概述
通过11、12 篇的数据接收与处理,我们已经拿到了标准的计算模型,之后只剩下与流计算集成,即可完成实时的用户风险评估。
本篇将介绍项目中引入
Flink流计算框架的方案解决。
整体框架
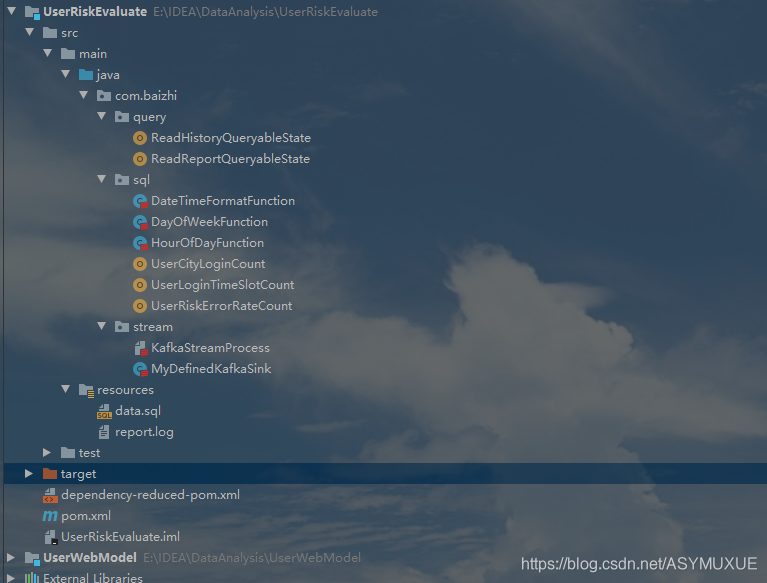
query 包中是对Flink中的可查询的状态数据的一些查询展示sql 包中是一些自定义的函数和离线数据处理的一些简单示例Flink Table apistream 包中是此次项目集成 flink 计算引擎完成实时流计算的代码
依赖坐标
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.baizhi</groupId>
<artifactId>UserRiskEvaluate</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!--引入评估模型-->
<dependency>
<groupId>com.baizhi</groupId>
<artifactId>EvaluateModel</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-filesystem -->
<!-- 流文件写入外围系统 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!--读取可查询的状态-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-queryable-state-client-java</artifactId>
<version>1.10.0</version>
</dependency>
<!--Flink Table API-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- Either... (for the old planner that was available before Flink 1.9) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--scala编译插件-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.0.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!--创建fatjar插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
流计算
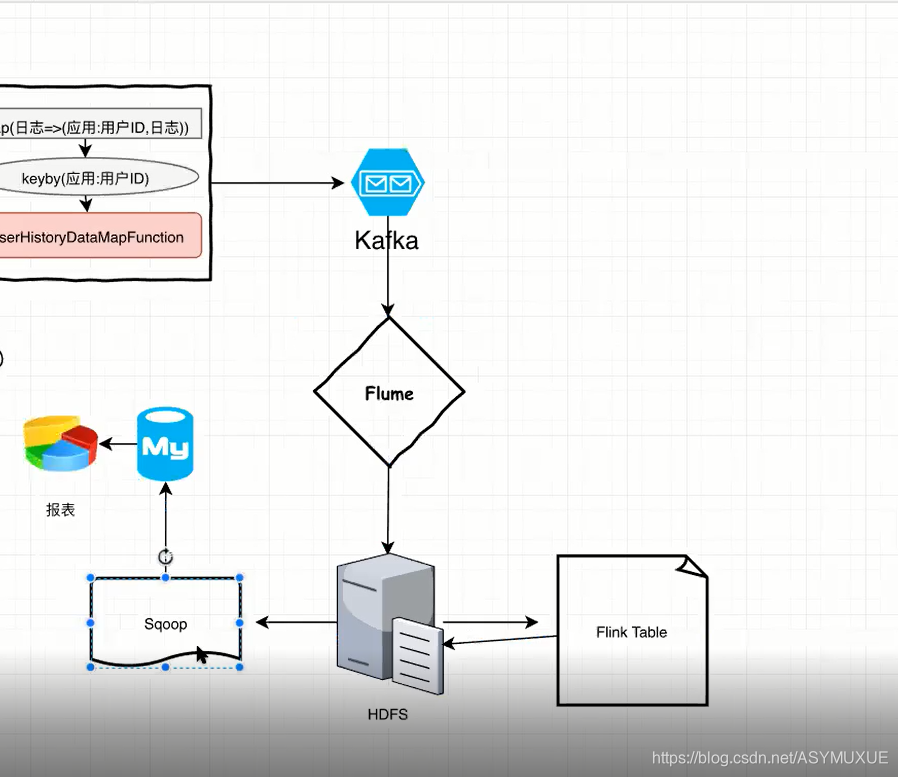
日志文件通过Flume收集之后发送到Kafka,我们将从Kafka中读取数据,提交给流计算引擎
我们的计算完成之后,评估报告将被写入Kafka,kafka 对接 Flume, 将数据沉降到 HDFS,最终,
- 1.使用Flink 的 table api 完成离线数据统计分析
- 2.通过Sqoop导出到MySQL,结合Echarts完成数据报表.
