采茶青山之上,钓鱼渭水江边,无忧无虑在眼前。
00 前言
在学习 python ,网上找的一个案例自己再次复现,加上自己的理解和记录过程中遇到的一些小问题,当巩固基础。==>原案例出处
01 实验对象
https://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-1.html
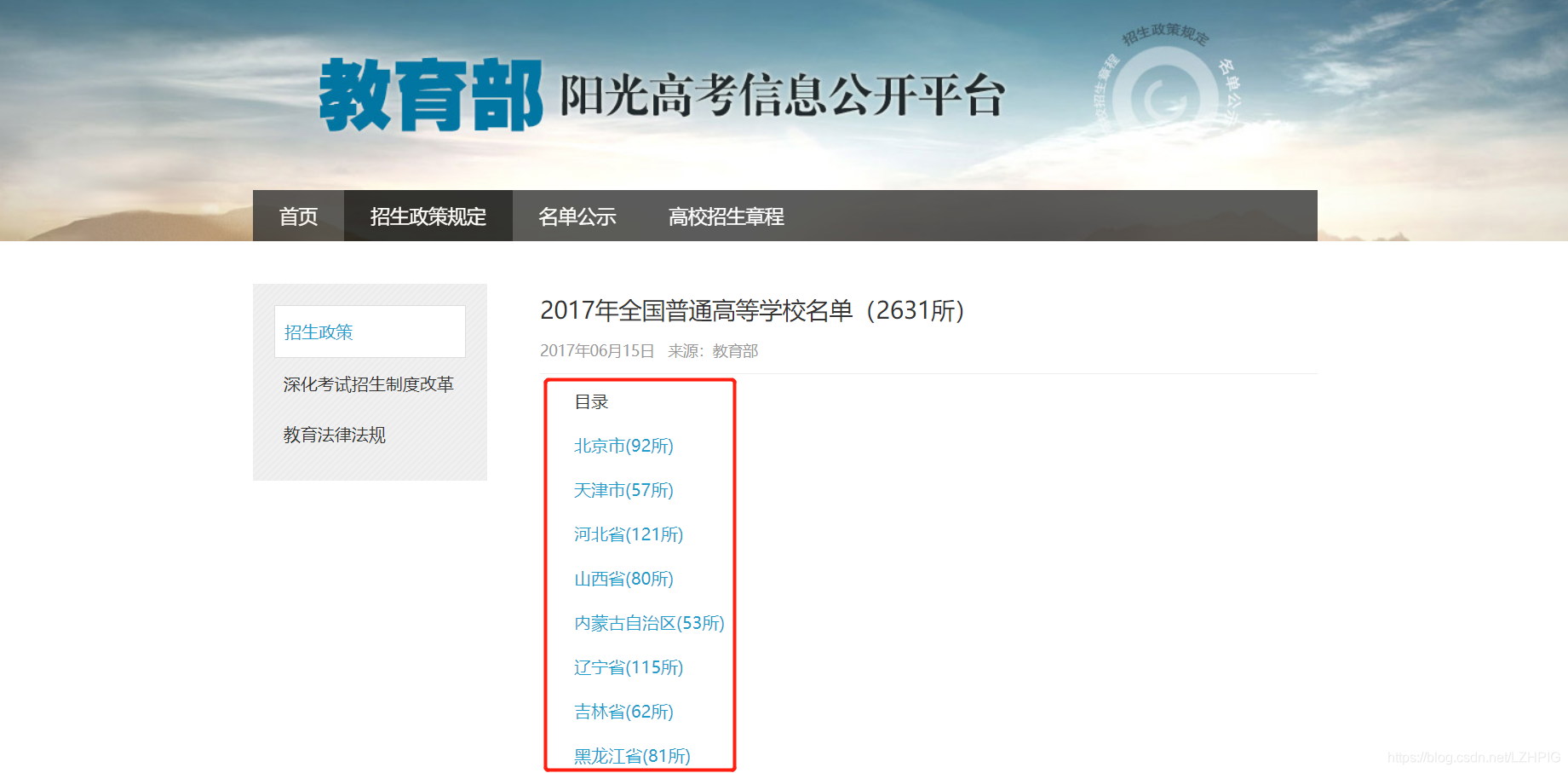
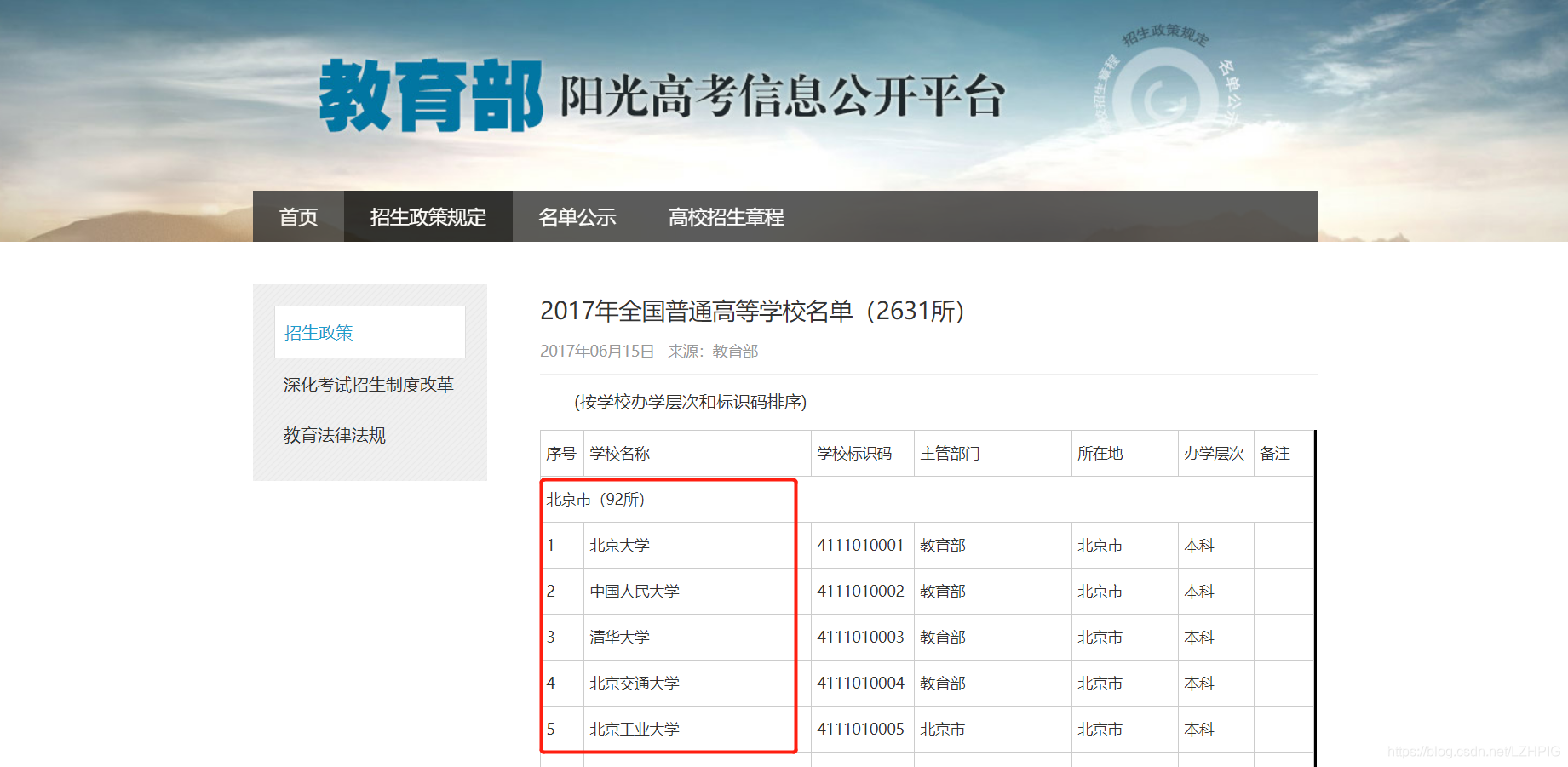
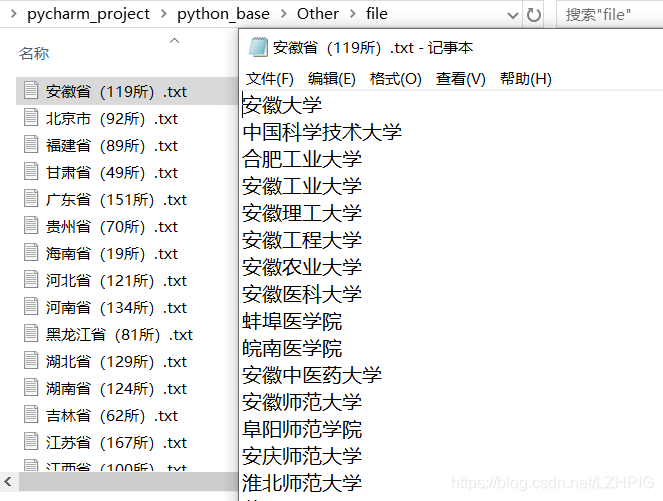
如上,目录下有全国所有的城市,点击每一个城市的链接进去都会有所属城市的所有大学的信息,本次案例就是要收集所有城市下所对应大学的名字并导出文件,文件以对应的城市命名。最后的成果如下:
02 实验过程
1 审查元素
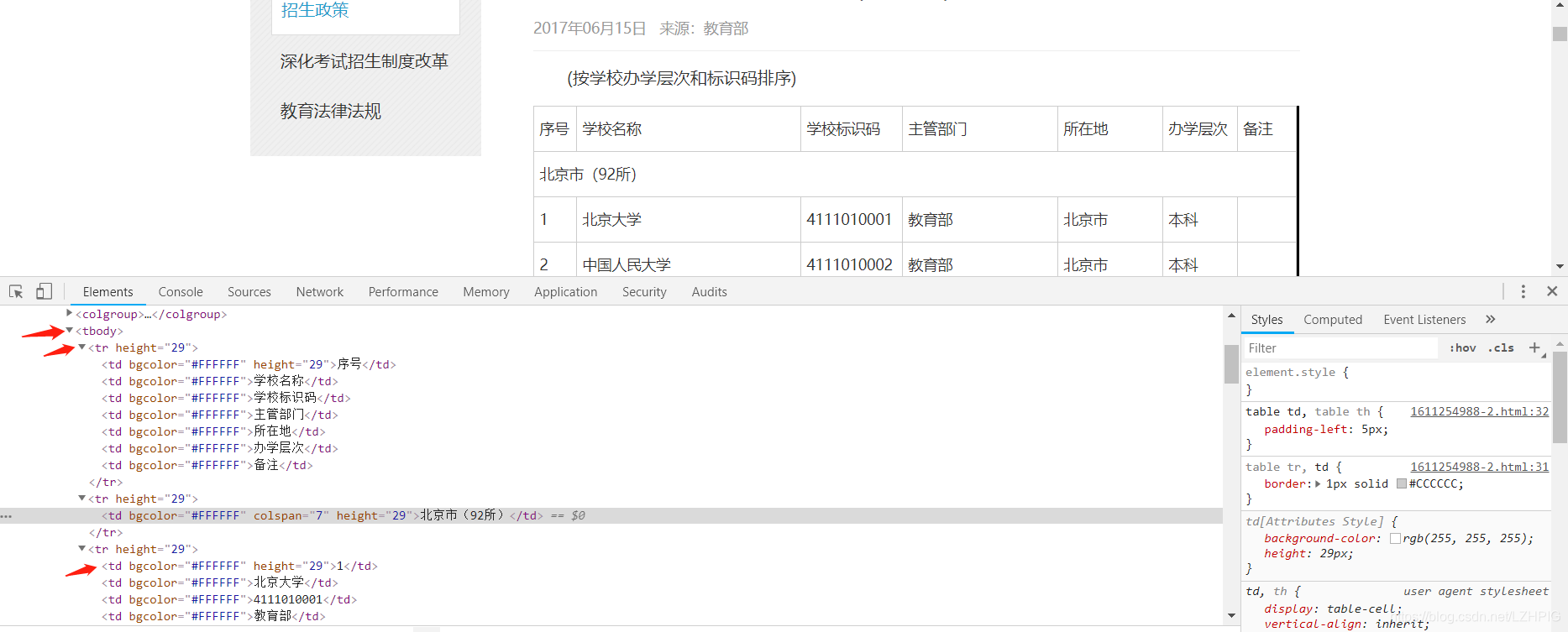
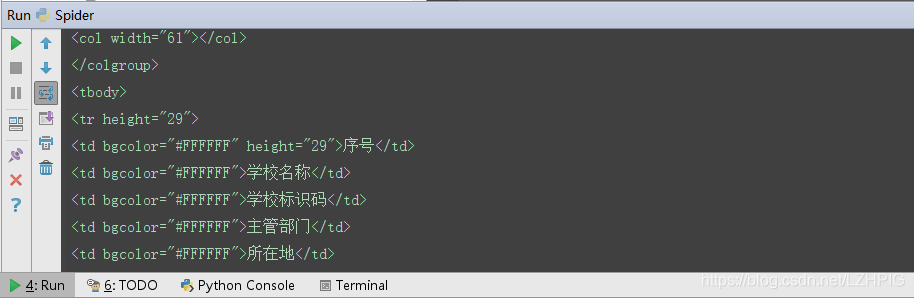
f12 打开开发者工具审查源码发现整个表格信息在 <tbody> 标签下,每一行信息在 <tr height="29"> 标签下,每个单元格信息在 <td> 标签下,而我们所要获得的学校的名字就在每个 <tr> 下的第二个 <td> 中
2 获取网页源码
① python 源码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import lxml
