /* pop returned value */
return z;
}
可以调用 lua_pcall 时指定参数的个数和返回结果的个数。第四个参数可以指定一个错误处理函数,我们下面再讨论它。和 Lua 中赋值操作一样,lua_pcall 会根据你的要求调整返回结果的个数,多余的丢弃,少的用 nil 补足。在将结果入栈之前,lua_pcall 会将栈内的函数和参数移除。如果函数返回多个结果,第一个结果被第一个入栈,因此如果有 n 个返回结果,第一个返回结果在栈中的位置为-n,最后一个返回结果在栈中的位置为-1。
如果 lua_pcall 运行时出现错误,lua_pcall 会返回一个非 0 的结果。另外,他将错误信息入栈(仍然会先将函数和参数从栈中移除)。在将错误信息入栈之前,如果指定了错误处理函数,lua_pcall 毁掉用错误处理函数。使用 lua_pcall 的最后一个参数来指定错误处理函数,0 代表没有错误处理函数,也就是说最终的错误信息就是原始的错误信息。否则,那个参数应该是一个错误函数被加载的时候在栈中的索引,注意,在这种情况下,错误处理函数必须要在被调用函数和其参数入栈之前入栈。
对于一般错误,lua_pcall 返回错误代码 LUA_ERRRUN。有两种特殊情况,会返回特殊的错误代码,因为他们从来不会调用错误处理函数。第一种情况是,内存分配错误,对于这种错误,lua_pcall 总是返回 LUA_ERRMEM。第二种情况是,当 Lua 正在运行错误处理函数时发生错误,这种情况下,再次调用错误处理函数没有意义,所以 lua_pcall立即返回错误代码 LUA_ERRERR。
通用的Lua函数调用
看一个稍微高级的例子,我们使用 C 的 vararg 来封装对 Lua 函数的调用。我们的封装后的函数(call_va)接受被调用的函数明作为第一个参数,第二参数是一个描述参数和结果类型的字符串,最后是一个保存返回结果的变量指针的列表。使用这个函数,我们可以将前面的例子改写为:
call_va("f", "dd>d", x, y, &z);
字符串 “dd>d” 表示函数有两个 double 类型的参数,一个 double 类型的返回结果。我们使用字母 ‘d’ 表示 double;‘i’ 表示 integer,‘s’ 表示 strings;’>’ 作为参数和结果的分隔符。如果函数没有返回结果,’>’ 是可选的。
#include <stdarg.h>
void call_va (const char *func, const char *sig, ...) {
va_list vl;
int narg, nres; /* number of arguments and results */
va_start(vl, sig);
lua_getglobal(L, func); /* get function */
/* push arguments */
narg = 0;
while (*sig) { /* push arguments */
switch (*sig++) {
case 'd': /* double argument */
lua_pushnumber(L, va_arg(vl, double));
break;
case 'i': /* int argument */
lua_pushnumber(L, va_arg(vl, int));
break;
case 's': /* string argument */
lua_pushstring(L, va_arg(vl, char *));
break;
case '>':
goto endwhile;
default:
error(L, "invalid option (%c)", *(sig - 1));
}
narg++;
luaL_checkstack(L, 1, "too many arguments");
} endwhile:
/* do the call */
nres = strlen(sig); /* number of expected results */
if (lua_pcall(L, narg, nres, 0) != 0) /* do the call */
error(L, "error running function `%s': %s",
func, lua_tostring(L, -1));
/* retrieve results */
nres = -nres; /* stack index of first result */
while (*sig) { /* get results */
switch (*sig++) {
case 'd': /* double result */
if (!lua_isnumber(L, nres))
error(L, "wrong result type");
*va_arg(vl, double *) = lua_tonumber(L, nres);
break;
case 'i': /* int result */
if (!lua_isnumber(L, nres))
error(L, "wrong result type");
va_arg(vl, int *) = (int)lua_tonumber(L, nres);
break;
case 's': /* string result */
if (!lua_isstring(L, nres))
error(L, "wrong result type");
*va_arg(vl, const char **) = lua_tostring(L, nres);
break;
default:
error(L, "invalid option (%c)", *(sig - 1));
}
nres++;
}
va_end(vl);
}
尽管这段代码具有一般性,这个函数和前面我们的例子有相同的步骤:将函数入栈,参数入栈,调用函数,获取返回结果。大部分代码都很直观,但也有一点技巧。首先,不需要检查 func 是否是一个函数,lua_pcall 可以捕捉这个错误。第二,可以接受任意多个参数,所以必须检查栈的空间。第三,因为函数可能返回字符串,call_va 不能从栈中弹出结果,在调用者获取临时字符串的结果之后(拷贝到其他的变量中),由调用者负责弹出结果。
调用 C 函数
扩展 Lua 的基本方法之一就是为应用程序注册新的 C 函数到 Lua 中去。
当我们提到 Lua 可以调用 C 函数,不是指 Lua 可以调用任何类型的 C 函数(有一些包可以让 Lua 调用任意的 C 函数,但缺乏便捷和健壮性)。正如我们前面所看到的,当C 调用 Lua 函数的时候,必须遵循一些简单的协议来传递参数和获取返回结果。相似的,从 Lua 中调用 C 函数,也必须遵循一些协议来传递参数和获得返回结果。另外,从 Lua调用 C 函数我们必须注册函数,也就是说,我们必须把 C 函数的地址以一个适当的方式传递给 Lua 解释器。
当 Lua 调用 C 函数的时候,使用和 C 调用 Lua 相同类型的栈来交互。C 函数从栈中获取她的参数,调用结束后将返回结果放到栈中。为了区分返回结果和栈中的其他的值,每个 C 函数还会返回结果的个数(the function returns (in C) the number of results it is leaving on the stack.)。这儿有一个重要的概念:用来交互的栈不是全局变量,每一个函数都有他自己的私有栈。当 Lua 调用 C 函数的时候,第一个参数总是在这个私有栈的index=1 的位置。甚至当一个 C 函数调用 Lua 代码(Lua 代码调用同一个 C 函数或者其他的 C 函数),每一个 C 函数都有自己的独立的私有栈,并且第一个参数在 index=1 的位置。
C 函数
先看一个简单的例子,如何实现一个简单的函数返回给定数值的 sin 值(更专业的实现应该检查他的参数是否为一个数字):
static int l_sin (lua_State *L) {
double d = lua_tonumber(L, 1); /* get argument */
lua_pushnumber(L, sin(d)); /* push result */
return 1; /* number of results */
}