集成Filnk计算引擎
package com.baizhi.stream
import java.util.{Properties, ArrayList => JList}
import com.baizhi.entities.{EvaluateReport, HistoryData}
import com.baizhi.evaluate.impl._
import com.baizhi.evaluate.{Evaluate, EvaluateChain}
import com.baizhi.update.impl._
import com.baizhi.update.{Updater, UpdaterChain}
import com.baizhi.util.EvaluateUtil
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.api.common.state.StateTtlConfig.{StateVisibility, UpdateType}
import org.apache.flink.api.common.state._
import org.apache.flink.api.common.time.Time
import org.apache.flink.configuration.Configuration
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.codehaus.jackson.map.ObjectMapper
/**
* 1.将评估报告发送到kafka的topic中,topic_qq、topic_wx √
* 2.要求HistoryData状态以及EvaluateReport【有效时间1小时】redis协助完成
* 3.要求加入Flink的检查点机制,实现故障容错 √
* 4.要求系统需记录流计算的评估报告-持久化到HDFS √
*/
object KafkaStreamProcess {
def main(args: Array[String]): Unit = {
//1.获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//设置状态后端 1.路径
env.setStateBackend(new RocksDBStateBackend("hdfs:///DataAnalyze/RocksDBstateBackend_02",true))
//开启检查点
//每5秒检查一次,检查策略:精准一次
env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时时间
env.getCheckpointConfig.setCheckpointTimeout(4000)
//设置检查点的最小间隔时间
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//设置检查点的失败策略 失败即退出任务
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置任务取消检查点策略
//取消任务,自动保留检查点数据
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//创建配置文件
val properties = new Properties()
//设置路径
properties.setProperty("bootstrap.servers", "pro1:9092")
//设置消费组
properties.setProperty("group.id", "group01")
//3.读源 (1.消费主题,2.反序列化,3.传入配置文件)
val value = env.addSource(new FlinkKafkaConsumer[String]("topic_logback",new SimpleStringSchema,properties))
println("=====执行流计算=====")
//创建一个状态描述器(结果查询)
val resultStateDescriptor = new ValueStateDescriptor[(String,String)]("resultStateDescriptor",createTypeInformation[(String,String)])
//3.执行DataStream的转换算子
var report = value.filter(EvaluateUtil.isLegal(_))
.map(line=> (EvaluateUtil.getApplicationName(line)+":"+EvaluateUtil.getUserIdentify(line),line))
.keyBy(x => x._1)
.map(new UserDefinedMapFunction)
.filter(_ != null)
.map(r=>(r.getApplicationName+":"+r.getUserIdentify,r.toString))
/**
* 向kafka写的方案
//设置属性
val properties2 = new Properties()
//设置路径
properties2.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "pro1:9092")
//设置批大小
properties2.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"100")
//设置频次
properties2.setProperty(ProducerConfig.LINGER_MS_CONFIG,"500")
//Semantic.EXACTLY_ONCE:开启kafka幂等写特性
//Semantic.AT_LEAST_ONCE:开启Kafka Retries机制
val kafkaSink = new FlinkKafkaProducer[(String,String)]("topic_qq",new MyDefinedKafkaSink,properties2,Semantic.AT_LEAST_ONCE)
report.addSink(kafkaSink)
*/
//创建一个流文件的沉降路径 1.路径 2.文件夹格式
val value1: StreamingFileSink[(String, String)] = StreamingFileSink.forRowFormat(new Path("hdfs://pro1:9000/DataAnalyze/reportSink_02/"),
new SimpleStringEncoder[(String, String)]("UTF-8"))
.withBucketAssigner(new DateTimeBucketAssigner[(String, String)]("yyyy-MM-dd")) //设置桶表的命名格式
.build()
//结果处理
report.addSink(value1)
//4.将计算的结果在控制打印
//5.执行流计算任务
