今天是团队冲刺开发的第一天:
我给我们的团队里的每个人分配了现阶段的任务,我自己领取的任务是:
①爬取铁道大学官网的新闻
②将新闻准确的展示在“铁大新闻”板块上,并且可以点击后观看整篇新闻。
今天利用爬虫去解析铁道大学新闻官网:http://xcb.stdu.edu.cn/2009-05-05-02-26-33.html
分析后发现其标题都是在tr,class="sectiontableentry1"和class=“sectiontableentry2”的里面,因此我就将这两种全部获取
获取后遍历存储他们的href(单个新闻的网址)
通过对单个网址进行分析,打算存入数据库里的信息有:标题,日期,点击次数,正文,图片链接
对于标题,日期,点击次数比较简单
难点在于:正文的爬取和图片链接
①爬取正文时:正文都在div.article-content下的p标签里,因此我们获取所有的p标签的集合
一开始我以为就是在p标签下的span里的是正文,爬取了10个后发现漏了一点东西,原来b标签里的也是正文里的内容
由于整篇文章是有p标签分割的,一个p标签代表这一段,因此我将爬取的所有p标签遍历,之后通过p的contents来访问他的子节点,根据子节点的name属性来判断是“span”还是“p”,爬取完一段后存储到正文集合里。
r=requests.get(url,headers=headers) content=r.content.decode('utf-8') soup = BeautifulSoup(content, 'html.parser') trs=soup.find_all('tr',class_='sectiontableentry1') trs+=soup.find_all('tr',class_='sectiontableentry2') for i in range(len(trs)): strs='http://xcb.stdu.edu.cn/' link=strs+trs[i].a['href'] r = requests.get(link, headers=headers) content = r.content.decode('utf-8') soup = BeautifulSoup(content, 'html.parser') title=soup.find('h2',class_='contentheading').text.strip() title=title.replace(' ', '') date=soup.find('span',class_='createdate').text.strip()[5:] click=soup.find('span',class_='hits').text.strip()[5:-1] #print(title,date,click) #用来截取文章内容 doc=[] listp=soup.select('div.article-content > p') for j in range(len(listp)): #print(listp[j]) pp='' for k in range(len(listp[j].contents)): if(listp[j].contents[k].name=='span'): pp+=listp[j].contents[k].text elif(listp[j].contents[k].name=='b'): pp+=listp[j].contents[k].span.text doc.append(pp) doc='\n'.join(doc) #print(doc)
②爬取图片链接:
一开始也是以为只是在span里的input标签里,之后爬取10条数据后比较原文发现少了几张图片,于是回头在取分析少的图片,发现原来有的图片在img标签里
然后再爬取image里的图片链接,之后将两个爬取的链接合并,图片链接之间用空格分割
单个网页爬取完成后,分析我要是爬取10页内容,发现他们之间的规律,每翻一页后面就会发生变化:
第一页:http://xcb.stdu.edu.cn/2009-05-05-02-26-33.html
第二页:http://xcb.stdu.edu.cn/2009-05-05-02-26-33.html?start=10
第三页:http://xcb.stdu.edu.cn/2009-05-05-02-26-33.html?start=20
发现start里的数字都是10个10的加,因此我们就可以翻页爬取,然后存入数据库
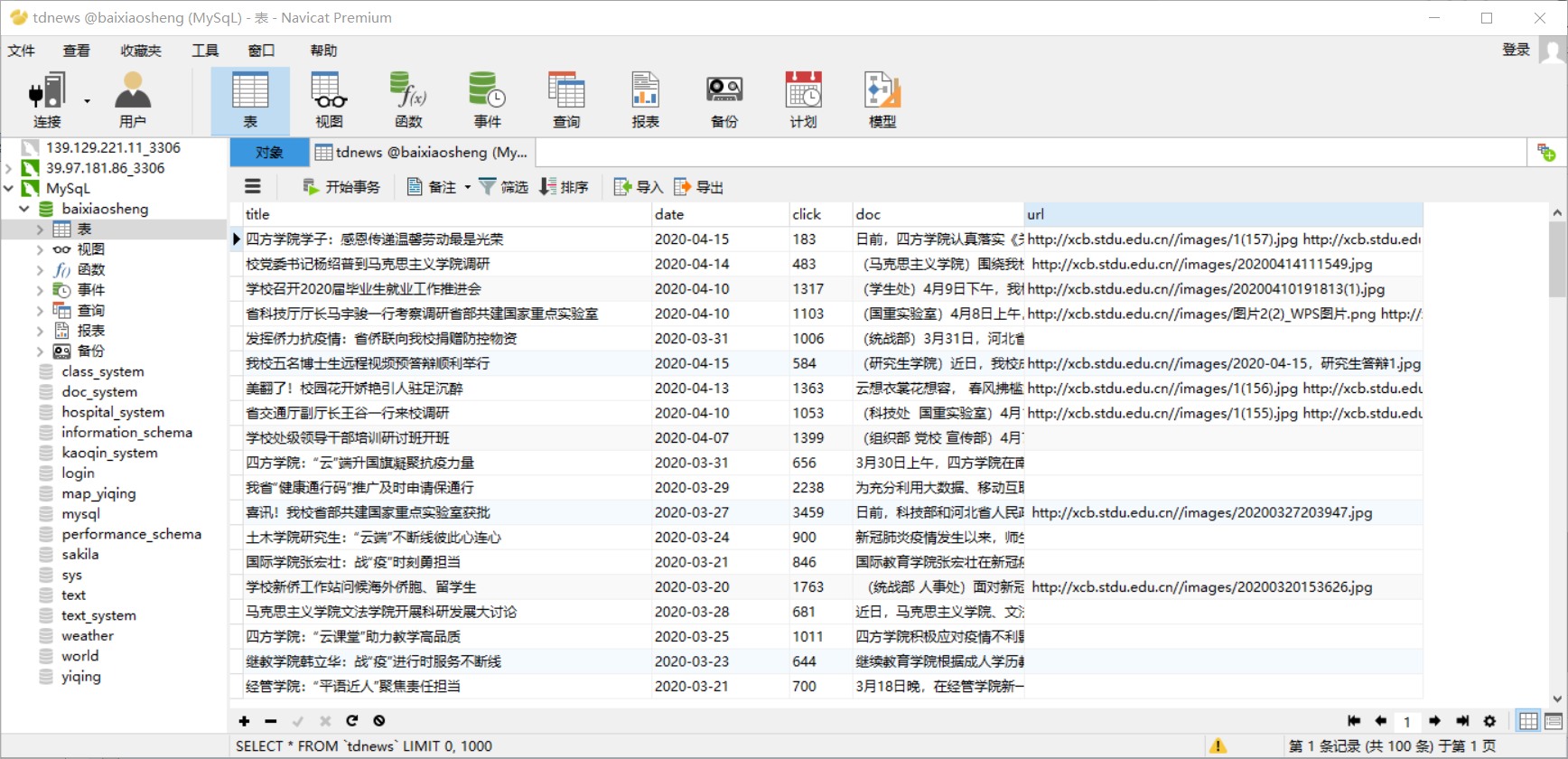
数据库截图:
python源码:


