进程的调度
吞吐和响应
我们先说下吞吐量和响应的概念,响应就是最小化某个任务的响应时间,哪怕牺牲其他的任务为代价,吞吐就是全局视野,整个系统的workload被最大化处理,简单来说响应就是你点击一个按钮的响应速度,吞吐就是整个系统用在工作上的时间比,吞吐和响应是两个拔河的人,响应的提高肯定会以牺牲吞吐为代价,反着也成立,在实时操作系统会发生高优先级抢占,抢占必然会发生吞吐率的下降,时间并没有花在工作上而花在了上下文切换,其实上下文切换的时间很短对系统的影响及其小,但是在上下文切换中会引起很多的cache miss,cpu 内部有一个高速的cache它可以去命中外面正在运行的代码或数据,但是当你从一个进程切换到另一个进程,cache就需要重新load,这才是关键所在。

如上图所示,在linux内核中有三个编译选项,我们一般做手机或者电脑的时候选择最后的一种,做服务器就选择第一种,第一个是不强制抢占,我们的操作系统基本上就没有什么抢占调度了,做服务器的时候我们当然希望它的同一时间内服务更多的数据库,所以要谨慎使用抢占避免吞吐的开销,我们的桌面电脑就要追求响应速度,所以选择成最后一个抢占型内核,当然响应速度的提升必然会导致吞吐的下降,自上向下的选择抢占性逐步增强.
I/O消耗型和CPU消耗型
调度器的另一个输入是你运行的进程类型,在一个典型的操作系统中进程分为I/O消耗型和CPU消耗型,CPU消耗型多数时间花在CPU运算上面,I/O消耗型多数时间花在数据的传输 上,CPU利用率低但是对能是否及时拿到CPU调度很敏感,I/O消耗型的优先级会比CPU消耗型的高
优先级数组和Bitmaps
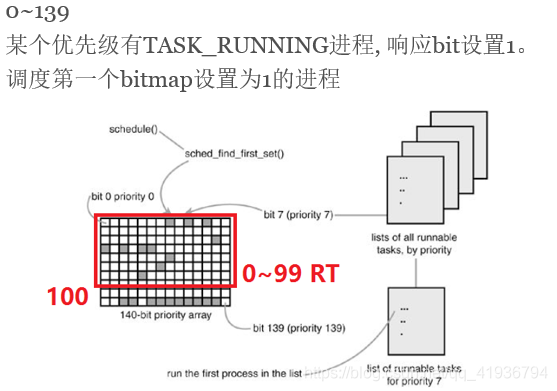
在早期2.6版本的内核中,它把整个linux内核优先级划分到0~139之间,内核空间数字越小优先级越高,内核里面0-99优先级属于内核中RT型的进程,100-139是非RT的普通进程.
RT策略分成以下两种,SCHED_FIFO和SCHED_RR在优先级的表现上一样,优先级高的跑到自己不想跑了再让低优先级的跑,区别是SCHED_FIFO优先级相同的进程是先进先出,而SCHED_RR是轮询进行

非RT型的进程在不同优先级轮转,优先高的并不会堵着优先级低的,只是优先级高的能获得更多时间片,并且优先级高的从睡眠中醒来可以去抢占优先级低的,抢到后再和优先级低的一起轮转,在linux早期内核中还会根据睡眠的情况动态奖励和惩罚,你进程越是更积极优先会越降低,进程越睡眠优先级越高,这是让I/O消耗型进程同一时刻竞争过CPU消耗型.
rt的门限

linux规定rt进程在period的时间里rt最多只能跑runtime的时间,如果不做这样的限制,rt进程里面有一个BUG的话死循环在这里了,那么非rt的进程岂不是永远得不到执行
CFS:完全公平调度
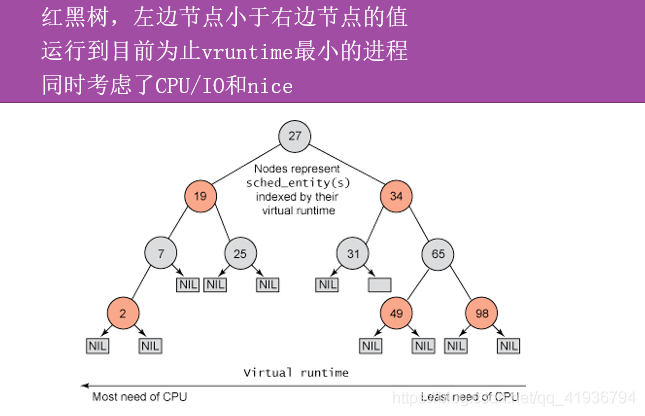
这棵红黑树放在那里呢?就像每个软件工程师写代码的时候,会将任务排成队列,做完一个做下一个.CPU 也是这样的,每个 CPU 都有自己的 struct rq 结构,其用于描述在此 CPU 上所运行的所有进程,其包括一个实时进程队列 rt_rq 和一个 CFS 运行队列 cfs_rq,在调度时,调度器首先会先去实时进程队列找是否有实时进程需要运行,如果没有才会去 CFS 运行队列找是否有进行需要运行
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
unsigned int nr_running;
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
......
struct load_weight load;
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
......
struct task_struct *curr, *idle, *stop;
......
};