env.execute("Window Stream WordCount")
}
}
class UserDefinedMapFunction extends RichMapFunction[(String,String),EvaluateReport]{
//提供状态变量
var historyState:ValueState[String]=_
//提供一个报告可查询
var reportState:MapState[String,String]=_
//提供访问次数的状态
var loginCountState:ValueState[Int]=_
//提供成员变量
var updateList:JList[Updater]= _
var evaluateList:JList[Evaluate]=_
//初始化状态
override def open(parameters: Configuration): Unit = {
//创建状态描述器
var historyStateDescriptor = new ValueStateDescriptor[String]("historyStatedes",createTypeInformation[String])
var loginCountStateDescriptor = new ValueStateDescriptor[Int]("loginCountStatedes",createTypeInformation[Int])
var reportStateDescriptor = new MapStateDescriptor[String,String]("reportStateDes",createTypeInformation[String],createTypeInformation[String])
//配置可查询的状态
historyStateDescriptor.setQueryable("historyQuery")
reportStateDescriptor.setQueryable("reportQuery")
//开启访问次数的过期时间,以一天为准
//开启numLoginCount TTL特性、设置为1天以内
val ttlConfig = StateTtlConfig.newBuilder(Time.days(1))
.cleanupFullSnapshot() //设置快照清除
.cleanupInRocksdbCompactFilter(1000) //设置RocksDB清除策略
.setUpdateType(UpdateType.OnCreateAndWrite)//只有修改操作,才会更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //设置过期数据永不返回
.build()
//配置TTL
loginCountStateDescriptor.enableTimeToLive(ttlConfig)
//初始化状态
historyState = getRuntimeContext.getState(historyStateDescriptor)
loginCountState = getRuntimeContext.getState(loginCountStateDescriptor)
reportState = getRuntimeContext.getMapState(reportStateDescriptor)
updateList= new JList[Updater]()
//创建历史数据更新的链属性
updateList.add(new CitiesUpdates)
updateList.add(new DeviceUpdates(3))
updateList.add(new InputFeaturesUpdater())
updateList.add(new LastLoginGeoPoint())
updateList.add(new LoginTimeUpdater())
updateList.add(new PasswordsUpdates())
updateList.add(new TimeSlotUpdater())
//创建评估链的属性
evaluateList = new JList[Evaluate]()
evaluateList.add(new AreaEvaluate())
evaluateList.add(new DeviceEvaluate())
evaluateList.add(new InputFeatureEvaluate())
evaluateList.add(new SimilarityEvaluate(0.9))
evaluateList.add(new SpeedEvaluate(750.0))
evaluateList.add(new TimeSlotEvaluate(1))
evaluateList.add(new TotalEvaluate(2))
}
override def map(value: (String, String)): EvaluateReport = {
//使用jackson序列化和反序列化
val mapper = new ObjectMapper()
//如果历史数据不存在,则创建历史数据
var historyDataJson = historyState.value()
//创建一个历史数据,用于储存真实历史数据
var historyData:HistoryData= null
if( historyDataJson == null){
historyData = new HistoryData()
}else{
//通过jackson的反序列化
historyData = mapper.readValue(historyDataJson,classOf[HistoryData])
}
//判断日志类型
//如果是登录成功的数据
if(EvaluateUtil.isLoginSuccess(value._2)){
//解析
val successData = EvaluateUtil.parseLoginSuccessData(value._2)
//从状态中取出当前天的登录次数
historyData.setCurrentDayLoginCount(loginCountState.value());
//创建一个更新链
val updaterChain = new UpdaterChain(updateList)
//进行数据更新
updaterChain.doChain(successData,historyData)
//进行状态存储
historyState.update(mapper.writeValueAsString(historyData))
loginCountState.update(loginCountState.value()+1)
println("状态数据"+loginCountState.value()+"历史数据"+historyState.value())
}
//如果是验证数据
if(EvaluateUtil.isEvaluate(value._2)){
//解析
val evaluateData = EvaluateUtil.parseEvaluateData(value._2);
