文章目录
数据处理
爬虫爬取的数据我们可以大致分为非结构化语言HTML与结构化语言json与XML。
Python中的正则表达式
正则表达式(regular expression): 一种广泛用于匹配字符串的工具。它用一个“字符串”来描述一个特征,然后去验证另一个“字符串”是否符合这个特征。
元字符
| 元字符 | 含义 |
|---|---|
| . | 在默认模式,匹配除了换行的任意字符 |
| | | 逻辑或操作符 |
| [] | 匹配字符集中的一个字符 |
| [^] | 匹配字符集的取反中的一个字符 |
| [A-B] | 匹配从A到B的字符 |
| \ | 对紧跟其后的字符转义 |
| () | 对表达式进行分组,将圆括号内的内容当做一个整体,并获得匹配的值 |
重复匹配
| 重复匹配 | 含义 |
|---|---|
| {n} | 表达式重复n次 |
| {m,n} | 表达式至少重复m次,最多重复n次 |
| {m,} | 表达式至少重复m次 |
| * | 对它前面的正则式匹配0到任意次重复。相当于{0,} |
| + | 对它前面的正则式匹配1到任意次重复{1,} |
| ? | 对它前面的正则式匹配0到1次重复 {0,1} |
注:重复匹配时正则会默认使用贪婪模式,即尽量多的匹配,如果需要非贪婪匹配可以在重复匹配后加?解决
data = '11A23456a232e'
贪婪模式 = re.search(r'2.*2', data)
非贪婪模式 = re.search(r'2.*?2', data)
print('贪婪模式:', 贪婪模式.group(), '非贪婪模式:', 非贪婪模式.group())
# 贪婪模式: 23456a232 非贪婪模式: 23456a2
位置匹配
| 位置匹配 | 含义 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串尾或者换行符的前一个字符 |
预定意义字符
| 预定意义字符 | 意义 |
|---|---|
| \d | 匹配任何Unicode十进制数 |
| \D | 匹配任何非十进制数字的字符 |
| \w | 包含了可以构成词语的绝大部分字符,也包括数字和下划线 |
| \W | 匹配任何不是单词字符的字符。 |
| \s | 匹配任何Unicode空白字符(包括 [ \t\n\r\f\v] ,还有很多其他字符,比如不同语言排版规则约定的不换行空格) |
| \b | 匹配空字符串,但只在单词开始或结尾的位置。(比如r’\bx\b’可以匹配’x’, ‘x.’, ‘a x b’, (x); 但如果是’axb’或’x1’就无法匹配) |
| \B | 与\b取反 |
| \A | 只匹配字符串开始。相当于^ |
| \Z | 只匹配字符串尾。相当于$ |
预定字符在不同模式下会有不同的表现方式,具体可以看官网文档。以上所有意义都是在Unicode模式下的情况。(如果使用预定意义字符,其中\会被认为为转义,所有加入我们需要使用\d时候,需要输入\d或者可以使用r’‘来取消转义,比如r’\d’)
常用正则表达式
| 功能 | 表达式 |
|---|---|
| Email地址 | ^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$ |
| 域名 | [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.? |
