转载自:数据管道
原作者介绍:双非院校刚毕业的统计硕士,目前在滴滴工作,有8个月的数据分析实习经历,面试过10位以上数据分析实习生,最终成为了产品经理。
在原文的基础上有过删减。
两个主题
本文的主要目标是帮助一些刚入门的同学了解互联网公司中“数据分析”岗位的部分信息,包括两个主题:
1、互联网公司中的初阶数据分析同学主要工作内容是什么,如何在工作中提升?
2、互联网公司的数据分析面试是怎么样的。
第一个问题帮助大家考虑是否进入这个行业工作,第二个问题帮助想进入这个行业的同学提升一些面试效率,这对面试者和面试官都有好处。
根据笔者在一些互联网公司的工作经历来看,目前数据分析的工作大方向有三个:
1、业务数据分析
2、偏向数仓开发的数据分析
3、偏向算法的数据分析
本篇文章主要围绕业务数据分析岗位展开。
01 互联网公司的数据分析面试是怎么样的
首先必须具备Sql编程能力,因为数据分析同学前期的主要工作就是写Sql语句,所以一般面试过程中会让大家当场写Sql题目,如果写不出来,那这次面试存在一定的风险。
Sql学习路径建议:
1.先看网课:https://www.bilibili.com/video/av9252479?p=26
2.在学了基础的Sql语句后,开始刷题,牛客网的:https://www.nowcoder.com/ta/sql
3.leetcode刷题:https://leetcode-cn.com/problemset/database/
确认Sql能力过关以后,会针对简历中的内容进行交流,主要先聊实习经历、其次是项目经历,最后是比赛经历(建议大家去实习),原因是我想看到你发挥出最好的一面,实习经历往往有老板带,如果你平时对于工作足够上心,那对于这个事情的前因后果就能够讲的较为清晰;项目经历肯定是有导师带,但这和导师的能力还有重视程度有关;而比赛经历更多时候可能就是同学们自己研究,容易出问题。
附上一个对于一个项目的示例提问:
简历内容:语音识别,提取了说话声纹,能够将声音和说话人匹配,准 确率达到94%;对原始音频使用了segan算法降低噪声,使用了cnn代替rnn神经网络,将准确率提升到了98%。
问题:
- segan降低噪声的原理是什么?
- 降低和不降低噪声,对结果的影响是多少?
- Rnn效果不如cnn的原因是什么?
- 为什么这里采用cnn,不考虑rcnn或者其他神经网络?
- 剩下2%判断不准确的原因主要是什么,还有优化方案嘛?
- 提升这4%带来的用户价值或者商业价值是什么?
我的被面试经历
以下列举我被问到的部分技术相关知识点。
- Sql中的左连接、右链接、内连接和全连接
- 星型模型和雪花模型
- 建模中碰到数据缺失怎么办
- 数据倾斜是什么,怎么处理
- Kmeans聚类的优缺点
- 如何确定kmeans聚类的类别数
拿到offer的核心影响因素:
第一个是Sql功底扎实,当时我把牛客网和leetcode上的所有Sql题目都写过了,所以能快速写出最优解;还有一个是脑子转的比较快,面试聊项目,被发现没做好的地方时,能马上补充现实背景,解释当时这样做的原因(圆回去)。
我的面试官经历
首先大家要对面试有一个正确的感知:面试官不是你的敌人,一个理想的面试经历,是在聊天过程中,面试官慢慢引导面试者证明他确实有能力来满足这个岗位,这里剖析下我作为面试官的一些观点,帮助大家来换位思考,提升面试效率。
-