//创建评估链
val evaluateChain = new EvaluateChain(evaluateList)
//创建一个报告
val report = new EvaluateReport(evaluateData.getApplicationName,
evaluateData.getUserIdentify,
evaluateData.getLoginSequence,
evaluateData.getEvaluateTime,
evaluateData.getCityName,
evaluateData.getGeoPoint
)
//进行评估
evaluateChain.doChain(evaluateData,historyData,report)
reportState.put(evaluateData.getUserIdentify,mapper.writeValueAsString(report))
return report
}
return null
}
}
自定义的Kafka沉浸规则
package com.baizhi.stream
import org.apache.flink.streaming.util.serialization.KeyedSerializationSchema
class MyDefinedKafkaSink extends KeyedSerializationSchema[(String,String)]{
override def serializeKey(t: (String, String)): Array[Byte] = {
t._1.getBytes()
}
override def serializeValue(t: (String, String)): Array[Byte] = {
t._2.getBytes()
}
override def getTargetTopic(t: (String, String)): String = {
if(t._1.equals("QQ")) return "topic_qq"
else return "topic_wx"
}
}
附加一:状态查询
在,上述流计算中,有3个状态值:
1,历史数据
2.每天的登录次数
3.评估报告
- 业务系统可以通过,查询评估报告,完成用户登录风险的等级评定
此处属于 异步实现
同步实现:业务系统进行登录风险的评估计算,需要云计算暴露 ”历史数据的查询接口”
查询历史数据:
package com.baizhi.query
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.common.{ExecutionConfig, JobID}
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.queryablestate.client.QueryableStateClient
object ReadHistoryQueryableState {
def main(args: Array[String]): Unit = {
//创建一个可查询客户端
val client = new QueryableStateClient("pro1",9069)
//设置jobID
val id = JobID.fromHexString("d9751ed5b01767a4c83025351b58527e")
//设置查询的状态名
val name = "historyQuery"
//设置key的类型
val ty: TypeInformation[String] = createTypeInformation[String]
//创建一个状态描述器
val des = new ValueStateDescriptor[String]("historyDataState",createTypeInformation[String].createSerializer(new ExecutionConfig))
// val des2 = new ValueStateDescriptor[(String,String)]("reportQueryStateDes",createTypeInformation[(String,String)])
//查询,获取完整的查询结果
val result = client.getKvState(id,name,"WX:张三",ty,des)
// val result2: CompletableFuture[ValueState[(String, String)]] = client.getKvState(id,name,"QQ",ty,des2)
//同步获取结果
val state = result.get()
//输出
println(state.value())
//结束
client.shutdownAndWait()
//停止
client.shutdownAndWait()
}
}
- 附测试数据,直接向kafka 生产者发送
INFO 2020-04-03 10:12:00 WX SUCCESS [张三] 6ebaf4ac780f40f486359f3ea6934623 “456123” Zhengzhou “114.4,34.5” [1400,16000,2100] “Mozilla/8.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36”
INFO 2020-04-02 10:50:00 QQ SUCCESS [张三] 6ebaf4ac780f40f486359f3ea6934622 “123456” Beijing “116.4,39.5” [1300,17000,2200] “Mozilla/7.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36”
INFO 2020-04-02 10:52:00 QQ EVALUATE [张三] 6ebaf4ac780f40f486359f3ea6934622 “123456” Beijing “116.4,39.5” [1300,17000,2200] “Mozilla/7.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36”
INFO 2020-04-03 10:54:01 WX EVALUATE [张三] 6ebaf4ac780f40f486359f3ea6934620 “123458” Zhengzhou “114.4,34.5” [1250,14000,2000] “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36”
查询评估报告
package com.baizhi.query
import org.apache.flink.api.common.state.{MapState, MapStateDescriptor}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.common.{ExecutionConfig, JobID}
