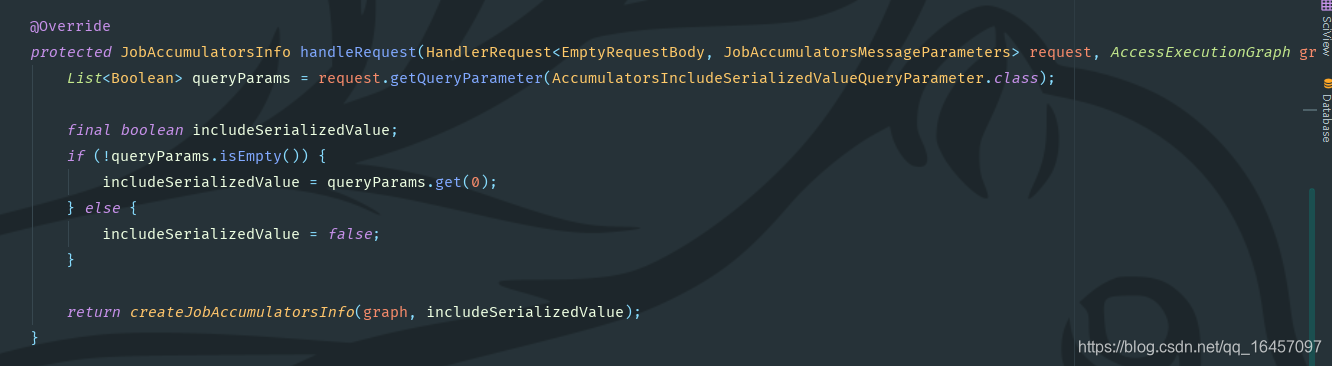
我们再探索累加器监控如何获取,跟着截图一探到底吧:
1.
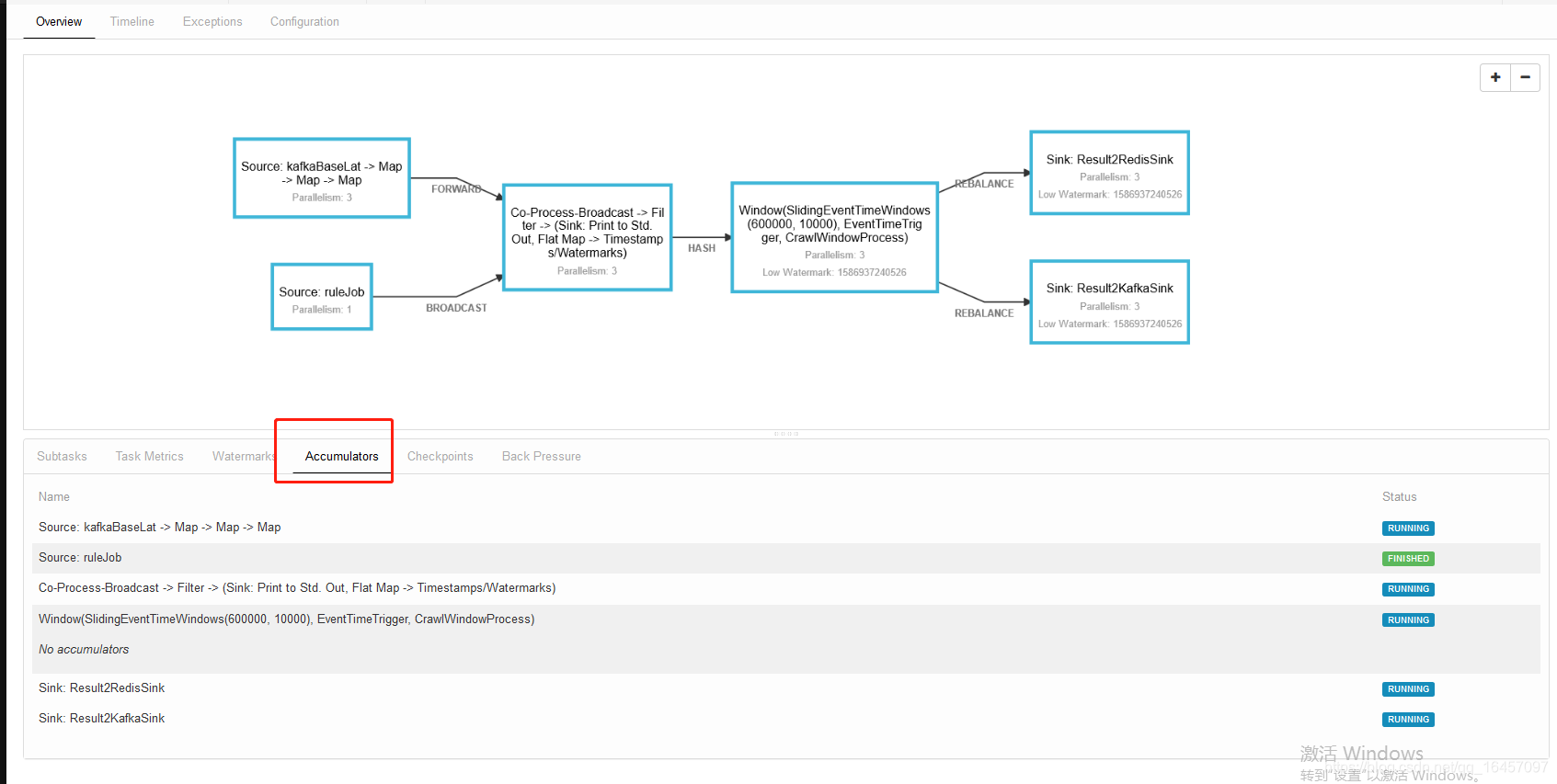 2.然后我们找到node.js渲染模块
2.然后我们找到node.js渲染模块