from bs4 import BeautifulSoup
import io,sys
# from bs4 import BeautifulSoup as bf # 修改 BeautifulSoup 模块的名字为 bf
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
def School():
url = "https://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html"
r = requests.get(url=url)
soup = BeautifulSoup(r.content,"lxml") #利用beautifulsoup解析,将返回内容赋值给soup
print(soup)
if __name__ == '__main__':
School()
② 结果
以上的源码中有一句语句设置了 python 默认的编码为 gb18030
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
值得注意的是,如果不使用上面的语句设置 python 的默认编码为的话会报错,如下:
UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 4400: illegal multibyte sequence
对于此(类)问题:
(1)出现 UnicodeEncodeError –> 说明是 Unicode 编码时候的问题;
(2) ‘gbk’ codec can’t encode character –> 说明是将 Unicode 字符编码为 GBK 时候出现的问题;此时,往往最大的可能就是,本身Unicode类型的字符中,包含了一些无法转换为 GBK 编码的一些字符。
(3) print()函数自身有限制,不能完全打印所有的unicode字符,python的默认编码不是 ‘utf-8’,改一下 python 的默认编码成 ‘gb18030’
出错问题参考一
出错问题参考二
3 提取单页关键信息
在能够成功获取网页源码的基础上,进一步缩小获取内容的范围,根据以上分析的 HTML 标签的特性,通过使用 find_all() 搜索 <tr height="29"> 标签从而来定位表格的每一行,通过搜索 <td> 标签来定位每一个单元格。
① python 源码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import lxml
import io,sys
from bs4 import BeautifulSoup
# from bs4 import BeautifulSoup as bs
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
def school():
url = "http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html"