任何在 Lua 中注册的函数必须有同样的原型,这个原型声明定义就是 lua.h 中的lua_CFunction:
typedef int (*lua_CFunction) (lua_State *L);
从 C 的角度来看,一个 C 函数接受单一的参数 Lua state,返回一个表示返回值个数的数字。所以,函数在将返回值入栈之前不需要清理栈,函数返回之后,Lua 自动的清除栈中返回结果下面的所有内容。
我们要想在 Lua 使用这个函数,还必须首先注册这个函数。我们使用lua_pushcfunction 来完成这个任务:他获取指向 C 函数的指针,并在 Lua 中创建一个function 类型的值来表示这个函数。一个 quick-and-dirty 的解决方案是将这段代码直接放到 lua.c 文件中,并在调用lua_open 后面适当的位置加上下面两行:
lua_State *L = luaL_newstate(); //打开Lua
luaL_openlibs(L); //打开lua库
lua_pushcfunction(L, l_sin);
lua_setglobal(L, "mysin");
第一行将类型为 function 的值入栈,第二行将 function 赋值给全局变量 mysin。这样修改之后,重新编译 Lua,你就可以在你的 Lua 程序中使用新的 mysin 函数了。在下面一节,我们将讨论以比较好的方法将新的 C 函数添加到 Lua 中去。
对于稍微专业点的 sin 函数,我们必须检查 sin 的参数的类型。有一个辅助库中的luaL_checknumber 函数可以检查给定的参数是否为数字:当有错误发生的时候,将抛出一个错误信息;否则返回作为参数的那个数字。将上面我们的函数稍作修改:
static int l_sin (lua_State *L) {
double d = luaL_checknumber(L, 1);
lua_pushnumber(L, sin(d));
return 1; /* number of results */
}
根据上面的定义,如果你调用 mysin(‘a’),会得到如下信息:
bad argument #1 to 'mysin' (number expected, got string)
注意看看 luaL_checknumber 是如何自动使用:参数 number(1),函数名(“mysin”),期望的参数类型(“number”),实际的参数类型(“string”)来拼接最终的错误信息的。
下面看一个稍微复杂的例子:写一个返回给定目录内容的函数。Lua 的标准库并没有提供这个函数,因为 ANSI C 没有可以实现这个功能的函数。在这儿,我们假定我们的系统符合 POSIX 标准。我们的 dir 函数接受一个代表目录路径的字符串作为参数,以数组的形式返回目录的内容。比如,调用 dir("/home/lua")可能返回{".", “…”, “src”, “bin”, “lib”}。当有错误发生的时候,函数返回 nil 加上一个描述错误信息的字符串。
#include <dirent.h>
#include <errno.h>
static int l_dir (lua_State *L) {
DIR *dir;
struct dirent *entry;
int i;
const char *path = luaL_checkstring(L, 1);
/* open directory */
dir = opendir(path);
if (dir == NULL) { /* error opening the directory? */
lua_pushnil(L); /* return nil and ... */
lua_pushstring(L, strerror(errno)); /* error message */
return 2; /* number of results */
}
/* create result table */
lua_newtable(L);
i = 1;
while ((entry = readdir(dir)) != NULL) {
lua_pushnumber(L, i++); /* push key */
lua_pushstring(L, entry->d_name); /* push value */
lua_settable(L, -3);
}
closedir(dir);
return 1; /* table is already on top */
}
辅助库的 luaL_checkstring 函数用来检测参数是否为字符串,与 luaL_checknumber类似。(在极端情况下,上面的 l_dir 的实现可能会导致小的内存泄漏。调用的三个 Lua函数 lua_newtable、lua_pushstring 和 lua_settable 可能由于没有足够的内存而失败。其中任何一个调用失败都会抛出错误并且终止 l_dir,这种情况下,不会调用 closedir。正如前面我们所讨论过的,对于大多数程序来说这不算个问题:如果程序导致内存不足,最好的处理方式是立即终止程序。另外,在 29 章我们将看到另外一种解决方案可以避免这个问题的发生)
C 函数库
一个 Lua 库实际上是一个定义了一系列 Lua 函数的 chunk,并将这些函数保存在适当的地方,通常作为 table 的域来保存。Lua 的 C 库就是这样实现的。除了定义 C 函数之外,还必须定义一个特殊的用来和 Lua 库的主 chunk 通信的特殊函数。一旦调用,这个函数就会注册库中所有的 C 函数,并将他们保存到适当的位置。像一个 Lua 主 chunk一样,她也会初始化其他一些在库中需要初始化的东西。
Lua 通过这个注册过程,就可以看到库中的 C 函数。一旦一个 C 函数被注册之后并保存到 Lua 中,在 Lua 程序中就可以直接引用他的地址(当我们注册这个函数的时候传递给 Lua 的地址)来访问这个函数了。换句话说,一旦 C 函数被注册之后,Lua 调用这个函数并不依赖于函数名,包的位置,或者调用函数的可见的规则。通常 C 库都有一个外部(public/extern)的用来打开库的函数。其他的函数可能都是私有的,在 C 中被声明为 static。
当你打算使用 C 函数来扩展 Lua 的时候,即使你仅仅只想注册一个 C 函数,将你的C 代码设计为一个库是个比较好的思想:不久的将来你就会发现你需要其他的函数。一般情况下,辅助库对这种实现提供了帮助。luaL_openlib 函数接受一个 C 函数的列表和他们对应的函数名,并且作为一个库在一个 table 中注册所有这些函数。看一个例子,假定我们想用一个我们前面提过的 l_dir 函数创建一个库。首先,我们必须定义库函数:
static int l_dir (lua_State *L) {
... /* as before */
}
第二步,我们声明一个数组,保存所有的函数和他们对应的名字。这个数组的元素类型为 luaL_reg:是一个带有两个域的结构体,一个字符串和一个函数指针。
static const struct luaL_reg mylib [] = {
{"dir", l_dir},
{NULL, NULL} /* sentinel */
};
在我们的例子中,只有一个函数 l_dir 需要声明。注意数组中最后一对必须是{NULL, NULL},用来表示结束。第三步,我们使用 luaL_openlib 声明主函数:
int luaopen_mylib (lua_State *L) {
luaL_openlib(L, "mylib", mylib, 0); //luaL_register(L, "mylib", mylib)
return 1;
}
luaL_openlib 的第二个参数是库的名称。这个函数按照指定的名字创建(或者 reuse)一个表,并使用数组 mylib 中的 name-function 对填充这个表。luaL_openlib 还允许我们为库中所有的函数注册公共的 upvalues。例子中不需要使用 upvalues,所以最后一个参数为 0luaL_openlib 返回的时候,将保存库的表放到栈内。luaL_openlib 函数返回 1,返回这个值给 Lua。(The luaopen_mylib function returns 1 to return this value to Lua)(和Lua 库一样,这个返回值是可选的,因为库本身已经赋给了一个全局变量。另外,像在Lua 标准库中的一样,这个返回不会有额外的花费,在有时候可能是有用的。)