index.js 文件
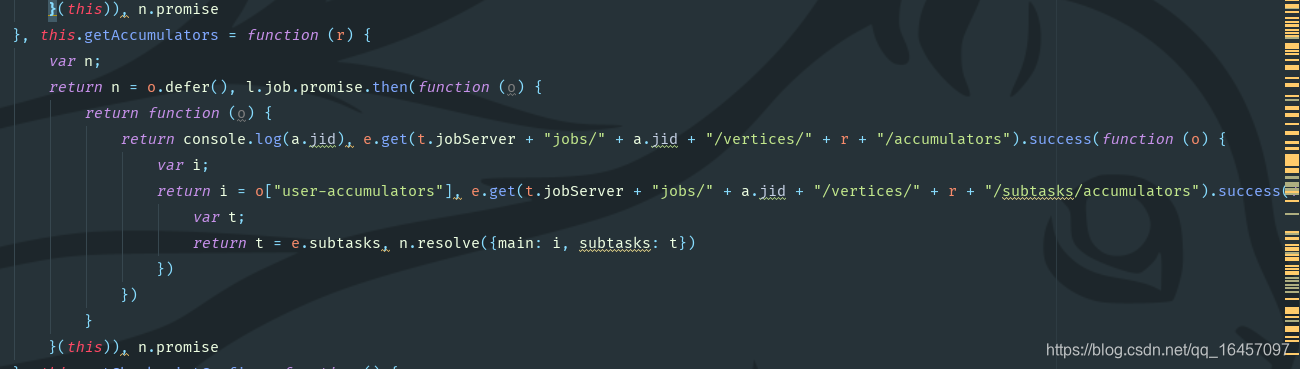 找到这里就知道flinkweb前端做数据处理写的好复杂样子,是那些开发者故意写这么复杂让我们看不懂吗?
找到这里就知道flinkweb前端做数据处理写的好复杂样子,是那些开发者故意写这么复杂让我们看不懂吗?
