1. 什么是知识图谱
第一种理解:知识图谱本质上是语义网络。本体论是语义网络中最重要的一个要素。
第二种理解:知识图谱也叫做多关系图,由多种类型的节点和多种类型的边组成。课程以第二种理解为主。
2. 构建知识图谱所需要的技术
-
数据获取:数据爬取(公开,半公开数据,其中半公开的数据指的是需要验证码识别或者模拟登陆的数据)、数据库读取(业务数据)。
-
数据预处理:数据清洗(例如字段对齐)、知识抽取、消歧分析等。知识抽取以互联网金融风控为例,假如关心的是文本中跟风险相关的敏感词(如骗子、诈骗),通过知识抽取从非结构化数据中提取出这些敏感词。消歧分析比如在填写表格时以不同的方式来填写公司名称(如百度、百度技术有限公司等)、公司地址。虽然形式不同,但是指代的是同一个实体。
-
导入数据到知识图谱
3.1 数据筛选(决定哪些数据需要到知识图谱系统,需要考虑产品的性能和业务要求)
3.2 知识图谱设计(本身设计,类似MySQL数据库设计,表的改变会影响应用层的改变,建议至少花费20%~30%的时间)
3.3 批量导入(初次导入历史数据,最大的挑战:数据量比较大时的性能和效率)
3.4 增量导入(线上实时导入)
- 应用层的搭建:各类模型搭建(如风控模型)、GraphX分布式处理(sparkX)、微服务(springcloud,对接到线上的系统)
3. 知识图谱的应用场景
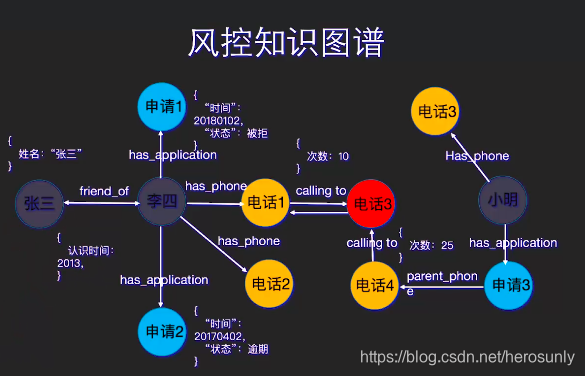
- 风控知识图谱,用来做风险控制,对于线上贷款的公司来说,最大的诉求点就是风控,需要准确地判断一个人的风险有多大,这样才能做出要不要给这个人贷款的决定。知识图谱最大的作用在于它可以从关系的角度去分析问题,从而找到一些潜在的风险。比如可以用下图去挖掘团体欺诈,这样的欺诈其实从一个审核人员的角度是很难去发现的。
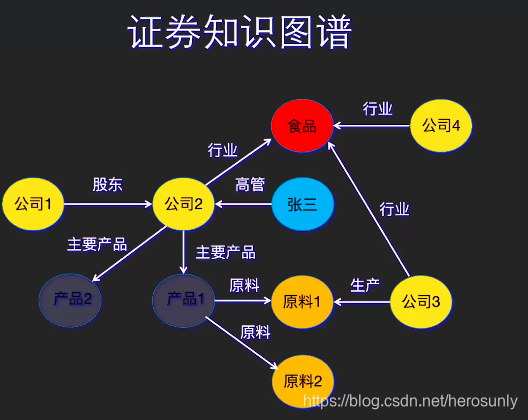
- 证券知识图谱:当我们去买股票的时候,经常关心这样的问题,比如一个事件发生了可能会影响那些股票上涨或者下跌。这个问题的本质就是我们需要分析一个事件和一支股票或者公司之间的关系,这种关系可以从图谱里挖掘出来。再比如一个股票上涨了有哪些股票也会随之上涨,这跟问题的本质是我需要分析公司与公司之间潜在的关系。这样的关系也可以从这样的证券知识图谱中挖掘出来。
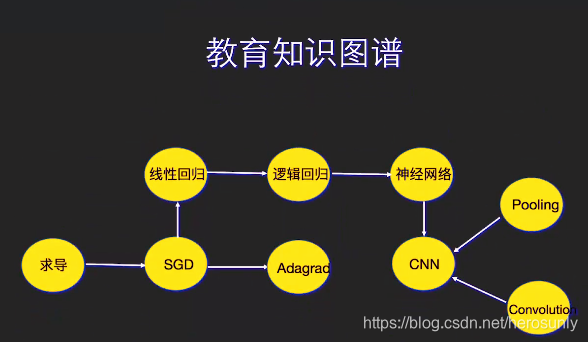
- 教育知识图谱:用知识图谱刻画知识点之间的关系:如下图。线性回归的后续知识是逻辑回归。这种知识图谱结合一些算法来判断学习技能的学习情况。
其他领域:搜索、聊天机器人、法律、医疗。知识图谱还处在比较初级的阶段,还有许多领域需要我们去挖掘探索。
4. 知识图谱架构图
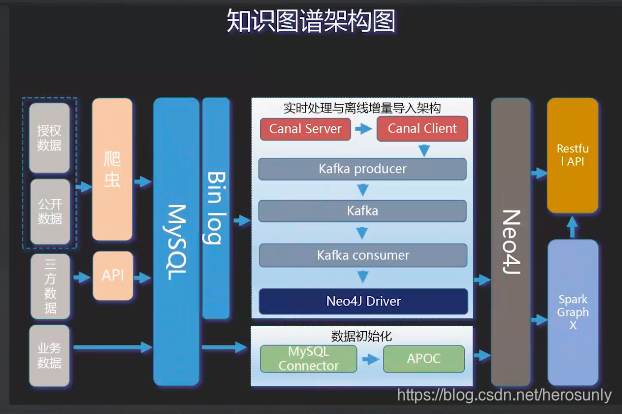
数据源:授权数据(用户允许我们去抓取的数据)、公开数据(如网上披露的黑名单数据)、第三方数据(别人提供的一些数据,通过API进行调用)、业务数据(用户填写到业务系统的数据,如一些个人信息)。
MySQL Binlog,它是MySQL自带的一种机制,MySQL的数据每次进行更新时,它就会把数据写入到Binlog中。也就是说Binlog是实时处理与离线增量导入架构数据的提供。
实时处理与离线增量导入架构:Canal server (中间件)-> Canal Client -> Kafka Producer->Kafka(消息队列)->Kafka Consumer->Neo4j Driver,最终写到Neo4j中。Neo4j中最开始并没有数据,所以需要数据初始化,也就是需要把业务数据写入到Neo4j中(MySQL Connector ->APOC)。
Resutful API向外提供服务(规则+Spark GraphX的算法)给一些业务系统。然后还会把数据写入到Spark GraphX中(在上面做一些算法相关的工作)。
算法设计的工作主要体现在几个方面,一个是把MySQL中的非结构化数据进行NLP处理,比如信息抽取、消歧分析等。
设计Neo4j,比如哪些是实体、哪些是关系。风控规则的设计、规则库的实现、简单的关系推理(大规模复杂网络实现分布式的社区挖掘)、标签传播(Spark GraphX中实现)等等。
