大家好,我是IT修真院西安分院第2期学员,一枚正直善良的java程序员。
今天给大家分享一下,修真院官网java任务三中可能会使用到的知识点:
如何写shell脚本?尝试自己编写一个简单脚本
1.背景介绍
Shell是什么?
Shell本身是一个用C语言编写的程序,它是用户使用Linux的桥梁。
Shell既是一种命令语言,又是一种程序设计语言。作为命令语言,它交互式地解释和执行用户输入的命令;作为程序设计语言,它定义了各种变量和参数,并提供了许多在高级语言中才具有的控制结构,包括循环和分支。
2.知识剖析
Shell有两种执行命令的方式:
•交互式(Interactive):解释执行用户的命令,用户输入一条命令,Shell就解释执行一条。
•批处理(Batch):用户事先写一个Shell脚本(Script),其中有很多条命令,让Shell一次把这些命令执行完,而不必一条一条地敲命令。Shell脚本和编程语言很相似,也有变量和流程控制语句,但Shell脚本是解释执行的,不需要编译,Shell程序从脚本中一行一行读取并执行这些命令,相当于一个用户把脚本中的命令一行一行敲到Shell提示符下执行。
Shell是一种脚本语言(即解释型语言),必须有解释器来执行这些脚本。
bash:bash是Linux系统默认使用的shell。bash由Brian Fox和Chet Ramey共同完成,是BourneAgain Shell的缩写,内部命令一共有40个。
ash:ash shell 是由Kenneth Almquist编写的,Linux中占用系统资源最少的一个小shell,它只包含24个内部命令,因而使用起来很不方便。
sh:sh 由Steve Bourne开发,是Bourne Shell的缩写,各种UNIX系统都配有sh。
3.常见问题
语法都正确但是运行报错
4.解决方案
设置文件格式为Unix :set fileformat=unix
5.编码实战
这里主要通过实现几个小功能来间接体会shell的使用:
统计访问多的ip
为了对Nginx日志文件里访问ip数和响应时间进行分析,需要学习shell脚本和一些命令的语法。
这里主要是通过Nginx的logs/access.log里的记录来分析,因为用户每一次访问都会在这里生成日志。
我们到达该目录下,执行cat access.log 可以看到里面所有日志
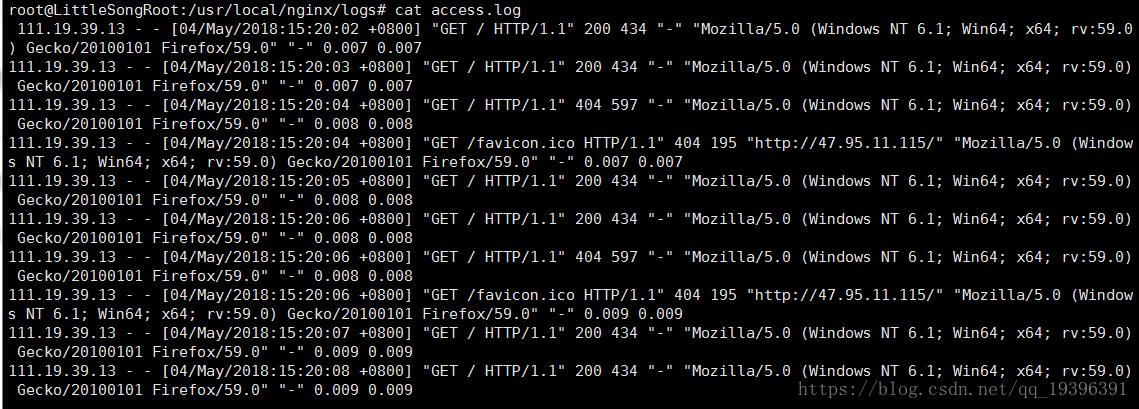
它们按照下面的格式排列
#设定日志格式,其中upstream_response_time是响应时间,request_time是请求时间