| 手机号码 | ^(13[0-9] |
| 身份证号 | ^\d{15} |
| 日期格式 | ^\d{4}-\d{1,2}-\d{1,2} |
| 空白行的正则表达式 | \n\s*\r (可以用来删除空白行) |
| IP地址提取 | \d+.\d+.\d+.\d+ (提取IP地址时有用) |
| 腾讯QQ号 | [1-9][0-9]{4,} (腾讯QQ号从10000开始) |
re库
re库是Python完整支持正则表达式的内置库。
re库三大搜索方法
| re库方法 | 作用 |
|---|---|
| .match(正则表达式,要匹配的字符串,[匹配模式]) | 尝试从字符串的起始位置匹配一个模式(单值匹配,找到一处即返回) |
| .search(正则表达式,要匹配的字符串,[flags=匹配模式]) | 从文本中查找,(单值匹配,找到一处即返回) |
| .findall(正则表达式,要匹配的字符串,[flags=匹配模式]) | 全文匹配,找到字符串中所以匹配的对象并且已列表形式返回 |
| .compile(正则表达式,[flags=匹配模式]) | 使用此方法创建的正则表达式时候时查找效率更高 |
| .split(正则表达式,要匹配的字符串,maxsplit=最大拆分次数,[flags=匹配模式]) | 和Python内置的.split方法类似,按照指定的正则将字符串拆封 |
| .sub(正则表达式,取代对象,要匹配的字符串,maxsplit=最大取代次数,[flags=匹配模式]) | 在指定的字符串中根据正则匹配的内容进行取代替换 |
flag匹配模式
| flag匹配模式 | 作用 |
|---|---|
| re.A | ASCII字符模式 |
| re.I | 使匹配对大小写不敏感,也就是不区分大小写的模式 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 这个通配符能够匹配包括换行在内的所有字符,针对多行匹配 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解(支持将正则表达式用三引号写成多行模式) |
data = 'week哈_end,endfor11A23456a23,end'
# 使用compile方法将正则表达式和匹配模式写入
regular = re.compile(r'.a23', re.I)
# match,search,findall(正则表达式三大搜索函数)
regular1 = regular.match(data)
regular2 = regular.search(data)
regular3 = regular.findall(data)
print(regular1, regular2, regular3)
# 使用split分组
split = regular.split(data)
# 使用sub替换
sub = regular.sub('替换物', data)
print(split, sub)
分组
使用小括号()分组后的正则表达式可以使用分组
| 分组使用的方法 | 作用 |
|---|---|
| () | 对表达式进行分组,将圆括号内的内容当做一个整体,并获得匹配的值 |
| .group(组数) | 取出搜索内容并进行匹配 |
| .groups() | 将所以分组以列表形式取出 |
| .groupdict() | 需要和(?P…)配合使用 |
