
前言
相信各位爬虫小伙伴们在生活中肯定遇到过写了大半天才写出来的爬虫,好不容易运行起来,结果跑的贼慢,反正我是遇到过的。如今是大数据的时代,光会写爬虫根本没有什么竞争力,所以要学会对爬虫代码进行优化,优化爬虫的健壮性或者爬取速度等等,这些都能提高自己的竞争力,如果这篇博文能够对各位有所帮助的话,别忘了一键三连哦(^▽^)!
本文爬虫以糗事百科为例,以普通爬虫和多线程爬虫运行时间相比,相信大家都能领略到多线程的厉害之处!!!
如果对xpth不熟悉的话可以参靠我以下这篇博文
这篇博文看完了的话,可以继续进行多线程实战,参考我以下这篇博文
话不多说,开干!!!
1、普通爬虫
import requests
from lxml import etree
import time
import sys
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
#爬取
def Crawl(response):
e = etree.HTML(response.text)
#根据class值定位
span_text = e.xpath("//div[@class='content']/span[1]")
with open("duanzi.txt", "a", encoding="utf-8") as f:
for span in span_text:
info = span.xpath("string(.)")
f.write(info)
#main
if __name__ == '__main__':
//记下开始时间
start = time.time()
base_url = "https://www.qiushibaike.com/text/page/{}"
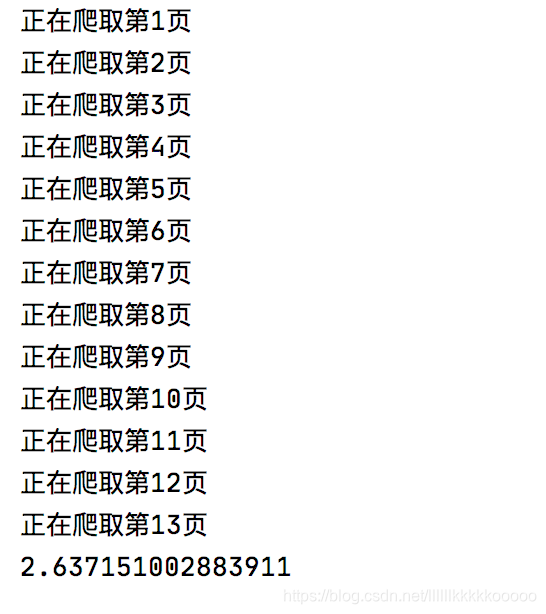
for i in range(1, 14):
#打印当前爬取的页数
print("正在爬取第{}页".format(i))
new_url = base_url.format(i)
#发送get请求
response = requests.get(new_url,headers=headers)
Crawl(response)
#记下结束时间
end = time.time()
#相减获取运行时间
print(end - start)

2、多线程爬虫
import requests
from lxml import etree
#Queue队列,先进先出
from queue import Queue
from threading import Thread
import time
#请求头
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
#数据获取
#继承Thread
class CrawlInfo(Thread):
#重写init函数
def __init__(self,url_queue,html_queue):
Thread.__init__(self)
self.url_queue = url_queue
self.html_queue = html_queue
# 重写run方法
def run(self):
while self.url_queue.empty()== False:
url = self.url_queue.get()
response = requests.get(url,headers=headers)
if response.status_code == 200:
#将数据放到队列中
self.html_queue.put(response.text)
#数据解析、保存
#继承Thread
class ParseInfo(Thread):
def __init__(self,html_queue):
Thread.__init__(self)
self.html_queue = html_queue
def run(self):
#判断队列是否为空。不为空则继续遍历
while self.html_queue.empty() == False:
#从队列中取最后一个数据
e = etree.HTML(self.html_queue.get())
span_text = e.xpath("//div[@class='content']/span[1]")
with open("duanzi.txt", "a", encoding="utf-8") as f:
for span in span_text:
info = span.xpath("string(.)")
f.write(info)
#开始
if __name__ == '__main__':
start = time.time()
#实例化
url_queue = Queue()
html_queue = Queue()
base_url = "https://www.qiushibaike.com/text/page/{}"
for i in range(1,14):
print("正在爬取第{}页".format(i))
new_url = base_url.format(i)
url_queue.put(new_url)
crawl_list = []
for i in range(3):
Crawl = CrawlInfo(url_queue,html_queue)
crawl_list.append(Crawl)
Crawl.start()
for crawl in crawl_list:
#join()等到队列为空,再执行别的操作
crawl.join()
parse_list = []
for i in range(3):
parse = ParseInfo(html_queue)
parse_list.append(parse)
parse.start()
for parse in parse_list:
parse.join()
end = time.time()
print(end - start)
3、运行对比
普通爬虫

多线程爬虫
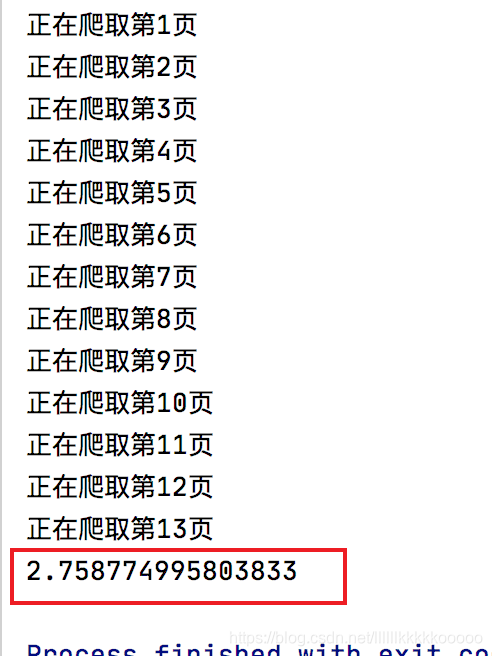
可能还有些小伙伴觉得这几秒钟的时间没什么大不了的,还是那句话,现在是大数据时代,动不动都是上百万、上千万的数据量,如果你还是只会写普通的爬虫代码,那么在学历拼不赢的前提下,你连技术页拼不赢,这才是最悲催的!!!
博主会持续更新,有兴趣的小伙伴可以点赞、关注和收藏下哦,你们的支持就是我创作最大的动力!
本文爬虫源码已由 GitHub https://github.com/2335119327/PythonSpider 已经收录(内涵更多本博文没有的爬虫,有兴趣的小伙伴可以看看),之后会持续更新,欢迎Star。