3.根据类似ajax请求知道请求了job的控制器获取信息的。来我们看下后端模块如何坑的:
JobAccumulatorsInfo.java
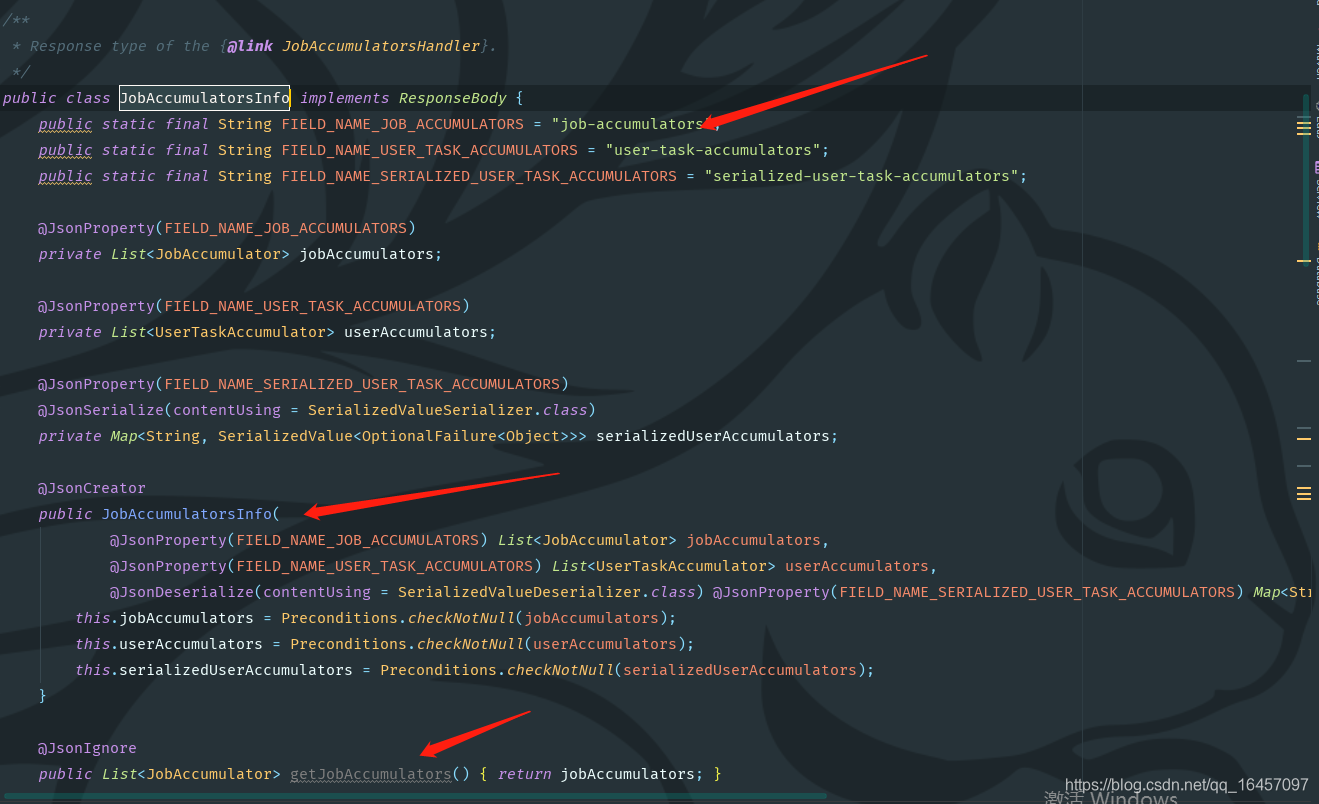 4.我们搞懂这个类外界如何调用的呢,于是我们找啊找找到JobAccumulatorsHandler.java类
4.我们搞懂这个类外界如何调用的呢,于是我们找啊找找到JobAccumulatorsHandler.java类
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.runtime.rest.handler.job;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.runtime.accumulators.StringifiedAccumulatorResult;
import org.apache.flink.runtime.executiongraph.AccessExecutionGraph;
import org.apache.flink.runtime.rest.handler.HandlerRequest;
import org.apache.flink.runtime.rest.handler.RestHandlerException;
import org.apache.flink.runtime.rest.handler.legacy.ExecutionGraphCache;
import org.apache.flink.runtime.rest.messages.AccumulatorsIncludeSerializedValueQueryParameter;
import org.apache.flink.runtime.rest.messages.EmptyRequestBody;
import org.apache.flink.runtime.rest.messages.JobAccumulatorsInfo;
import org.apache.flink.runtime.rest.messages.JobAccumulatorsMessageParameters;
import org.apache.flink.runtime.rest.messages.JobIDPathParameter;
import org.apache.flink.runtime.rest.messages.MessageHeaders;
import org.apache.flink.runtime.rest.messages.ResponseBody;
import org.apache.flink.runtime.webmonitor.RestfulGateway;
import org.apache.flink.runtime.webmonitor.history.ArchivedJson;
import org.apache.flink.runtime.webmonitor.history.JsonArchivist;
import org.apache.flink.runtime.webmonitor.retriever.GatewayRetriever;
import org.apache.flink.util.OptionalFailure;
import org.apache.flink.util.SerializedValue;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.Executor;
/**
* Request handler that returns the aggregated accumulators of a job.