各位同学都非常优秀,简历上各种奖项、实习经历琳琅满目,但大部分和岗位不相关。我是为了岗位招人,不是为了招个优秀的人再给他找岗位,因此请大家务必在简历中只写和岗位相关的经历,像荣誉称号、奖学金之类的可以简单一笔带过甚至不写,你要表现的不是你有多优秀,而是你有多匹配这个岗位,这里如果不知道岗位匹配条件,那是更前置的一个话题,暂不展开。
-
知之为知之,不知为不知。在面试中碰到不太会的东西直接告诉面试官:这块不是我的研究领域,我不懂,聊点别的吧。因为我们能接受你精力有限,无法面面俱到,但在一知半解的领域做回答会严重影响你的形象,这块内容会在后文细讲。
-
平等对话。这其实是一些trick,和专业水平无关,但能体现出面试者的心态,比如在面试官提问题的时候,“反杀”一波:这个问题提的不错,讲到核心要点了;或者“杠”一波:我觉得你说的没问题,但是当时的情况下我们没有这么做的原因是xx。这些一方面能表现出你的心态好,即你完全不紧张,甚至还想多说话;还有一方面是说明你已经脱离了被面试者的身份,进入了我的“同事”身份,我们在平等对话。
实际面试中,我都是“开卷考”,即在约面试的时候就告知:本次面试内容为Sql编程题和你简历中的项目,请好好准备。但百分之90%的同学卡在了Sql题环节,而且以往实习或者项目做的也一般导致没有通过。
以下是我的面试过程和其中发现部分同学可能存在的问题:
在面试最开始,我会先出几个sql题目「附录一是我每次面试都会出的题目」,先出一个中等难度的,如果面试者能写出来,就出一个稍微难一点的;如果面试者不会,我就会心中暗暗叹口气,然后出个简单题目缓解一下尴尬的气氛。
在聊完sql题目后,我会和面试同学聊简历中的实习或者项目经历,这里面我发现一个问题:数据分析同学很容易把自己当成“工具人”。举个例子,有个同学告诉我,他要将用户分组后给不同组的人发不同的优惠券,于是我问他分组依据怎么来的,不同组的用户区别在哪里,每一组怎么匹配的优惠券?
他回答:业务方决定的。
从面试者的角度来讲,这个问题已经讲清楚了,他把自己被要求做的事情完美的做完了,但从面试官的角度来讲,这个回答是不及格的,因为我觉得这个同学没有找到进步的方法,把自己当成了他人的工具,只做be told的事在工作和生活中是几乎无法进步的。
那如何避免自己成为“工具人”呢,一个比较好的方式是培养自己的owner心态:即我不是来给你仅仅提供一个帮助的,我要帮你把整件事情都搞定。
这里提供一个项目介绍模板,大家可以试着将自己的经历往里面套,查看自己对于历史项目的owner心态如何:
在多个司机投诉的背景下,我们发现了隔江派单问题(表象),这个问题是由于系统根据直线派单(内部原因)造成的,为了解决这个问题,我们(如果是你单个人就更好啦)提出了路面距离派单方法(最好有多个方法对比),这个方法的效果是解决了30%的隔江和隔山派单问题,使相关投诉下降了50%,我负责的是设计模型判断是否隔江派单,做完这个项目,我的成长是对于司机和派单有了更深的理解,如果让我重新做一次,我会前期多和司机交流,因为这样能使模型做的更快。
这里需要的不仅仅是了解,更多是思考和复盘,如果没有老板带领,学生思维的限定会让大家会很难意识到这个问题,这也是我建议大家多去实习的原因(提前感受社会的毒打,哈哈哈哈)。
聊项目的过程中,我们比较重视的是思维严谨。
思维严谨的例子:在验证一种药的效果时,需要分几组?答案:三组,一组吃药,一组不吃,一组吃外表一样却没有任何效果的假药,因为吃药可以分为“吃”和“药”两件事。引申出来的实际问题—–给用户发5元优惠券和商品直接降价5元效果一样嘛?如果不一样,哪种效果更好呢?为什么商家老是发一些根本不优惠的“优惠券”呢?