完成库的代码编写之后,我们必须将它链接到 Lua 解释器。最常用的方式使用动态连接库,如果你的 Lua 解释器支持这个特性的话(我们在 8.2 节已经讨论过了动态连接库)。在这种情况下,你必须用你的代码创建动态连接库(windows 下.dll 文件,linux 下.so文件)。到这一步,你就可以在 Lua 中直接使用 loadlib 加载你刚才定义的函数库了,下面这个调用:
mylib = loadlib("fullname-of-your-library", "luaopen_mylib")
将 luaopen_mylib 函数转换成 Lua 中的一个 C 函数,并将这个函数赋值给 mylib(那就是为什么 luaopen_mylib 必须和其他的 C 函数有相同的原型的原因所在)。然后,调用mylib(),将运行 luaopen_mylib 打开你定义的函数库。
此时在Lua中调用require "mylib"即可调用C++函数了
如果你的解释器不支持动态链接库,你必须将你的新的函数库重新编译到你的 Lua中去。
除了这以外,还不要一些方式告诉独立运行的 Lua 解释器,当他打开一个新的状态的时候必须打开这个新定义的函数库。宏定义可以很容易实现这个功能。第一,你必须使用下面的内容创建一个头文件(我们可以称之为 mylib.h):
int luaopen_mylib (lua_State *L);
#define LUA_EXTRALIBS { "mylib", luaopen_mylib },
第一行声明了打开库的函数。第二行定义了一个宏 LUA_EXTRALIBS 作为函数数组的新的入口,当解释器创建新的状态的时候会调用这个宏。(这个函数数组的类型为struct luaL_reg[],因此我们需要将名字也放进去)
为了在解释器中包含这个头文件,你可以在你的编译选项中定义一个宏LUA_USERCONFIG。对于命令行的编译器,你只需添加一个下面这样的选项即可:
-DLUA_USERCONFIG=\"mylib.h\"
(反斜线防止双引号被 shell 解释,当我们在 C 中指定一个头文件时,这些引号是必需的。)在一个整合的开发环境中,你必须在工程设置中添加类似的东西。然后当你重新编译 lua.c 的时候,它包含 mylib.h,并且因此在函数库的列表中可以用新定义的LUA_EXTRALIBS 来打开函数库。
Lua调用C模块的步骤:
- 创建C模块
- 将C模块编译生成一个动态链接库(.dll)
- 在lua中require”动态链接库名称“(不需要扩展名.dll)
- 可以在lua中使用C模块中定义的函数了
撰写 C 函数的技巧
官方的 API 和辅助函数库 都提供了一些帮助程序员如何写好 C 函数的机制。在这一章我们将讨论数组操纵、string 处理、在 C 中存储 Lua 值等一些特殊的机制。
数组操作
Lua 中数组实际上就是以特殊方式使用的 table 的别名。我们可以使用任何操纵 table的函数来对数组操作,即 lua_settable 和 lua_gettable。然而,与 Lua 常规简洁思想(economy and simplicity)相反的是,API 为数组操作提供了一些特殊的函数。这样做的原因出于性能的考虑:因为我们经常在一个算法(比如排序)的循环的内层访问数组,所以这种内层操作的性能的提高会对整体的性能的改善有很大的影响。
API 提供了下面两个数组操作函数:
void lua_rawgeti (lua_State *L, int index, int key);
void lua_rawseti (lua_State *L, int index, int key);
关于的 lua_rawgeti 和 lua_rawseti 的描述有些使人糊涂,因为它涉及到两个索引:index 指向 table 在栈中的位置;key 指向元素在 table 中的位置。当 t 使用负索引的时候(otherwise,you must compensate for the new item in the stack),调用 lua_rawgeti(L,t,key)等价于:
lua_pushnumber(L, key);
lua_rawget(L, t);
调用 lua_rawseti(L, t, key)(也要求 t 使用负索引)等价于:
lua_pushnumber(L, key);
lua_insert(L, -2); /* put 'key' below previous value */
lua_rawset(L, t);
注意这两个寒暑都是用 raw 操作,他们的速度较快,总之,用作数组的 table 很少使用 metamethods。
下面看如何使用这些函数的具体的例子,我们将前面的 l_dir 函数的循环体:
lua_pushnumber(L, i++); /* key */
lua_pushstring(L, entry->d_name); /* value */
lua_settable(L, -3);
改写为:
lua_pushstring(L, entry->d_name); /* value */
lua_rawseti(L, -2, i++); /* set table at key 'i' */
下面是一个更完整的例子,下面的代码实现了 map 函数:以数组的每一个元素为参数调用一个指定的函数,并将数组的该元素替换为调用函数返回的结果。
int l_map (lua_State *L) {
int i, n;
/* 1st argument must be a table (t) */
luaL_checktype(L, 1, LUA_TTABLE);
/* 2nd argument must be a function (f) */
luaL_checktype(L, 2, LUA_TFUNCTION);
n = luaL_getn(L, 1); /* get size of table */
for (i=1; i<=n; i++) {
lua_pushvalue(L, 2); /* push f */
lua_rawgeti(L, 1, i); /* push t[i] */
lua_call(L, 1, 1); /* call f(t[i]) */
lua_rawseti(L, 1, i); /* t[i] = result */
}
return 0; /* no results */
}
这里面引入了三个新的函数。luaL_checktype(在 lauxlib.h 中定义)用来检查给定的参数有指定的类型;否则抛出错误。luaL_getn 函数栈中指定位置的数组的大小(table.getn是调用 luaL_getn 来完成工作的)。lua_call 的运行是无保护的,他与 lua_pcall 相似,但是在错误发生的时候她抛出错误而不是返回错误代码。当你在应用程序中写主流程的代码时,不应该使用 lua_call,因为你应该捕捉任何可能发生的错误。当你写一个函数的代码时,使用 lua_call 是比较好的想法,如果有错误发生,把错误留给关心她的人去处理。
字符串处理
当 C 函数接受一个来自 lua 的字符串作为参数时,有两个规则必须遵守:当字符串正在被访问的时候不要将其出栈;永远不要修改字符串。
当 C 函数需要创建一个字符串返回给 lua 的时候,情况变得更加复杂。这样需要由C 代码来负责缓冲区的分配和释放,负责处理缓冲溢出等情况。然而,Lua API 提供了一些函数来帮助我们处理这些问题。
标准 API 提供了对两种基本字符串操作的支持:子串截取和字符串连接。记住,lua_pushlstring 可以接受一个额外的参数,字符串的长度来实现字符串的截取,所以,如果你想将字符串 s 从 i 到 j 位置(包含 i 和 j)的子串传递给 lua,只需要:
lua_pushlstring(L, s+i, j-i+1);
下面这个例子,假如你想写一个函数来根据指定的分隔符分割一个字符串,并返回一个保存所有子串的 table,比如调用:
split("hi,,there", ",")