data = '<html>我是一个标签</html>'
# \1表示第一组中的内容(?P<name>\w*),第一组获得的值是html,也就是说\1=html
regular = re.compile(r'<(\w*)>(?P<data>.*)<(/\1)>')
regular1 = regular.match(data)
regular2 = regular.search(data)
regular3 = regular.findall(data)
# group默认取出的为所以组,跟上数字后即可指定取出的组
print(regular1.group(2), regular2.group(2))
# 分组后findall不支持group方法,但其值和groups相似,都会取出所有组,groupdict方法必须在有(?P<命名>正则表达式)的时候才能生效
print(regular3, regular2.groups(), regular2.groupdict())
json
json是一种非常常见的用于数据存储和传输的数据交换格式,当前大多数网站都会用到json进行数据交换,并且json可以转换为Python内建数据类型,便于数据的处理。
Python的json库
Python提供的json库可以方便快捷的让我们对json数据类型与Python内建数据类型快速互相转换。下列代码中,我们先拿到一个返回json数据类型的免费的api接口作为测试.使用.loads()方法将json数据类型对象转换成为Python数据类型对象,使用.dumps()将Python数据类型对象转换成为json数据类型。(.load()与.dump()方法可以将json文件和Python文件中的数据类型相互转换,使用频率较少,如有需要自行测试)
import requests
import json
class DataProcessing:
def __init__(self):
# 使用彩云天气测试免费用的api接口读取一个json数据
self.api_url_json = 'https://api.caiyunapp.com/v2/TAkhjf8d1nlSlspN/121.6544,25.1552/realtime.json'
self.header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4029.0 Safari/537.36'}
def get_json(self):
"""获取json对象的网页"""
json_data = requests.get(self.api_url_json, self.header)
print('\n我是从网站中抓取出来的数据:', json_data.text, '我当前的数据类型是:', type(json_data.text))
return json_data
def json_change_dict(self, j):
json_data = j
dict_data = json.loads(json_data.text)
print('我是经过.loads转换后的数据类型(将json数据类型对象转换为Python数据类型对象):', dict_data, '我当前的数据类型是:', type(dict_data))
return dict_data
def dict_change_json(self, dic):
dict_data = dic