*/
public class JobAccumulatorsHandler extends AbstractExecutionGraphHandler<JobAccumulatorsInfo, JobAccumulatorsMessageParameters> implements JsonArchivist {
public JobAccumulatorsHandler(
CompletableFuture<String> localRestAddress,
GatewayRetriever<? extends RestfulGateway> leaderRetriever,
Time timeout,
Map<String, String> responseHeaders,
MessageHeaders<EmptyRequestBody, JobAccumulatorsInfo, JobAccumulatorsMessageParameters> messageHeaders,
ExecutionGraphCache executionGraphCache,
Executor executor) {
super(
localRestAddress,
leaderRetriever,
timeout,
responseHeaders,
messageHeaders,
executionGraphCache,
executor);
}
@Override
protected JobAccumulatorsInfo handleRequest(HandlerRequest<EmptyRequestBody, JobAccumulatorsMessageParameters> request, AccessExecutionGraph graph) throws RestHandlerException {
List<Boolean> queryParams = request.getQueryParameter(AccumulatorsIncludeSerializedValueQueryParameter.class);
final boolean includeSerializedValue;
if (!queryParams.isEmpty()) {
includeSerializedValue = queryParams.get(0);
} else {
includeSerializedValue = false;
}
return createJobAccumulatorsInfo(graph, includeSerializedValue);
}
@Override
public Collection<ArchivedJson> archiveJsonWithPath(AccessExecutionGraph graph) throws IOException {
ResponseBody json = createJobAccumulatorsInfo(graph, true);
String path = getMessageHeaders().getTargetRestEndpointURL()
.replace(':' + JobIDPathParameter.KEY, graph.getJobID().toString());
return Collections.singleton(new ArchivedJson(path, json));
}
private static JobAccumulatorsInfo createJobAccumulatorsInfo(AccessExecutionGraph graph, boolean includeSerializedValue) {
StringifiedAccumulatorResult[] stringifiedAccs = graph.getAccumulatorResultsStringified();
List<JobAccumulatorsInfo.UserTaskAccumulator> userTaskAccumulators = new ArrayList<>(stringifiedAccs.length);
for (StringifiedAccumulatorResult acc : stringifiedAccs) {
userTaskAccumulators.add(
new JobAccumulatorsInfo.UserTaskAccumulator(
acc.getName(),
acc.getType(),
acc.getValue()));
}
JobAccumulatorsInfo accumulatorsInfo;
if (includeSerializedValue) {
Map<String, SerializedValue<OptionalFailure<Object>>> serializedUserTaskAccumulators = graph.getAccumulatorsSerialized();
accumulatorsInfo = new JobAccumulatorsInfo(Collections.emptyList(), userTaskAccumulators, serializedUserTaskAccumulators);
} else {
accumulatorsInfo = new JobAccumulatorsInfo(Collections.emptyList(), userTaskAccumulators, Collections.emptyMap());
}
return accumulatorsInfo;
}
}
5.这里就明白后端和前端写的真漂亮,老复杂了,新手看web源码时候要注意前端路由的坑。