r = requests.get(url)
soup = BeautifulSoup(r.content,"lxml")
content = soup.find_all(name = "tr",attrs= {"height":"29"})
for content1 in content:
soup_content = BeautifulSoup(str(content1),"lxml")
soup_content1 = soup_content.find_all(name="td")
print(soup_content1[1])
if __name__ == '__main__':
school()
② 结果
输出的结果显示出现错误:列表的索引超出范围,但是还是有一个输出,也就是说,在循环过程中进行到第二个 <tr> 标签的时候出现了如下错误。
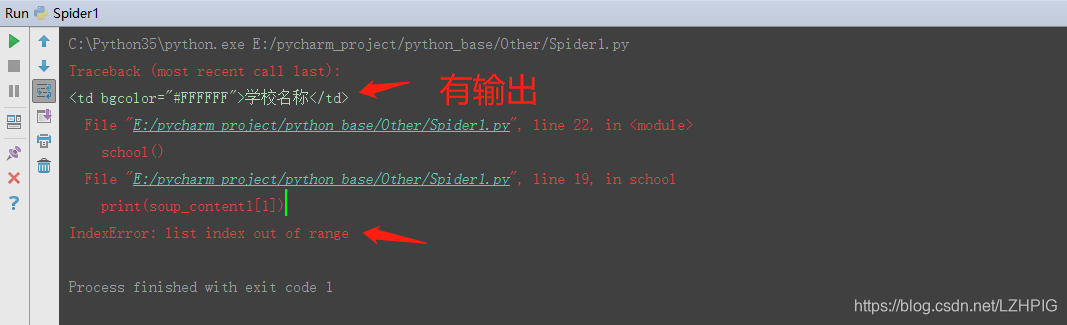
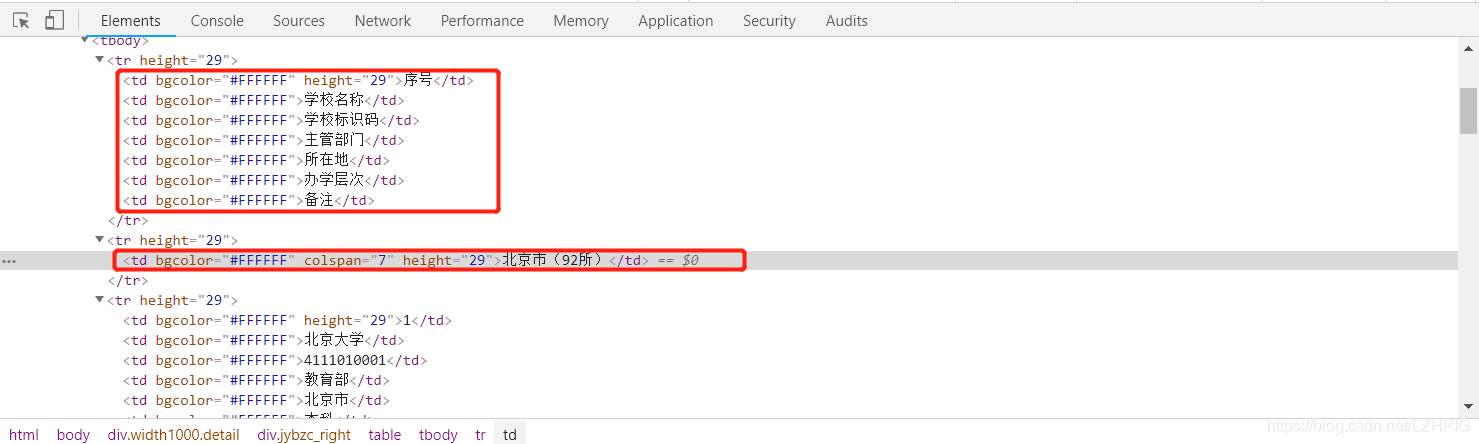
③ 审查元素
打开开发者工具审查元素之后发现,除了的第二个 <tr> 标签(第二行)之外,其他 <tr> 标签都有 7 个 <td>标签(7 个单元格),所以当 for 循环到第二个 <tr> 标签的时候出现错误。这里的解决方法可以使用 python 的异常处理,绕过错误继续运行。
④ python 源码修正