json_data = json.dumps(dict_data)
print('我是经过.dumps转换后的数据类型(将Python数据类型对象转换为json数据类型对象):', json_data, '我当前的数据类型是:', type(json_data))
return json_data
def main(self):
"""主函数"""
# 网页中的数据
web_data = self.get_json()
# 将网页中的json数据通过.loads()方法转换为Python数据类型
dict_data = self.json_change_dict(web_data)
# 将代码中的Python数据类型转换为json数据类型.dumps()
json_data = self.dict_change_json(dict_data)
if __name__ == '__main__':
item = DataProcessing()
item.main()
XML
对于大多数人程序员来说或多或少都接触过HTML,当我们初看XML时会觉得他很像HTML,都是用一组组标签构成的,不过相对于HTML,XML有着更加严格的语法。而且HTML和XML应用方向也完全不同。
XML 被设计用来传输和存储数据。
HTML 被设计用来显示数据。
当前包括在我常用的博客(csdn在内)用XML传输数据的地方非常普遍
<root>
<p lang="zh">我</p>
<p>有没有</p>
<p>很像</p>
<p>HTML</p>
</root>
xpath
xpath是专门用于快速定位特定HTML和XML元素以及获取节点信息的一种工具。在XML或者HTML中每一对标签都是一个结点,其中常用的有根结点、文档结点与属性结点
上述xml中<root>为根结点,<p>我</p>为元素结点,我为文本结点,lang="zh"为属性结点。
xpath大多数就是根据上述结点定位信息。
xpath下载
虽然大多数浏览器的控制台中都支持复制xpath,但流程较为繁琐,我在这安利两个火狐中的xpath,并且之后很多很多测试我也会基于这两个工具进行。
Try XPath - 可以根据指定的xpath在浏览器中定位元素的工具

xPath Finder - 快速找到xpath的工具(如果不嫌麻烦可以使用浏览器自己生成的xpath)
xpath的常用语法
| 结点选择 | 作用 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取 |
| * | 匹配任何元素结点。 |
| @* | 匹配任何属性结点。 |
| node() | 匹配任何类型的节点。 |
/root/element[1] |
选取属于 root子元素的第一个 element元素。 |
/root/element[last()] |
选取属于 root子元素的最后一个 element元素。 |
/root/element[last()-1] |
选取属于 root子元素的倒数第二个 element元素。 |
/root/element[position()<3] |
选取最前面的两个属于 root元素的子元素的 element元素。 |
//element[@name] |
选取所有拥有名为 name的属性的 element元素。 |
//element[@name='xunmi'] |
选取所有 element元素,且这些元素拥有值为 xunmi的 name属性。 |