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.queryablestate.client.QueryableStateClient
object ReadReportQueryableState {
def main(args: Array[String]): Unit = {
//创建一个可查询客户端
val client = new QueryableStateClient("pro1",9069)
//设置jobID
val id = JobID.fromHexString("d9751ed5b01767a4c83025351b58527e")
//设置查询的状态名
val name = "reportQuery"
//设置key的类型
val ty: TypeInformation[String] = createTypeInformation[String]
//创建一个状态描述器
val des = new MapStateDescriptor[String,String]("reportDataState",
createTypeInformation[String].createSerializer(new ExecutionConfig),
createTypeInformation[String].createSerializer(new ExecutionConfig))
//查询,获取完整的查询结果
val result = client.getKvState(id,name,"WX:张三",ty,des)
//同步获取结果
val state: MapState[String, String] = result.get()
//输出
println(state.entries())
//停止
client.shutdownAndWait()
}
}
附加二:离线计算
通过获取写入到 HDFS 的数据,我们可以完成一些离线分析计算
这里以 本地的文件数据为离线计算实例:
QQ 张三 6ebaf4ac780f40f486359f3ea6934620 1585620720000 Beijing 116.4,39.5 false true false true false true false
QQ 张三 6ebaf4ac780f40f486359f3ea6934620 1585620720000 Zhengzhou 116.4,39.5 true true false true false true false
WX 张三 6ebaf4ac780f40f486359f3ea6934620 1585620720000 Beijing 116.4,39.5 true true false true false true false
QQ 张三 6ebaf4ac780f40f486359f3ea6934620 1585620720000 Beijing 116.4,39.5 true true false true false true false
定制一些函数
- 时间格式函数
package com.baizhi.sql
import java.text.SimpleDateFormat
import java.util.{Calendar, Date}
import akka.io.SimpleDnsCache
import org.apache.flink.table.functions.ScalarFunction
class DateTimeFormatFunction extends ScalarFunction{
def eval(time: Long): String = {
val sdf = new SimpleDateFormat("yyyy-MM-dd")
sdf.format(time)
}
}
- 计算某个时间的对应星期几函数
package com.baizhi.sql
import java.text.DecimalFormat
import java.util.{Calendar, Date}
import org.apache.flink.table.functions.ScalarFunction
class DayOfWeekFunction extends ScalarFunction{
def eval(time: Long): String = {
var WEEKS:Array[String]=Array("星期日","星期一","星期二","星期三","星期四","星期五","星期六")
val calendar = Calendar.getInstance()
calendar.setTime(new Date(time))
WEEKS(calendar.get(Calendar.DAY_OF_WEEK)-1)
}
}
- 计算某个时间的对应时刻函数
package com.baizhi.sql
import java.text.DecimalFormat
import java.util.{Calendar, Date}
import org.apache.flink.table.functions.ScalarFunction
class HourOfDayFunction extends ScalarFunction{
def eval(time: Long): String = {
val calendar = Calendar.getInstance()
calendar.setTime(new Date(time))
val format = new DecimalFormat("00")
format.format(calendar.get(Calendar.HOUR_OF_DAY))
}
}
离线分析计算
- 计算用户登录城市评估因子触发率
package com.baizhi.sql
import java.math.{BigDecimal => JBigDecimal}
import java.text.SimpleDateFormat
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.scala.{BatchTableEnvironment, _}
object UserCityLoginCount {
def main(args: Array[String]): Unit = {
val fbEnv = ExecutionEnvironment.getExecutionEnvironment
val fbTableEnv = BatchTableEnvironment.create(fbEnv)
val sdf= new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val dataSet:DataSet[(String,String,String,String,String,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean)] = fbEnv.readTextFile("E:\\IDEA\\DataAnalysis\\UserRiskEvaluate\\src\\main\\resources\\report.log",