应该返回表{“hi”, “”, “there”}。我们可以简单的实现如下,下面这个函数不需要额外的缓冲区,可以处理字符串的长度也没有限制。
static int l_split (lua_State *L) {
const char *s = luaL_checkstring(L, 1);
const char *sep = luaL_checkstring(L, 2);
const char *e;
int i = 1;
lua_newtable(L); /* result */
/* repeat for each separator */
while ((e = strchr(s, *sep)) != NULL) {
lua_pushlstring(L, s, e-s); /* push substring */
lua_rawseti(L, -2, i++);
s = e + 1; /* skip separator */
}
/* push last substring */
lua_pushstring(L, s);
lua_rawseti(L, -2, i);
return 1; /* return the table */
}
在 Lua API 中提供了专门的用来连接字符串的函数 lua_concat。等价于 Lua 中的…操作符:自动将数字转换成字符串,如果有必要的时候还会自动调用 metamethods。另外,她可以同时连接多个字符串。调用 lua_concat(L,n)将连接(同时会出栈)栈顶的 n 个值,并将最终结果放到栈顶。
另一个有用的函数是 lua_pushfstring:
const char *lua_pushfstring (lua_State *L, const char *fmt, ...); //类似Csprintf
这个函数某种程度上类似于 C 语言中的 sprintf,根据格式串 fmt 的要求创建一个新的字符串。与 sprintf 不同的是,你不需要提供一个字符串缓冲数组,Lua 为你动态的创建新的字符串,按他实际需要的大小。也不需要担心缓冲区溢出等问题。这个函数会将结果字符串放到栈内,并返回一个指向这个结果串的指针。当前,这个函数只支持下列几个指示符: %%(表示字符 ‘%’)、%s(用来格式化字符串)、%d(格式化整数)、%f(格式化 Lua 数字,即 doubles)和 %c(接受一个数字并将其作为字符),不支持宽度和精度等选项。
当我们打算连接少量的字符串的时候,lua_concat 和 lua_pushfstring 是很有用的,然而,如果我们需要连接大量的字符串(或者字符),这种一个一个的连接方式效率是很低的,正如我们在 11.6 节看到的那样。我们可以使用辅助库提供的 buffer 相关函数来解决这个问题。Auxlib 在两个层次上实现了这些 buffer。第一个层次类似于 I/O 操作的 buffers:集中所有的字符串(或者但个字符)放到一个本地 buffer 中,当本地 buffer 满的时候将其传递给 Lua(使用 lua_pushlstring)。第二个层次使用 lua_concat 和我们在 11.6 节中看到的那个栈算法的变体,来连接多个 buffer 的结果。
为了更详细地描述 Auxlib 中的 buffer 的使用,我们来看一个简单的应用。下面这段代码显示了 string.upper 的实现(来自文件 lstrlib.c):
static int str_upper (lua_State *L) {
size_t l;
size_t i;
luaL_Buffer b;
const char *s = luaL_checklstr(L, 1, &l);
luaL_buffinit(L, &b);
for (i=0; i<l; i++)
luaL_putchar(&b, toupper((unsigned char)(s[i])));
luaL_pushresult(&b);
return 1;
}
使用 Auxlib 中 buffer 的第一步是使用类型 luaL_Buffer 声明一个变量,然后调用luaL_buffinit 初始化这个变量。初始化之后,buffer 保留了一份状态 L 的拷贝,因此当我们调用其他操作 buffer 的函数的时候不需要传递 L。宏 luaL_putchar 将一个单个字符放入 buffer。Auxlib 也提供了 luaL_addlstring 以一个显示的长度将一个字符串放入 buffer, 而 luaL_addstring 将一个以 0 结尾的字符串放入 buffer。最后,luaL_pushresult 刷新 buffer并将最终字符串放到栈顶。这些函数的原型如下:
void luaL_buffinit (lua_State *L, luaL_Buffer *B);
void luaL_putchar (luaL_Buffer *B, char c);
void luaL_addlstring (luaL_Buffer *B, const char *s, size_t l);
void luaL_addstring (luaL_Buffer *B, const char *s);
void luaL_pushresult (luaL_Buffer *B);
使用这些函数,我们不需要担心 buffer 的分配,溢出等详细信息。正如我们所看到的,连接算法是有效的。函数 str_upper 可以毫无问题的处理大字符串(大于 1MB)。
当你使用auxlib中的buffer时,不必担心一点细节问题。你只要将东西放入buffer,程序会自动在Lua栈中保存中间结果。所以,你不要认为栈顶会保持你开始使用buffer的那个状态。另外,虽然你可以在使用buffer的时候,将栈用作其他用途,但每次你访问buffer的时候,这些其他用途的操作进行的push/pop操作必须保持平衡**(即有多少次push就要有多少次pop)**。有一种情况,即你打算将从Lua返回的字符串放入buffer时,这种情况下,这些限制有些过于严格。这种情况下,在将字符串放入buffer之前,不能将字符串出栈,因为一旦你从栈中将来自于Lua的字符串移出,你就永远不能使用这个字符串。同时,在将一个字符串出栈之前,你也不能够将其放入buffer,因为那样会将栈置于错误的层次(because then the stack would be in the wrong level)。换句话说你不能做类似下面的事情:
luaL_addstring(&b, lua_tostring(L, 1)); /* BAD CODE */
//(上面正好构成了一对矛盾),由于这种情况是很常见的,auxlib 提供了特殊的函数来将位于栈顶的值放入 buffer
void luaL_addvalue (luaL_Buffer *B);
当然,如果位于栈顶的值不是字符串或者数字的话,调用这个函数将会出错。
在 C 函数中保存状态
通常来说,C 函数需要保留一些非局部的数据,也就是指那些超过他们作用范围的数据。C 语言中我们使用全局变量或者 static 变量来满足这种需要。然而当你为 Lua 设计一个程序库的时候,全局变量和 static 变量不是一个好的方法。首先,不能将所有的(一般意义的,原文 generic)Lua 值保存到一个 C 变量中。第二,使用这种变量的库不能在多个 Lua 状态的情况下使用。
一个替代的解决方案是将这些值保存到一个 Lua 全局变两种,这种方法解决了前面的两个问题。Lua 全局变量可以存放任何类型的 Lua 值,并且每一个独立的状态都有他自己独立的全局变量集。然而,并不是在所有情况下,这种方法都是令人满意地解决方案,因为 Lua 代码可能会修改这些全局变量,危及 C 数据的完整性。为了避免这个问题,Lua 提供了一个独立的被称为 registry 的表,C 代码可以自由使用,但 Lua 代码不能访问他。
The Registry
registry 一直位于一个由 LUA_REGISTRYINDEX 定义的值所对应的假索引(pseudo-index)的位置。一个假索引除了他对应的值不在栈中之外,其他都类似于栈中的索引。Lua API 中大部分接受索引作为参数的函数,也都可以接受假索引作为参数—除了那些操作栈本身的函数,比如 lua_remove,lua_insert。例如,为了获取以键值 “Key” 保存在 registry 中的值,使用下面的代码:
