绘图函数,以性别为例,绘制混淆矩阵
import matplotlib.pyplot as plt
import itertools
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
测试集的构造方法和训练集一样
import numpy as np
file_name = './data/test_querylist_writefile-1w.csv'
cur_model = gensim.models.Word2Vec.load('1w_word2vec_300.model')
with open(file_name, 'r') as f:
cur_index = 0
lines = f.readlines()
doc_cev = np.zeros((len(lines),300))
for line in lines:
word_vec = np.zeros((1,300))
words = line.strip().split(' ')
wrod_num = 0
for word in words:
if word in cur_model:
wrod_num += 1
word_vec += np.array([cur_model[word]])
doc_cev[cur_index] = word_vec / float(wrod_num)
cur_index += 1
检查一下数据有木有问题

建立一个基础预测模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(gender_train,genderlabel,test_size = 0.2, random_state = 0)
LR_model = LogisticRegression()
LR_model.fit(X_train,y_train)
y_pred = LR_model.predict(X_test)
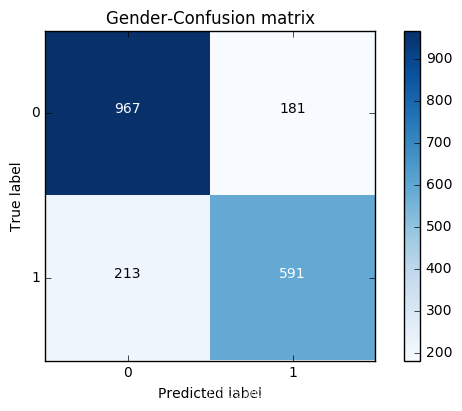
print (LR_model.score(X_test,y_test))
cnf_matrix = confusion_matrix(y_test,y_pred)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Gender-Confusion matrix')
plt.show()
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(gender_train,genderlabel,test_size = 0.2, random_state = 0)
RF_model = RandomForestClassifier(n_estimators=100,min_samples_split=5,max_depth=10)
RF_model.fit(X_train,y_train)
y_pred = RF_model.predict(X_test)
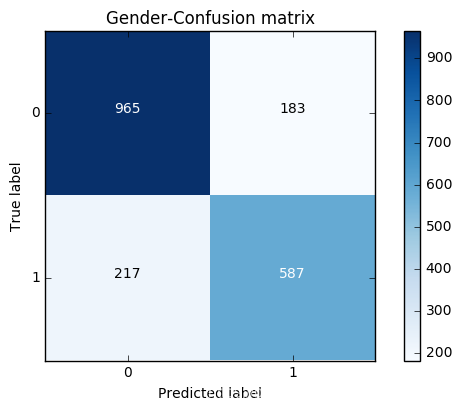
print (RF_model.score(X_test,y_test))
cnf_matrix = confusion_matrix(y_test,y_pred)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Gender-Confusion matrix')
plt.show()
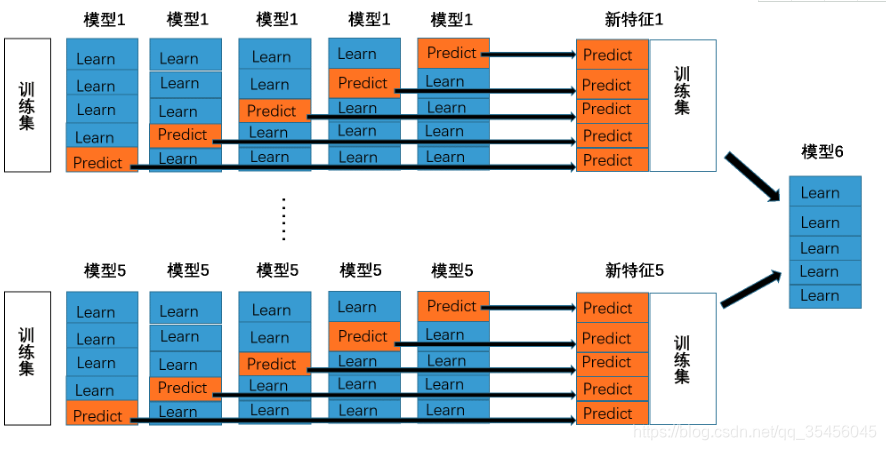
堆叠模型
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
clf1 = RandomForestClassifier(n_estimators=100,min_samples_split=5,max_depth=10)
clf2 = SVC()
clf3 = LogisticRegression()
basemodes = [
['rf', clf1],
['svm', clf2],
['lr', clf3]
]
from sklearn.cross_validation import KFold, StratifiedKFold
models = basemodes
folds = list(KFold(len(y_train), n_folds=5, random_state=0))
print (len(folds))
S_train = np.zeros((X_train.shape[0], len(models)))
S_test = np.zeros((X_test.shape[0], len(models)))
for i, bm in enumerate(models):
clf = bm[1]
for j, (train_idx, test_idx) in enumerate(folds):
X_train_cv = X_train[train_idx]
y_train_cv = y_train[train_idx]
X_val = X_train[test_idx]
clf.fit(X_train_cv, y_train_cv)
y_val = clf.predict(X_val)[:]
S_train[test_idx, i] = y_val
S_test[:,i] = clf.predict(X_test)
final_clf = RandomForestClassifier(n_estimators=100)
final_clf.fit(S_train,y_train)
print (final_clf.score(S_test,y_test))