"utf-8")
.map(_.split("\\s+"))
.map(ts => (ts(0),ts(1),sdf.format(ts(3).toLong),ts(4),ts(5),ts(6).toBoolean,
ts(7).toBoolean,ts(8).toBoolean,ts(9).toBoolean,ts(10).toBoolean,ts(11).toBoolean,ts(12).toBoolean))
val table = fbTableEnv.fromDataSet(dataSet,'appName,'userIdentified,'evaluateTime,'cityName,'geoPoint,'area,'device,'inputfeature, 'similarity, 'speed,'timeslot,'total)
//注册视图
fbTableEnv.createTemporaryView("t_report",table)
var start="2020-03-01"
var end="2020-04-03"
//计算因子触发率
val sql=
s"""
select appName,cityName,count(*) from (select * from t_report where evaluateTime between '${start}' and '${end}')
group by appName,cityName
"""
fbTableEnv.sqlQuery(sql)
.addColumns(s"'${start}' as start")
.addColumns(s"'${end}' as end")
.toDataSet[(String,String,Long,String,String)]
.print()
}
}
- 计算评估用户登录习惯因子的触发率
package com.baizhi.sql
import java.text.SimpleDateFormat
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.io.jdbc.JDBCAppendTableSinkBuilder
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.scala.{BatchTableEnvironment, _}
object UserLoginTimeSlotCount {
def main(args: Array[String]): Unit = {
val fbEnv = ExecutionEnvironment.getExecutionEnvironment
val fbTableEnv = BatchTableEnvironment.create(fbEnv)
val dataSet:DataSet[(String,String,Long,String,String,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean)] = fbEnv.readTextFile("E:\\IDEA\\DataAnalysis\\UserRiskEvaluate\\src\\main\\resources\\report.log",
"utf-8")
.map(_.split("\\s+"))
.map(ts => (ts(0),ts(1),ts(3).toLong,ts(4),ts(5),ts(6).toBoolean,
ts(7).toBoolean,ts(8).toBoolean,ts(9).toBoolean,ts(10).toBoolean,ts(11).toBoolean,ts(12).toBoolean))
val table = fbTableEnv.fromDataSet(dataSet,'appName,'userIdentified,'evaluateTime,'cityName,'geoPoint,'area,'device,'inputfeature, 'similarity, 'speed,'timeslot,'total)
//注册视图
fbTableEnv.createTemporaryView("t_report",table)
fbTableEnv.registerFunction("hourOfDayFunction",new HourOfDayFunction)
fbTableEnv.registerFunction("dayOfWeekFunction",new DayOfWeekFunction)
fbTableEnv.registerFunction("dateTimeFormatFunction",new DateTimeFormatFunction)
//计算因子触发率
val sql=
s"""
select appName,userIdentified,timeslot,dayofWeek,count(*) as total
from
( select appName,userIdentified,
hourOfDayFunction(evaluateTime) as timeslot,
dayOfWeekFunction(evaluateTime) as dayofWeek
from t_report
)
group by appName,userIdentified,timeslot,dayofWeek
"""
fbTableEnv.sqlQuery(sql)
.toDataSet[(String,String,String,String,Long)]
.print()
}
}
计算全部因子触发率
计算完成之后向MySQL数据库写入,建表语句:
CREATE table error_rate(
app_name VARCHAR(128),
area_rate double ,
device_rate double,
inputfeature_rate double,
similarity_rate double,
speed_rate double,
timeslot_rate double,
total_rate double,
start VARCHAR(128),
end VARCHAR(128)
)
代码实现:
package com.baizhi.sql
import java.text.SimpleDateFormat
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.table.api.scala.BatchTableEnvironment
import org.apache.flink.table.api.scala._
import org.apache.flink.api.scala._
import java.math.{BigDecimal => JBigDecimal}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.io.jdbc.JDBCAppendTableSinkBuilder
import org.apache.flink.api.scala.typeutils.Types