lua_pushstring(L, "Key");
lua_gettable(L, LUA_REGISTRYINDEX);
registry 就是普通的 Lua 表,因此,你可以使用任何非 nil 的 Lua 值来访问她的元素。然而,由于所有的 C 库共享相同的 registry ,你必须注意使用什么样的值作为 key,否则会导致命名冲突。一个防止命名冲突的方法是使用 static 变量的地址作为 key:C 链接器保证在所有的库中这个 key 是唯一的。函数 lua_pushlightuserdata 将一个代表 C 指针的值放到栈内,下面的代码展示了使用上面这个方法,如何从 registry 中获取变量和向registry 存储变量:
/* variable with an unique address */
static const char Key = 'k';
/* store a number */
lua_pushlightuserdata(L, (void *)&Key); /* push address */
lua_pushnumber(L, myNumber); /* push value */
/* registry[&Key] = myNumber */
lua_settable(L, LUA_REGISTRYINDEX);
/* retrieve a number */
lua_pushlightuserdata(L, (void *)&Key); /* push address */
lua_gettable(L, LUA_REGISTRYINDEX); /* retrieve value */
myNumber = lua_tonumber(L, -1); /* convert to number */
我们会在 28.5 节中更详细的讨论 light userdata。
当然,你也可以使用字符串作为 registry 的 key,只要你保证这些字符串唯一。当你打算允许其他的独立库房问你的数据的时候,字符串型的 key 是非常有用的,因为他们需要知道 key 的名字。对这种情况,没有什么方法可以绝对防止名称冲突,但有一些好的习惯可以采用,比如使用库的名称作为字符串的前缀等类似的方法。类似lua 或者 lualib的前缀不是一个好的选择。另一个可选的方法是使用 universal unique identifier(uuid),很多系统都有专门的程序来产生这种标示符(比如 linux 下的 uuidgen)。一个 uuid 是一个由本机 IP 地址、时间戳、和一个随机内容组合起来的 128 位的数字(以 16 进制的方式书写,用来形成一个字符串),因此它与其他的 uuid 不同是可以保证的。
References
你应该记住,永远不要使用数字作为 registry 的 key,因为这种类型的 key 是保留给reference 系统使用。Reference 系统是由辅助库中的一对函数组成,这对函数用来不需要担心名称冲突的将值保存到 registry 中去。(实际上,这些函数可以用于任何一个表,但他们典型的被用于 registry)
调用
int r = luaL_ref(L, LUA_REGISTRYINDEX);
从栈中弹出一个值,以一个新的数字作为 key 将其保存到 registry 中,并返回这个key。我们将这个 key 称之为 reference。
顾名思义,我们使用 references 主要用于:将一个指向 Lua 值的 reference 存储到一个 C 结构体中。正如前面我们所见到的,我们永远不要将一个指向 Lua 字符串的指针保存到获取这个字符串的外部的 C 函数中。另外,Lua 甚至不提供指向其他对象的指针,比如 table 或者函数。因此,我们不能通过指针指向 Lua 对象。当我们需要这种指针的时候,我们创建一个 reference 并将其保存在 C 中。
要想将一个 reference 的对应的值入栈,只需要:
lua_rawgeti(L, LUA_REGISTRYINDEX, r);
最后,我们调用下面的函数释放值和 reference:
luaL_unref(L, LUA_REGISTRYINDEX, r);
调用这个之后,luaL_ref 可以再次返回 r 作为一个新的 reference。
reference 系统将 nil 作为特殊情况对待,不管什么时候,你以 nil 调用 luaL_ref 的话,不会创建一新的 reference ,而是返回一个常量 reference LUA_REFNIL。下面的调用没有效果:
luaL_unref(L, LUA_REGISTRYINDEX, LUA_REFNIL);
然而
lua_rawgeti(L, LUA_REGISTRYINDEX, LUA_REFNIL);
像预期的一样,将一个 nil 入栈。
reference 系统也定义了常量 LUA_NOREF,她是一个表示任何非有效的 reference 的整数值,用来标记无效的 reference。任何企图获取 LUA_NOREF 返回 nil,任何释放他的操作都没有效果。
注册表与引用总结:


C函数环境:(尽量用C函数环境代替注册表)

Upvalues
registry 实现了全局的值,upvalue 机制实现了与 C static 变量等价的东东,这种变量只能在特定的函数内可见。每当你在 Lua 中创建一个新的 C 函数,你可以将这个函数与任意多个 upvalues 联系起来,每一个 upvalue 可以持有一个单独的 Lua 值。下面当函数被调用的时候,可以通过假索引自由的访问任何一个 upvalues。
我们称这种一个 C 函数和她的 upvalues 的组合为闭包(closure)。记住:在 Lua 代码中,一个闭包是一个从外部函数访问局部变量的函数。一个 C 闭包与一个 Lua 闭包相近。关于闭包的一个有趣的事实是,你可以使用相同的函数代码创建不同的闭包,带有不同的upvalues。
看一个简单的例子,我们在 C 中创建一个 newCounter 函数。(我们已经在 6.1 节部分在 Lua 中定义过同样的函数)。这个函数是个函数工厂:每次调用他都返回一个新的counter 函数。尽管所有的 counters 共享相同的 C 代码,但是每个都保留独立的 counter变量,工厂函数如下:
/* forward declaration */
static int counter (lua_State *L);
int newCounter (lua_State *L) {
lua_pushnumber(L, 0);
lua_pushcclosure(L, &counter, 1);
return 1;
}
这里的关键函数是 lua_pushcclosure,她的第二个参数是一个基本函数(例子中卫counter),第三个参数是 upvalues 的个数(例子中为 1)。在创建新的闭包之前,我们必须将 upvalues 的初始值入栈,在我们的例子中,我们将数字 0 作为唯一的 upvalue 的初始值入栈。如预期的一样,lua_pushcclosure 将新的闭包放到栈内,因此闭包已经作为newCounter 的结果被返回。
现在,我们看看 counter 的定义:
static int counter (lua_State *L) {
double val = lua_tonumber(L, lua_upvalueindex(1));
lua_pushnumber(L, ++val); /* new value */
lua_pushvalue(L, -1); /* duplicate it */
lua_replace(L, lua_upvalueindex(1)); /* update upvalue */
return 1; /* return new value */
}
这里的关键函数是 lua_upvalueindex(实际是一个宏),用来产生一个 upvalue 的假索引。这个假索引除了不在栈中之外,和其他的索引一样。表达式 lua_upvalueindex(1)函数第一个 upvalue 的索引。因此,在函数 counter 中的 lua_tonumber 获取第一个(仅有的)upvalue 的当前值,转换为数字型。然后,函数 counter 将新的值++val 入栈,并将这个值的一个拷贝使用新的值替换 upvalue。最后,返回其他的拷贝。