/root/element[num>3] |
选取 root元素的所有 element元素,且其中的 num元素的值须大于 3。 |
| text() | 获取文本结点的内容 |
微软官网有更多更详细的xpath用法
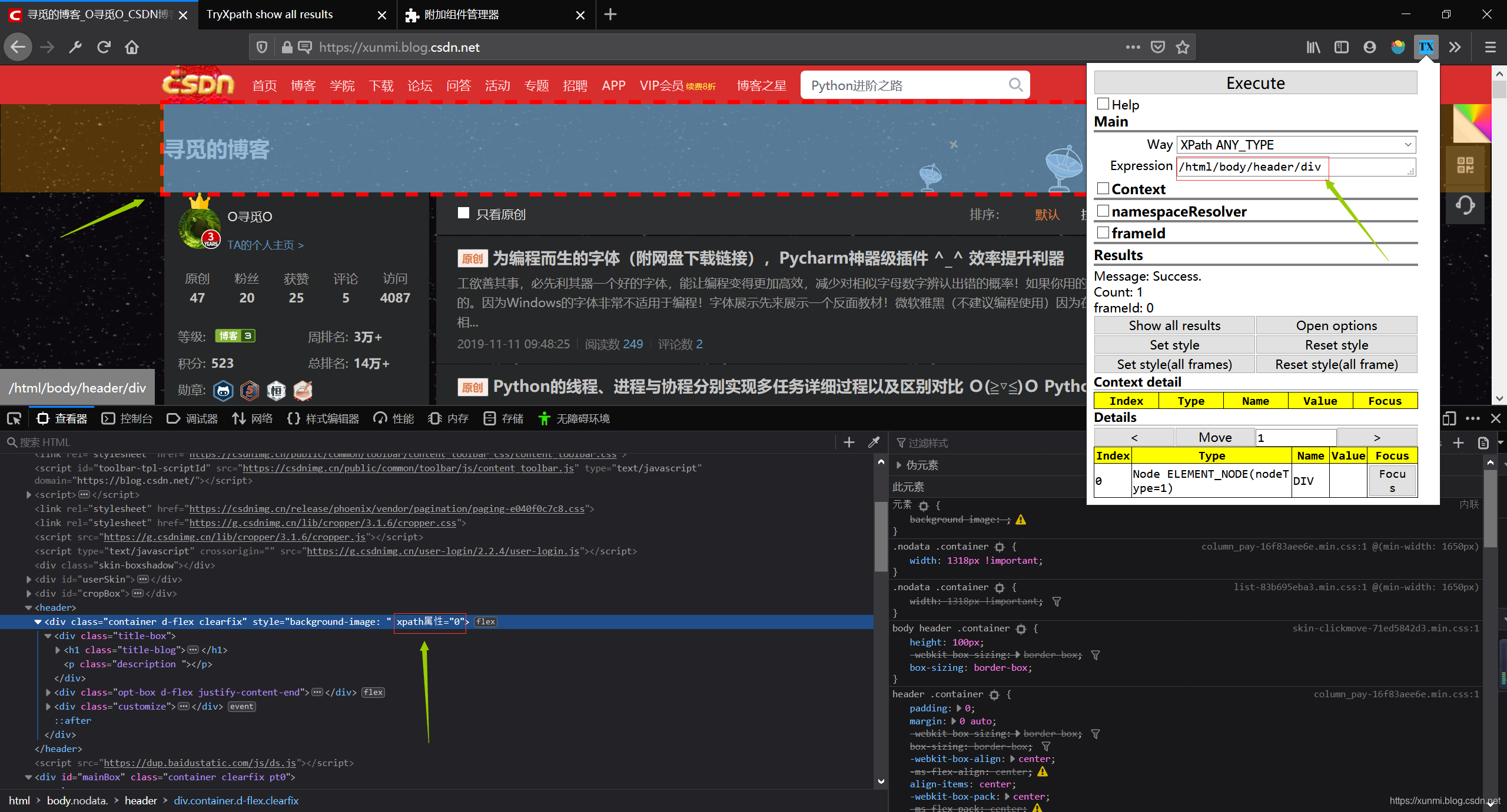
首先是常规使用,我们从根目录下寻找/html/body/header/div使用
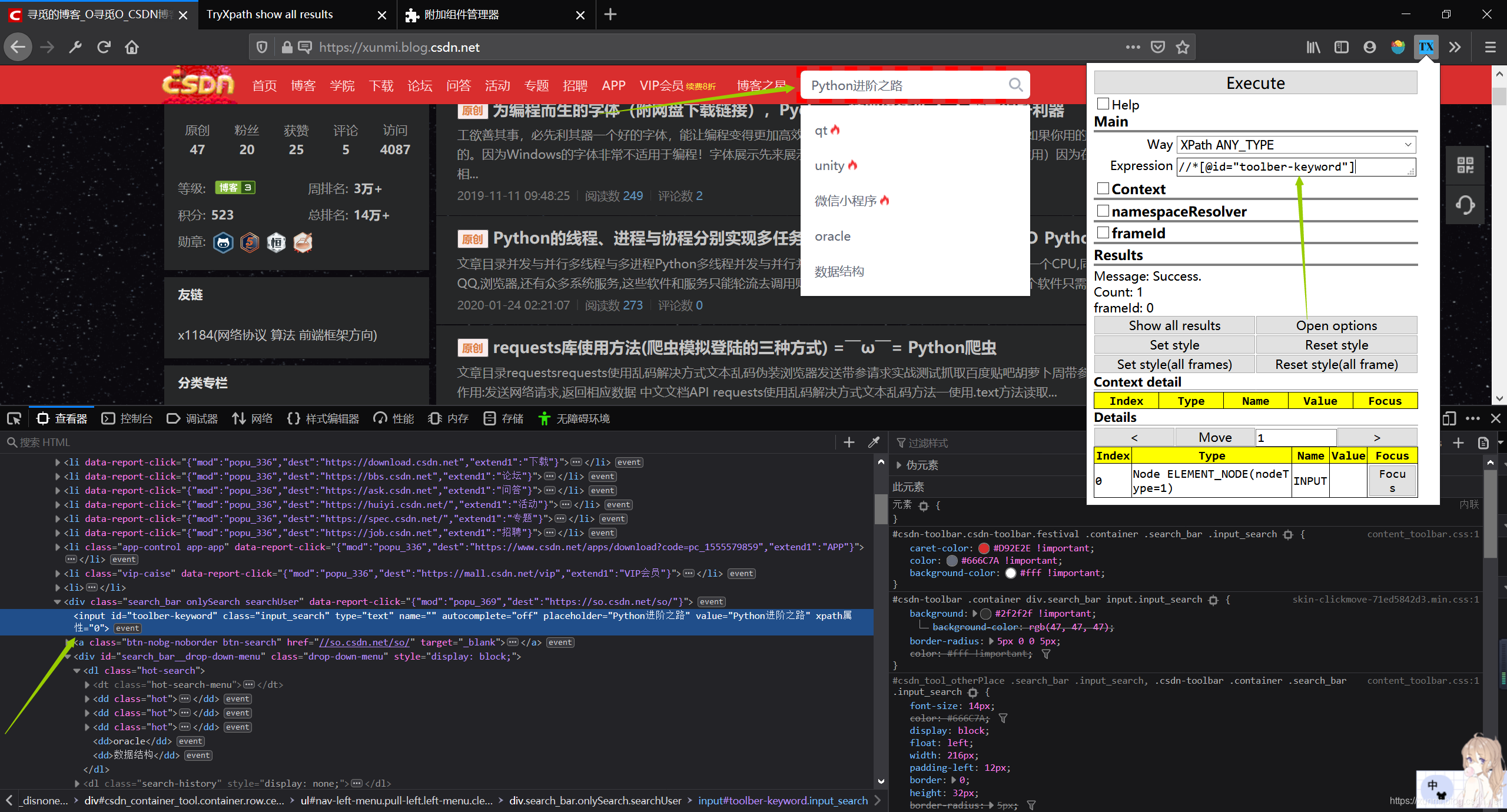
如果当前页面的存在独一无二的属性我们可以直接使用该属性来快速定位指定结点
//*[@id="toolber-keyword"]
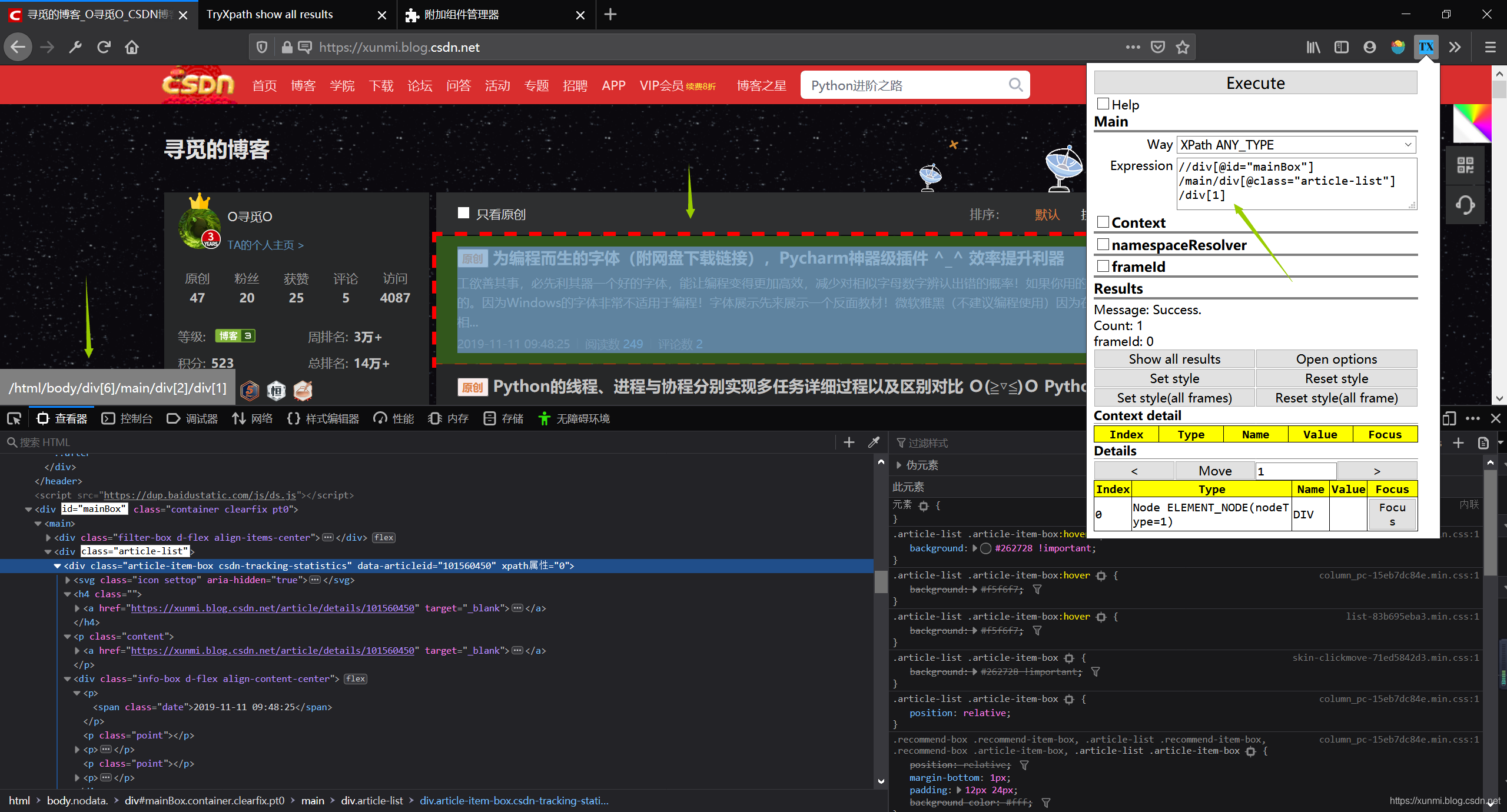
同一个地方可以有多种不同的xpath表达方式,就比如下图中可以用多种xpath表达
//div[@class="article-list"]/div[1]
/html/body/div[6]/main/div[2]/div[1]
//div[6]/main/div[2]/div[1]
lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
利用etree.HTML,将字符串转化为Element对象(转换时,当HTML标签缺少时,会自动修复)
etree.tostring(etree.HTML(html代码))使用以上方法即可修复标签缺少的HTML。
先将页面使用etree.HTML(html页面)方法转换后,即可使用.xpath()方法,如果需要读取文字,这需要使用text()来获取文本结点的内容
from lxml import etree
import requests
class xpath:
def __init__(self):
self.url = 'https://www.qq.com/'
self.header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
def get_Blog(self):
html = requests.get(self.url, self.header)
return html.text
def data_list(self, html_str):
html = etree.HTML(html_str)
items = html.xpath('//div[@class="nav-mod cf"]/ul/li/a/text()')
return items
def main(self):
html = self.get_Blog()
print(self.data_list(html))
if __name__ == '__main__':
start = xpath().main()
Beautiful Soup
Beautiful Soup和lxml比较类似,但使用起来更加简单,如果你之前对前端有所了解特别是对css比较熟悉,那么它对于你来说应该会非常容易上手使用。但Beautiful Soup相较于正则和lxml在效率上略低一些。
Beautiful Soup的官方文档非常详细,这里就简单介绍一下它的几个常用的方法。
首先我们需要使用.BeautifulSoup()方法将html转化为bs4.BeautifulSoup对象,