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" $request_time $upstream_response_time';
执行 cat access.log | awk '{print $1}' ,将上面数据第一列显示,也就是只显示ip。这条指令等价于awk '{print $1}' access.log;
执行awk '{print $NF}' access.log | sort ,
sort:会将 文件/文本 的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
注意到上面的参数换成了$NF,它指每一行最后一个字段,最后一个字段是响应时间,这样就得到了响应时间的升序排列。(因为我的日志了ip太少,对ip排序效果不明显)
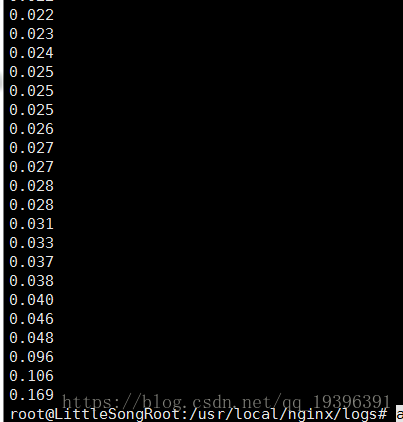
我上面只是对大量输出结果的少量截取,其实有很多重复的。
执行 awk '{print $NF}' access.log|sort| uniq -c
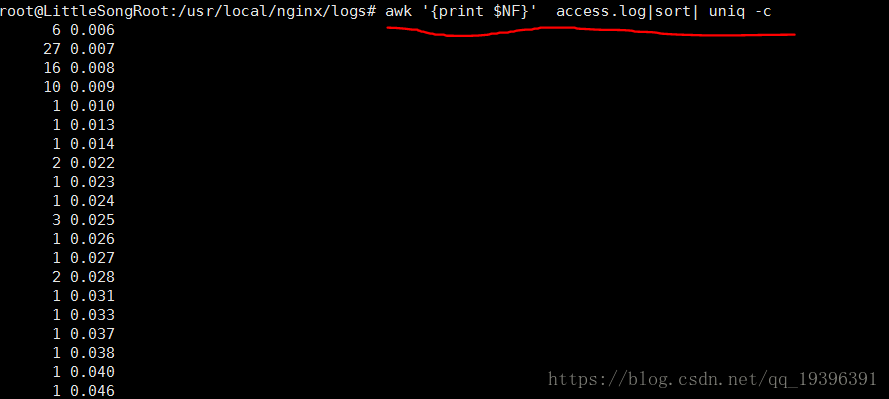
uniq会对前面的结果去重,加上 -c会在这一列前面显示它重复的次数,如上图。
其实我的目的是统计访问最多的ip,只是因为ip太少这里用响应时间来充当ip,那么可以对上面的结果安照重复出现的次数进行升序排序,awk '{print $NF}' access.log|sort| uniq -c | sort -n

加上 sort 后的 -n 表示按照数值的大小进行排序,如果不加,效果是以下:
可以看出它是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。这样显然不符合我们的需求。
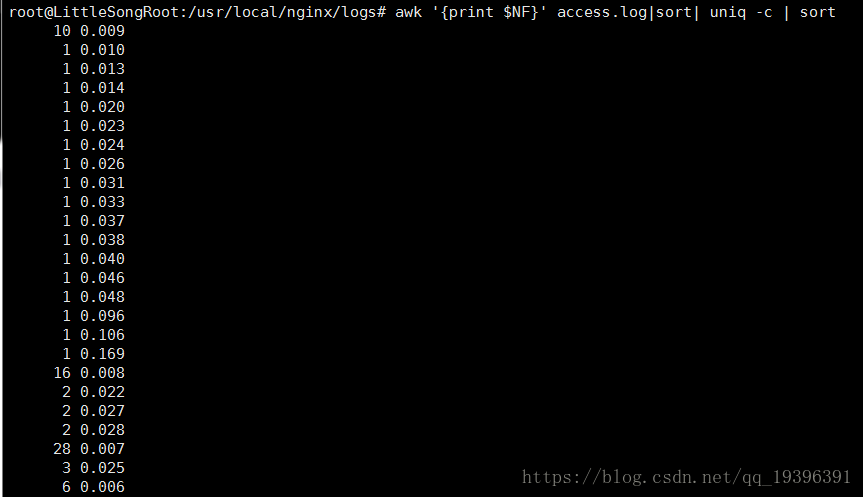
好,用上awk '{print $NF}' access.log|sort| uniq -c | sort -n ,得到了按照访问量的升序排序(假设它是ip)。但是我们希望一降序形式展示这样可以直观的看出访问量最多的那个。那么在先前的基础上加上 -r就可以了 。
总结:
在sort里:
# -n是按照数字大小排序,-r是以相反顺序,-k是指定需要排序的栏位。
所以最终:
awk '{print $NF}' access.log|sort| uniq -c | sort -n -k 1 -r |more
more : 分页查看文件内容。 如果内容不多,可以去掉它。
6.扩展思考
$0 、$1-$n 的使用
7.参考文献
http://man.linuxde.net/read (Linux命令大全)