与 Lua 闭包不同的是,C 闭包不能共享 upvalues:每一个闭包都有自己独立的变量集。然而,我们可以设置不同函数的 upvalues 指向同一个表,这样这个表就变成了一个所有函数共享数据的地方。



User-Defined Types in C
在面的一章,我们讨论了如何使用 C 函数扩展 Lua 的功能,现在我们讨论如何使用C 中新创建的类型来扩展 Lua。我们从一个小例子开始,本章后续部分将以这个小例子为基础逐步加入 metamethods 等其他内容来介绍如何使用 C 中新类型扩展 Lua。
我们的例子涉及的类型非常简单,数字数组。这个例子的目的在于将目光集中到 API问题上,所以不涉及复杂的算法。尽管例子中的类型很简单,但很多应用中都会用到这种类型。一般情况下,Lua 中并不需要外部的数组,因为哈希表很好的实现了数组。但是对于非常大的数组而言,哈希表可能导致内存不足,因为对于每一个元素必须保存一个范性的(generic)值,一个链接地址,加上一些以备将来增长的额外空间。在 C 中的直接存储数字值不需要额外的空间,将比哈希表的实现方式节省 50%的内存空间。
我们使用下面的结构表示我们的数组:
typedef struct NumArray {
int size;
double values[1]; /* variable part */
} NumArray;
我们使用大小 1 声明数组的 values,由于 C 语言不允许大小为 0 的数组,这个 1 只是一个占位符;我们在后面定义数组分配空间的实际大小。对于一个有 n 个元素的数组来说,我们需要
sizeof(NumArray) + (n-1)*sizeof(double) bytes
(由于原始的结构中已经包含了一个元素的空间,所以我们从 n 中减去 1)
Userdata
我们首先关心的是如何在 Lua 中表示数组的值。Lua 为这种情况提供专门提供一个基本的类型:userdata。一个 userdatum 提供了一个在 Lua 中没有预定义操作的 raw 内存区域。
Lua API 提供了下面的函数用来创建一个 userdatum:
void *lua_newuserdata (lua_State *L, size_t size);
lua_newuserdata 函数按照指定的大小分配一块内存,将对应的 userdatum 放到栈内,并返回内存块的地址。如果出于某些原因你需要通过其他的方法分配内存的话,很容易创建一个指针大小的 userdatum,然后将指向实际内存块的指针保存到 userdatum 里。我们将在下一章看到这种技术的例子。
使用 lua_newuserdata 函数,创建新数组的函数实现如下:
static int newarray (lua_State *L) {
int n = luaL_checkint(L, 1);
size_t nbytes = sizeof(NumArray) + (n - 1)*sizeof(double);
NumArray *a = (NumArray *)lua_newuserdata(L, nbytes);
a->size = n;
return 1; /* new userdatum is already on the stack */
}
(函数 luaL_checkint 是用来检查整数的 luaL_checknumber 的变体)一旦 newarray在 Lua 中被注册之后,你就可以使用类似 a = array.new(1000)的语句创建一个新的数组了。
为了存储元素,我们使用类似 array.set(array, index, value)调用,后面我们将看到如何使用 metatables 来支持常规的写法 array[index] = value。对于这两种写法,下面的函数是一样的,数组下标从1开始:
static int setarray (lua_State *L) {
NumArray *a = (NumArray *)lua_touserdata(L, 1);
int index = luaL_checkint(L, 2);
double value = luaL_checknumber(L, 3);
luaL_argcheck(L, a != NULL, 1, "`array' expected");
luaL_argcheck(L, 1 <= index && index <= a->size, 2,
"index out of range");
a->values[index-1] = value;
return 0;
}
luaL_argcheck 函数检查给定的条件,如果有必要的话抛出错误。因此,如果我们使用错误的参数调用 setarray,我们将得到一个错误信息:
array.set(a, 11, 0)
--> stdin:1: bad argument #1 to 'set' ('array' expected)
下面的函数获取一个数组元素:
static int getarray (lua_State *L) {
NumArray *a = (NumArray *)lua_touserdata(L, 1);
int index = luaL_checkint(L, 2);
luaL_argcheck(L, a != NULL, 1, "'array' expected");
luaL_argcheck(L, 1 <= index && index <= a->size, 2,
"index out of range");
lua_pushnumber(L, a->values[index-1]);
return 1;
}
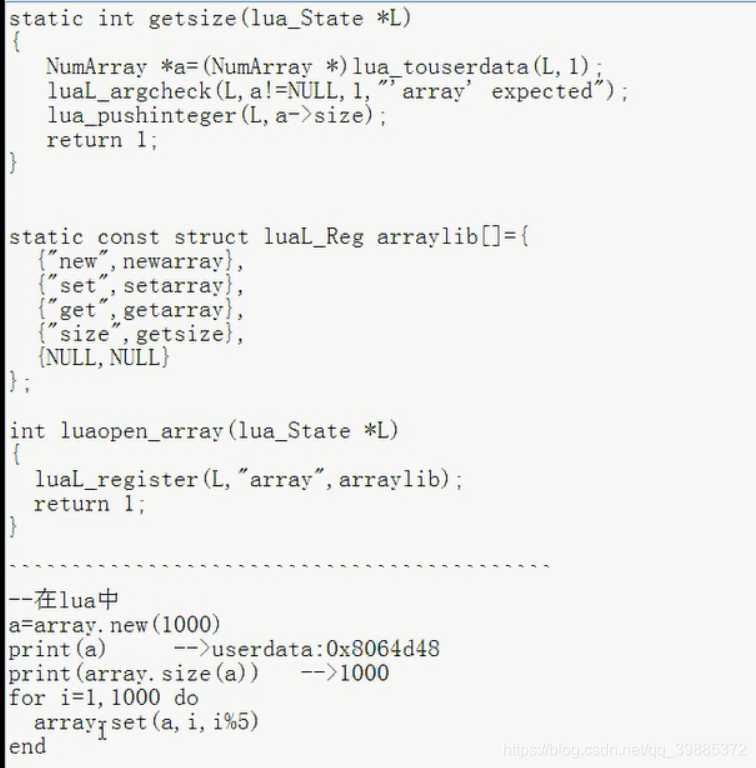
我们定义另一个函数来获取数组的大小:
static int getsize (lua_State *L) {
NumArray *a = (NumArray *)lua_touserdata(L, 1);
luaL_argcheck(L, a != NULL, 1, "`array' expected");
lua_pushnumber(L, a->size);
return 1;
}
最后,我们需要一些额外的代码来初始化我们的库:
static const struct luaL_reg arraylib [] = {
{"new", newarray},
{"set", setarray},
{"get", getarray},
{"size", getsize},
{NULL, NULL}
};
int luaopen_array (lua_State *L) {
luaL_openlib(L, "array", arraylib, 0);
return 1;
}
这儿我们再次使用了辅助库的 luaL_openlib 函数,他根据给定的名字创建一个表,并使用 arraylib 数组中的 name-function 对填充这个表。
打开上面定义的库之后,我们就可以在 Lua 中使用我们新定义的类型了:
a = array.new(1000)
print(a) --> userdata: 0x8064d48
print(array.size(a)) --> 1000
for i=1,1000 do
array.set(a, i, 1/i)
end
print(array.get(a, 10)) --> 0.1
在一个 Pentium/Linux 环境中运行这个程序,一个有 100K 元素的数组大概占用800KB 的内存,同样的条件由 Lua 表实现的数组需要 1.5MB 的内存。



Metatables
我们上面的实现有一个很大的安全漏洞。假如使用者写了如下类似的代码:array.set(io.stdin, 1, 0)。io.stdin 中的值是一个带有指向流(FILE*)的指针的 userdatum。因为它是一个 userdatum,所以 array.set 很乐意接受它作为参数,程序运行的结果可能导致内存 core dump(如果你够幸运的话,你可能得到一个访问越界(index-out-of-range)错误)。这样的错误对于任何一个 Lua 库来说都是不能忍受的。不论你如何使用一个 C 库,都不应该破坏 C 数据或者从 Lua 产生 core dump。