object UserRiskErrorRateCount {
def main(args: Array[String]): Unit = {
val fbEnv = ExecutionEnvironment.getExecutionEnvironment
val fbTableEnv = BatchTableEnvironment.create(fbEnv)
val sdf= new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val dataSet:DataSet[(String,String,String,String,String,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean)] = fbEnv.readTextFile("E:\\IDEA\\DataAnalysis\\UserRiskEvaluate\\src\\main\\resources\\report.log",
"utf-8")
.map(_.split("\\s+"))
.map(ts => (ts(0),ts(1),sdf.format(ts(3).toLong),ts(4),ts(5),ts(6).toBoolean,
ts(7).toBoolean,ts(8).toBoolean,ts(9).toBoolean,ts(10).toBoolean,ts(11).toBoolean,ts(12).toBoolean))
val table = fbTableEnv.fromDataSet(dataSet,'appName,'userIdentified,'evaluateTime,'cityName,'geoPoint,'area,'device,'inputfeature, 'similarity, 'speed,'timeslot,'total)
//注册视图
fbTableEnv.createTemporaryView("t_report",table)
table.select("appName, userIdentified,evaluateTime,cityName,geoPoint,area,device,inputfeature,similarity, speed,timeslot,total")
.toDataSet[(String,String,String,String,String,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean)]
.print()
var tableSink = new JDBCAppendTableSinkBuilder()
.setDBUrl("jdbc:mysql://localhost:3306/test")
.setDrivername("com.mysql.jdbc.Driver")
.setUsername("root")
.setPassword("root")
.setBatchSize(1000)
.setQuery("INSERT INTO error_rate(app_name,area_rate,device_rate,inputfeature_rate,similarity_rate,speed_rate,timeslot_rate,total_rate,total,start,end) values(?,?,?,?,?,?,?,?,?,?,?)")
.setParameterTypes(Types.STRING, Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.INT,Types.STRING, Types.STRING)
.build();
fbTableEnv.registerTableSink("Result",
Array("app_name","area_rate","device_rate","inputfeature_rate","similarity_rate","speed_rate","timeslot_rate","total_rate","total","start","end"),
Array[TypeInformation[_]](Types.STRING, Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.INT, Types.STRING, Types.STRING),
tableSink)
var start="2020-03-01"
var end="2020-04-03"
//计算因子触发率
val sql=
s"""
select appName,
round(sum(case area when true then 1.0 else 0 end)/count(area),2) as area_rate,
round(sum(case device when true then 1.0 else 0 end)/count(device),2) as device_rate,
round(sum(case inputfeature when true then 1.0 else 0 end)/count(inputfeature),2) as inputfeature_rate,
round(sum(case similarity when true then 1.0 else 0 end)/count(similarity),2) as similarity_rate,
round(sum(case speed when true then 1.0 else 0 end)/count(speed),2) as speed_rate,
round(sum(case timeslot when true then 1.0 else 0 end)/count(timeslot),2) as timeslot_rate,
round(sum(case total when true then 1.0 else 0 end)/count(total),2) as total_rate,
count(*) as total
from (select * from t_report where evaluateTime between '${start}' and '${end}')
group by appName
"""
fbTableEnv.sqlQuery(sql)
.addColumns(s"'${start}' as start")
.addColumns(s"'${end}' as end")
.toDataSet[(String,JBigDecimal,JBigDecimal,JBigDecimal,JBigDecimal,JBigDecimal,JBigDecimal,JBigDecimal,Long,String,String)]
.print()
}
}
至此,我们的项目几近尾声,后续可能会有所补充
附
附上 风险流计算评估模块的完整源码:
https://pan.baidu.com/s/1lP0fPdCFd-2ACDE23Ih4lw 提取码:lagk