官方推荐使用lxmlBeautifulSoup(html, "lxml")因为lxml更加高效,速度更快,但如果使用lxml需要下载lxml库,可以使用html.parser,这是一个Python的内置库,所以无需下载即可使用BeautifulSoup(markup, "html.parser")。
转化后就可以使用find() 和 find_all()定位元素,方便快捷
使用.string可以获取单个标签中的值(如果是 find_all()取出的多个元素,使用会报错,可以遍历后在使用)如果tag中包含多个字符串,可以使用 .strings 获取多行值,如果需要去除多行中的空格与换行可以使用.stripped_strings
.select()也是常用的方法之一,他可以通过css样式来更准确的定位元素
class BS4:
def __init__(self):
self.html = """
<html>
<head>
<title>我是标签</title>
</head>
<body>
<div class="idiv">
<p>'我是p标签'
'我有一个换行符'</p>
<p>我是p标签</p>
</div>
<div class="i">
<ul>
<li class="text1 text2">class测试1</li>
<li class="text2">class测试2</li>
<li class="text3">class测试3</li>
<li id="text">测试</li>
</ul>
</div>
</body>
</html>
"""
def data_processing(self, html):
data = BeautifulSoup(html, 'lxml')
# 使用html标签快速查找
item1 = data.title
item2 = data.find('p')
items = data.find_all("li")
# .string可以获取标签中的值
print(item1, '\n', item2.string, '\n', items)
# 使用select方法可以更加精准的定位,items1与items2在这里定位到的对象相同
items1 = data.select('div[class="idiv"], div[class="i"]')
items2 = data.select('.idiv, .i')
for i in items1:
# 多行输出
print(list(i.strings))
for i in items2:
# 去除空格和换行符的多行输出
print(list(i.stripped_strings))
def run(self):
"""运行"""
self.data_processing(self.html)
if __name__ == '__main__':
BS4().run()
| Beautiful Soup常用方法小结 | 作用 |
|---|---|
.BeautifulSoup() |
转化html对象,官方推荐lxml,还可以使用html.parser、xml、html5lib |
find() |
寻找元素,优先找最先出现的第一个 |
find_all() |
寻找所以元素,将元素已返回值形式返回 |
.select() |
可以通过class等方式更加准确的定位元素 |
.string |
获取标签中的值 |
.strings |
获取多行标签中的值 |
.stripped_strings |
获取多行标签中的值并且去除空格 |