为了区分数组和其他的userdata,我们单独为数组创建了一个metatable(记住userdata也可以拥有 metatables)。下面,我们每次创建一个新的数组的时候,我们将这个单独的metatable 标记为数组的 metatable。每次我们访问数组的时候,我们都要检查他是否有一个正确的 metatable。因为 Lua 代码不能改变 userdatum 的 metatable,所以他不会伪造我们的代码。
我们还需要一个地方来保存这个新的 metatable,这样我们才能够当创建新数组和检查一个给定的 userdatum 是否是一个数组的时候,可以访问这个 metatable。正如我们前面介绍过的,有两种方法可以保存 metatable:在 registry 中,或者在库中作为函数的upvalue。在 Lua 中一般习惯于在 registry 中注册新的 C 类型,使用类型名作为索引,metatable 作为值。和其他的 registry 中的索引一样,我们必须选择一个唯一的类型名,避免冲突。我们将这个新的类型称为 “LuaBook.array”。
辅助库提供了一些函数来帮助我们解决问题,我们这儿将用到的前面未提到的辅助函数有:
int luaL_newmetatable (lua_State *L, const char *tname);
void luaL_getmetatable (lua_State *L, const char *tname);
void *luaL_checkudata (lua_State *L, int index,
const char *tname);
luaL_newmetatable 函数创建一个新表(将用作 metatable),将新表放到栈顶并建立表和 registry 中类型名的联系。这个关联是双向的:使用类型名作为表的 key;同时使用表作为类型名的 key(这种双向的关联,使得其他的两个函数的实现效率更高)。luaL_getmetatable 函数获取 registry 中的 tname 对应的 metatable。最后,luaL_checkudata检查在栈中指定位置的对象是否为带有给定名字的 metatable 的 usertatum。如果对象不存在正确的 metatable,返回 NULL(或者它不是一个 userdata);否则,返回 userdata 的地址。
下面来看具体的实现。第一步修改打开库的函数,新版本必须创建一个用作数组
metatable 的表:
int luaopen_array (lua_State *L) {
luaL_newmetatable(L, "LuaBook.array");
luaL_openlib(L, "array", arraylib, 0);
return 1;
}
第二步,修改 newarray,使得在创建数组的时候设置数组的 metatable:
static int newarray (lua_State *L) {
int n = luaL_checkint(L, 1);
size_t nbytes = sizeof(NumArray) + (n - 1)*sizeof(double);
NumArray *a = (NumArray *)lua_newuserdata(L, nbytes);
luaL_getmetatable(L, "LuaBook.array");
lua_setmetatable(L, -2);
a->size = n;
return 1; /* new userdatum is already on the stack */
}
lua_setmetatable 函数将表出栈,并将其设置为给定位置的对象的 metatable。在我们的例子中,这个对象就是新的 userdatum。
最后一步,setarray、getarray 和 getsize 检查他们的第一个参数是否是一个有效的数组。因为我们打算在参数错误的情况下抛出一个错误信息,我们定义了下面的辅助函数:
static NumArray *checkarray (lua_State *L) {
void *ud = luaL_checkudata(L, 1, "LuaBook.array");
luaL_argcheck(L, ud != NULL, 1, "`array' expected");
return (NumArray *)ud;
}
使用 checkarray,新定义的 getsize 是更直观、更清楚:
static int getsize (lua_State *L) {
NumArray *a = checkarray(L);
lua_pushnumber(L, a->size);
return 1;
}
由于 setarray 和 getarray 检查第二个参数 index 的代码相同,我们抽象出他们的共同部分,在一个单独的函数中完成:
static double *getelem (lua_State *L) {
NumArray *a = checkarray(L);
int index = luaL_checkint(L, 2);
luaL_argcheck(L, 1 <= index && index <= a->size, 2,
"index out of range");
/* return element address */
return &a->values[index - 1];
}
使用这个 getelem,函数 setarray 和 getarray 更加直观易懂:
static int setarray (lua_State *L) {
double newvalue = luaL_checknumber(L, 3);
*getelem(L) = newvalue;
return 0;
}
static int getarray (lua_State *L) {
lua_pushnumber(L, *getelem(L));
return 1;
}
现在,假如你尝试类似 array.get(io.stdin, 10)的代码,你将会得到正确的错误信息:
error: bad argument #1 to 'getarray' ('array' expected)
访问面向对象的数据
下面我们来看看如何定义类型为对象的 userdata,以致我们就可以使用面向对象的语法来操作对象的实例,比如:
a = array.new(1000)
print(a:size()) --> 1000
a:set(10, 3.4)
print(a:get(10)) --> 3.4
记住 a:size()等价于 a.size(a)。所以,我们必须使得表达式 a.size 调用我们的 getsize函数。这儿的关键在于__index 元方法(metamethod)的使用。对于表来说,不管什么时候只要找不到给定的 key,这个元方法就会被调用。对于 userdata 来讲,每次被访问的时候元方法都会被调用,因为 userdata 根本就没有任何 key。
假如我们运行下面的代码:
local metaarray = getmetatable(array.new(1))
metaarray.__index = metaarray
metaarray.set = array.set
metaarray.get = array.get
metaarray.size = array.size
第一行,我们仅仅创建一个数组并获取他的 metatable,metatable 被赋值给 metaarray(我们不能从 Lua 中设置 userdata 的 metatable,但是我们在 Lua 中无限制的访问metatable)。接下来,我们设置 metaarray.__index 为 metaarray。当我们计算 a.size 的时候,Lua 在对象 a 中找不到 size 这个键值,因为对象是一个 userdatum。所以,Lua 试着从对象a 的metatable的__index域获取这个值,正好__index就是metaarray。但是metaarray.size就是 array.size,因此 a.size(a)如我们预期的返回 array.size(a)。