在这里推荐一本书《学会提问》,它能让你在工作中更高效的和人沟通,同时能锻炼你的逻辑思维能力,让大家一起变成“杠精”。
“知之为知之,不知为不知”,没有必要为了让简历更加丰富而写一些自己不太了解的东西,我现在看到数据分析同学简历中这类问题的重灾区包括以下两类:
(a)数学建模比赛。由于这个比赛往往没有专业导师指导且时间特别紧急,即使拿奖了,完成的质量也不高,比如我问一个,为什么在这里用这个方法?大部分同学的回答是因为xx论文也用了这个方法,几乎没有同学能够说出其他可行方法的优劣比较,其实我自己也参加过数学建模,发现这个问题连我自己也无法回答,因为时间太紧了,当时真的没有思考。我给出的对策是,数学建模比赛经历可以写,但不要主动去讲,更多作为一种经历,如果被聊到,直言这个比赛时间有限,有些地方不是特别严谨。
(b)机器学习、深度学习等算法。做数据的同学多多少少都学过点,也许还实现过网上的demo,但大部分同学的这个能力是达不到企业要求的,比如你说会神经网络,那梯度消失和梯度弥散总要知道吧,顺带的激活函数演变要了解吧;用过cnn,那cnn在图像领域效果比dnn好的原因有哪些。现在看到简历中有相关内容的,我都不敢主动开口聊,怕冷场,对此我给出的建议是如果没有学的很好,最好不要写,因为前段时间人工智能的火热,让懂这块的面试官越来越多,本来这块你不会也没事,但如果被发现学的不好反而会觉得你平时学习不够认真。
02 互联网公司中的初阶数据分析同学主要工作内容是什么
随着储存和收集数据成本的下降,公司往往收集了大量的用户数据,包括用户的每一次点击、查看等行为,随着用户数量的增加和经营时间的延长,我们的数据储存量越来越大(滴滴日均订单超过2千万),在如此大的数据量条件下,传统的excel几乎无法对数据进行操作,需要通过写Sql语句才能对数据进行处理。
因此初级数据分析同学平时大部分的工作时间在写Sql,在通过取了足够多的数据,有了足够的信息输入后,可以对业务现状提出问题和解决方案,听过一个观点,说数据分析同学是从数据角度看待业务发展的辅助决策同学,而我的观点是,数据分析应该是懂数据的业务同学(所以我直接跳到了业务方?)。
因此业务方向的数据分析同学提升自己的方式应该就是让自己多了解业务,很庆幸我在第一份的实习经历中,我的老板就一直强调让我去理解业务,他说你在给人做需求(取数)之前,一定要问清楚为什么要这个数,业务方是怎么看待这个数据和业务之间关系的,砍掉一个错误需求,比做十个正确需求对你的提升都大。
[附录一]
容易题
 每一行代表了这个订单的id、完成这个订单司机的id,这个订单的金额,订单完成时间,想要一个sql:如果某一天中,任何一个司机完成了5单及以上,且5单的总金额大于50元,把这天和对应的司机id输出。
每一行代表了这个订单的id、完成这个订单司机的id,这个订单的金额,订单完成时间,想要一个sql:如果某一天中,任何一个司机完成了5单及以上,且5单的总金额大于50元,把这天和对应的司机id输出。
输出列名:date,drier_id
知识点:子查询或者用having做筛选。
select date,drier_id from Order_make group by Drier_id where sum(Order_id)>=5 and sum(Amount)>=50;
中等题
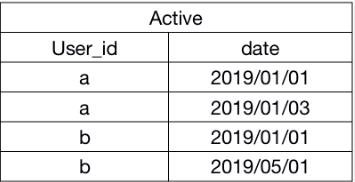
每一行代表这个用户是否在当天活跃过,如果一个用户在当天活跃过,且在未来的第2到第30天又活跃过,则称其为当天的活跃30天留存用户,比如表中a和b用户都在2019/1/1活跃了,a在2019/1/3活跃了,所以满足在2019/1/1的活跃30天留存条件,b没有在第2到第30天活跃过,因此不满足活跃30天留存。我想要每天的活跃用户数和活跃30天留存用户数
上表正确输出

知识点:留存的自连接写法,日期加减写法。
困难题:
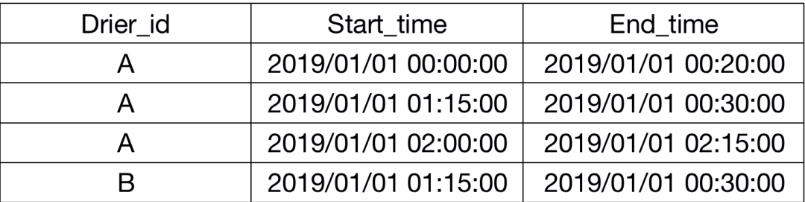
每行代表司机开始玩游戏的时间(start_time)和游戏结束时间(end_time),请问每个司机结束一场游戏后,平均多久时间内会开始下场游戏?如果司机只玩过一次游戏,就不计算该司机。
上表正确输出

