python基础实验一
任务一:
.从键盘输入一组数据,编写程序,计算这组数据的平均值、标准差和中位数。输出结果保
留一位小数。
输入样例 1
99 98 97 96 95
输出样例 1
avg:97.0 variance:1.6 median:97.0
输入样例 2
99 98 97 96 95 94
输出样例 2
avg:96.5 variance:1.9 median:96.5
"""
# @Time : 2020/4/9
# @Author : JMChen
"""
import numpy as np
list1 = []
list2 = []
list1 = str(input()).split(' ')
for i in list1:
list2.append(int(i))
a = np.array(list2)
print(a)
# avg = sum(list2)/(len(list2))
print('avg:{0:.1f} variance:{1:.1f} median:{2:.1f}'.format(np.average(a), np.std(a), np.median(a)))
任务二:
编程要求
进度条是计算机处理任务或执行软件中常用的增强用户体验的重要手段,它能够实时显示任
务或软件的执行进度。
最简单地,可以利用 print()函数实现简单的非刷新文本进度条。基本思想是按照任务执行百
分比将整个任务划分为 100 个单位,每执行 N%输出一次进度条。每一行输出包含进度百分
比,代表已完成的部分()和未完成的部分(…)的两种字符,以及一个跟随完成度前进
的小箭头,风格如下:
%10 [****->…]
要求从键盘输入进度条的进度,采用 for 循环和 print()函数构成程序的主体部分,输出百
分比最高(100%)为 3 位数据,为了使输出显得整齐,可以使用{:3.0f}格式化百分比部分。
输入样例 1
10
输出样例 1
% 0[->…]
% 10[->…]
% 20[->…]
% 30[->…]
% 40[->…]
% 50[->…]
% 60[->…]
% 70[->…]
% 80[->…]
% 90[->…]
%100[************->]
进程已结束,退出代码 0
"""
# @Time : 2020/4/9
# @Author : JMChen
"""
# 非刷新的文本进度条
import time
x = eval(input())
for i in range(x + 1):
a = "**" * i
b = ".." * (x - i)
c = i / x * 100
print("%{:3.0f}[{}->{}]".format(c, a, b))
任务三:
编程要求
统计英文词频,从文件 Text_word_frequency_statistics.txt 中读取一篇文章,输出文章中最
常出现的 10 个单词及出现次数,对于出现次数相同的单词,再按照键值的字典顺序进行排
序,需要排除 the、and、of、a、i、in、you、my、he、his,输出格式为“{0:<10}{1:>5}”。
提示:
第一步:分解并提取英文文章的单词。同一个单词会存在大小写不同形式,但计数却不能
区分大小写。可以将所有字母转换为小写,排除原文大小写差异对词频统计的干扰。英文
单词的分隔可以是空格、标点符号或者特殊符号。为统一分隔方式,可以将各种特殊字符
和标点符号替换成空格,再提取单词。
第二步:对各个单词进行计数。
第三部:对单词的统计值从高到低进行排序,如果统计值相同,按照键值进行升序排列。
文件 Text_word_frequency_statistics.txt :
Salty Coffee
He met her at a party. She was outstanding; many guys were after her, but nobody paid any attention to him. After the party, he invited her for coffee. She was surprised. So as not to appear rude, she went along.
As they sat in a nice coffee shop, he was too nervous to say anything and she felt uncomfortable. Suddenly, he asked the waiter, “Could you please give me some salt? I’d like to put it in my coffee.”
They stared at him. He turned red, but when the salt came, he put it in his coffee and drank. Curious, she asked, “Why put salt in the coffee?” He explained, “When I was a little boy, I lived near the sea. I liked playing on the seaside … I could feel its taste salty, like salty coffee. Now every time I drink it, I think of my childhood and my hometown. I miss it and my parents, who are still there.”
She was deeply touched. A man who can admit that he’s homesick must love his home and care about his family. He must be responsible.
She talked too, about her faraway hometown, her childhood, her family. That was the start to their love story.
They continued to date. She found that he met all her requirements. He was tolerant, kind, warm and careful. And to think she would have missed the catch if not for the salty coffee!
So they married and lived happily together. And every time she made coffee for him, she put in some salt, the way he liked it.
After 40 years, he passed away and left her a letter which said:
My dearest, please forgive my life-long lie. Remember the first time we dated? I was so nervous I asked for salt instead of sugar.
It was hard for me to ask for a change, so I just went ahead. I never thought that we would hit it off. Many times, I tried to tell you the truth, but I was afraid that it would ruin everything.
Sweetheart, I don’t exactly like salty coffee. But as it mattered so much to you, I’ve learnt to enjoy it. Having you with me was my greatest happiness. If I could live a second time, I hope we can be together again, even if it means that I have to drink salty coffee for the rest of my life.
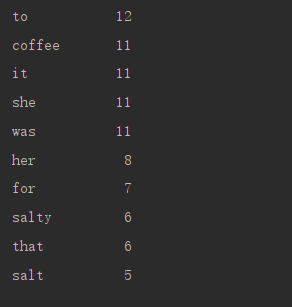
输出样例 1
to 12
coffee 11
it 11
she 11
was 11
her 8
for 7
salty 6
that 6
salt 5
"""
# @Time : 2020/4/9
# @Author : JMChen
"""
with open('Text_word_frequency_statistics.txt', 'r')as f:
f = f.read().lower()
for ch in '!,".:?;':
f = f.replace(ch, '')
l = f.split()
l.sort()
countDict = {}
for word in l:
if word in ['the', 'and', 'of', 'a', 'i', 'in', 'you', 'my', 'he', 'his']:
continue
else:
countDict[word] = countDict.get(word, 0) + 1
cList = list(countDict.items())
cList.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
w, c = cList[i]
print('{0:<10}{1:>5}'.format(w, c))
注意:如果统计值相同,按照键值进行升序排列。