当然,我们可以在 C 中完成同样的事情,甚至可以做得更好:现在数组是对象,他有自己的操作,我们在表数组中不需要这些操作。我们实现的库唯一需要对外提供的函数就是 new,用来创建一个新的数组。所有其他的操作作为方法实现。C 代码可以直接注册他们。
getsize、getarray 和 setarray 与我们前面的实现一样,不需要改变。我们需要改变的只是如何注册他们。也就是说,我们必须改变打开库的函数。首先,我们需要分离函数列表,一个作为普通函数,一个作为方法:
static const struct luaL_reg arraylib_f [] = {
{"new", newarray},
{NULL, NULL}
};
static const struct luaL_reg arraylib_m [] = {
{"set", setarray},
{"get", getarray},
{"size", getsize},
{NULL, NULL}
};
新版本打开库的函数 luaopen_array,必须创建一个 metatable,并将其赋值给自己的__index 域,在那儿注册所有的方法,创建并填充数组表:
int luaopen_array (lua_State *L) {
luaL_newmetatable(L, "LuaBook.array");
lua_pushstring(L, "__index");
lua_pushvalue(L, -2); /* pushes the metatable */
lua_settable(L, -3); /* metatable.__index = metatable */
luaL_openlib(L, NULL, arraylib_m, 0); //=luaL_register(L,NULL,arraylib_m)
luaL_openlib(L, "array", arraylib_f, 0); //=luaL_register(L, "array", arraylib_f)
return 1;
}
这里我们使用了 luaL_openlib 的另一个特征,第一次调用,当我们传递一个 NULL作为库名时,luaL_openlib 并没有创建任何包含函数的表;相反,他认为封装函数的表在栈内,位于临时的 upvalues 的下面。在这个例子中,封装函数的表是 metatable 本身,也就是 luaL_openlib 放置方法的地方。第二次调用 luaL_openlib 正常工作:根据给定的数组名创建一个新表,并在表中注册指定的函数(例子中只有一个函数 new)。下面的代码,我们为我们的新类型添加一个__tostring 方法,这样一来 print(a)将打印数组加上数组的大小,大小两边带有圆括号(比如,array(1000)):
int array2string (lua_State *L) {
NumArray *a = checkarray(L);
lua_pushfstring(L, "array(%d)", a->size);
return 1;
}
函数 lua_pushfstring 格式化字符串,并将其放到栈顶。为了在数组对象的 metatable中包含 array2string,我们还必须在 arraylib_m 列表中添加 array2string:
static const struct luaL_reg arraylib_m [] = {
{"__tostring", array2string},
{"set", setarray},
...
};
访问数组
除了上面介绍的使用面向对象的写法来访问数组以外,还可以使用传统的写法来访问数组元素,不是 a:get(i),而是 a[i]。对于我们上面的例子,很容易实现这个,因为我们的 setarray 和 getarray 函数已经依次接受了与他们的元方法对应的参数。一个快速的解决方法是在我们的 Lua 代码中正确的定义这些元方法:
local metaarray = getmetatable(newarray(1))
metaarray.__index = array.get
metaarray.__newindex = array.set
(这段代码必须运行在前面的最初的数组实现基础上,不能使用为了面向对象访问的修改的那段代码)
我们要做的只是使用传统的语法:
a = array.new(1000)
a[10] = 3.4 -- setarray
print(a[10]) -- getarray --> 3.4
如果我们喜欢的话,我们可以在我们的 C 代码中注册这些元方法。我们只需要修改我们的初始化函数:
int luaopen_array (lua_State *L) {
luaL_newmetatable(L, "LuaBook.array");
luaL_openlib(L, "array", arraylib, 0);
/* now the stack has the metatable at index 1 and
'array' at index 2 */
lua_pushstring(L, "__index");
lua_pushstring(L, "get");
lua_gettable(L, 2); /* get array.get */
lua_settable(L, 1); /* metatable.__index = array.get */
lua_pushstring(L, "__newindex");
lua_pushstring(L, "set");
lua_gettable(L, 2); /* get array.set */
lua_settable(L, 1); /* metatable.__newindex = array.set */
return 0;
}
Light Userdata
到目前为止我们使用的 userdata 称为 full userdata。Lua 还提供了另一种 userdata: light userdata。
一个 light userdatum 是一个表示 C 指针的值(也就是一个 void *类型的值)。由于它是一个值,我们不能创建他们(同样的,我们也不能创建一个数字)。可以使用函数lua_pushlightuserdata 将一个 light userdatum 入栈:
void lua_pushlightuserdata (lua_State *L, void *p);
尽管都是 userdata,light userdata 和 full userdata 有很大不同。Light userdata 不是一个缓冲区,仅仅是一个指针,没有 metatables。像数字一样,light userdata 不需要垃圾收集器来管理她。
有些人把 light userdata 作为一个低代价的替代实现,来代替 full userdata,但是这不是 light userdata 的典型应用。首先,使用 light userdata 你必须自己管理内存,因为他们和垃圾收集器无关。第二,尽管从名字上看有轻重之分,但 full userdata 实现的代价也并不大,比较而言,他只是在分配给定大小的内存时候,有一点点额外的代价。
Light userdata 真正的用处在于可以表示不同类型的对象。当 full userdata 是一个对象的时候,它等于对象自身;另一方面,light userdata 表示的是一个指向对象的指针,同样的,它等于指针指向的任何类型的 userdata。所以,我们在 Lua 中使用 light userdata表示 C 对象。
看一个典型的例子,假定我们要实现:Lua 和窗口系统的绑定。这种情况下,我们使用 full userdata 表示窗口(每一个 userdatum 可以包含整个窗口结构或者一个有系统创建的指向单个窗口的指针)。当在窗口有一个事件发生(比如按下鼠标),系统会根据窗口的地址调用专门的回调函数。为了将这个回调函数传递给 Lua,我们必须找到表示指定窗口的 userdata。为了找到这个 userdata,我们可以使用一个表:索引为表示窗口地址的light userdata,值为在 Lua 中表示窗口的 full userdata。一旦我们有了窗口的地址,我们将窗口地址作为 light userdata 放到栈内,并且将 userdata 作为表的索引存到表内。(注意这个表应该有一个 weak 值,否则,这些 full userdata 永远不会被回收掉。)