import requests from bs4 import BeautifulSoup import json import pymysql import time headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息 newlist=[] for page in range(10): number=10*page url='http://xcb.stdu.edu.cn/2009-05-05-02-26-33.html?start='+str(number) f=page+1 print('这是第'+str(f)+'页') r=requests.get(url,headers=headers) content=r.content.decode('utf-8') soup = BeautifulSoup(content, 'html.parser') trs=soup.find_all('tr',class_='sectiontableentry1') trs+=soup.find_all('tr',class_='sectiontableentry2') for i in range(len(trs)): strs='http://xcb.stdu.edu.cn/' link=strs+trs[i].a['href'] r = requests.get(link, headers=headers) content = r.content.decode('utf-8') soup = BeautifulSoup(content, 'html.parser') title=soup.find('h2',class_='contentheading').text.strip() title=title.replace(' ', '') date=soup.find('span',class_='createdate').text.strip()[5:] click=soup.find('span',class_='hits').text.strip()[5:-1] #print(title,date,click) #用来截取文章内容 doc=[] listp=soup.select('div.article-content > p') for j in range(len(listp)): #print(listp[j]) pp='' for k in range(len(listp[j].contents)): if(listp[j].contents[k].name=='span'): pp+=listp[j].contents[k].text elif(listp[j].contents[k].name=='b'): pp+=listp[j].contents[k].span.text doc.append(pp) doc='\n'.join(doc) #print(doc) #用来截取input里的图片 inputs=soup.find_all('input') imgs='' for k in range(len(inputs)): src='http://xcb.stdu.edu.cn/' img=src+inputs[k]['src'] if(k!=0): imgs+=' '+img else: imgs+=img #用来截取img里的图片 newimgs=soup.find_all('img') newimg='' for p in range(len(newimgs)): src = 'http://xcb.stdu.edu.cn/' imk=src+newimgs[p]['src'] if (p != 0): newimg += ' ' + imk else: newimg += imk #获取的总图片 url=imgs+' '+newimg #print(url) newvalue=(title,date,click,doc,url) newlist.append(newvalue) #数据库存储的实现 tupnewlist=tuple(newlist) print(tupnewlist) db = pymysql.connect("localhost", "root", "fengge666", "baixiaosheng", charset='utf8') cursor = db.cursor() sql_news = "INSERT INTO tdnews values (%s,%s,%s,%s,%s)" sql_clean_news = "TRUNCATE TABLE tdnews" try: cursor.execute(sql_clean_news) db.commit() except: print('执行失败,进入回调1') db.rollback() try: cursor.executemany(sql_news,tupnewlist) db.commit() except: print('执行失败,进入回调3') db.rollback() db.close()