完全公平调度就是要照顾到普通进程之间的公平,用到的数据结构就是红黑树,vruntime等于物理runtime(实际运行时间)除以一个权重乘以1024,权重值和nice值相对应,看上图的prio_to_weight,所谓nice值就是普通进程优先级转化后的一个值,nice值越高进程越难被调度,让I/O消耗型进程同一时刻竞争过CPU消耗型,比如2进程刚开始的vruntime比7小所以先执行,但是执行过后2进程的物理runtime就变大,所以2进程移动到7进程的右边,这是在非rt的普通进程层面,随便来一个rt进程都能把非rt的秒杀了
看一个实验:
#include <stdio.h>
#include <pthread.h>
#include <sys/types.h>
void *thread_fun(void *param)
{
printf("thread pid:%d,tid:%lu\n",getpid(),pthread_self());
while(1);
return NULL;
}
int main(void)
{
pthread_t tid1,tid2;
int ret;
printf("main pid:%d,tid:%lu\n",getpid(),pthread_self());
pthread_create(&tid1,NULL,thread_fun,NULL);
pthread_create(&tid1,NULL,thread_fun,NULL);
pthread_join(tid1,NULL);
pthread_join(tid1,NULL);
return 0;
}
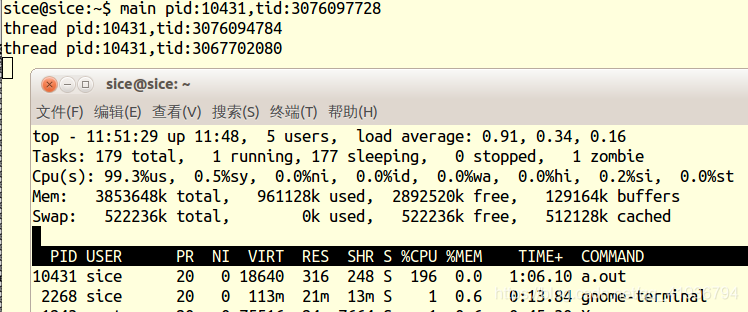
跑一份时候CPU占用率
跑两份时cpu占用率
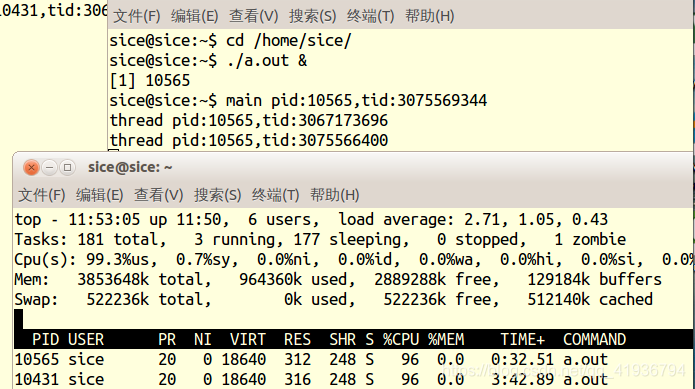
敲入命令改nice值为-5

可以看出CPU占用率发生了变化,因为根据完全公平调度算法(一般线程nice值为0),x/3121 = y/1024,x,y为物理实际运行时间,所以x会是y的三倍,即CPU占用率10431进程会是10565的三倍

看第二个实验
我们把第一个实验的a.out执行,发现CPU占用率接近200%
但是我们的点击操作一点都不会卡,这是因为非rt的普通进程在不同优先级轮转,当使用"chrt -f -a -p 50 10730 "把进程改为优先级为50的SCHED_FIFO的RT进程,显然RT进程是不会在不同的优先级轮转,只有当前进程执行完才进行下一个进程,所以你的点击会变得非常非常卡