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import lxml
import io,sys
from bs4 import BeautifulSoup
# from bs4 import BeautifulSoup as bs
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
def school():
url = "http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html"
r = requests.get(url)
soup = BeautifulSoup(r.content,"lxml")
content = soup.find_all(name = "tr",attrs= {"height":"29"})
for content1 in content:
try:
soup_content = BeautifulSoup(str(content1),"lxml")
soup_content1 = soup_content.find_all(name="td")
print(soup_content1[1])
except IndexError:
pass
if __name__ == '__main__':
school()
⑤ 结果
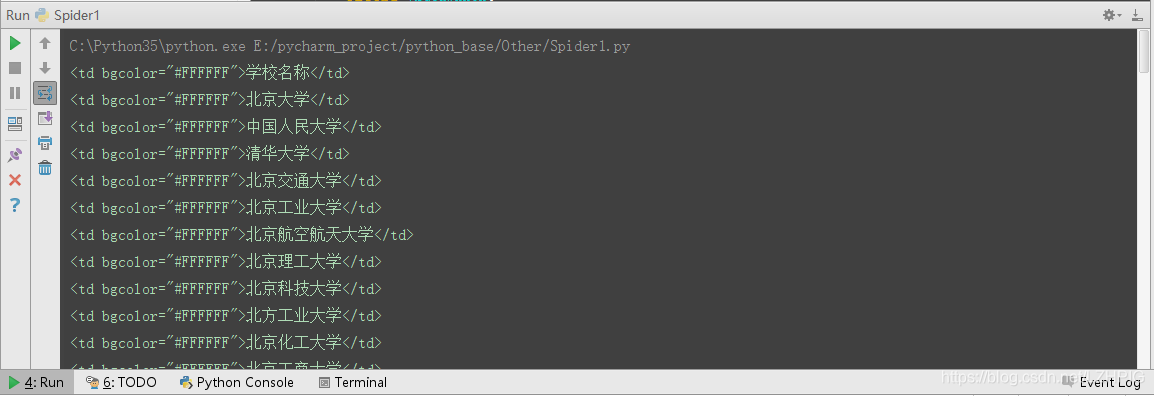
4 提取多页关键信息
以上是提取到一个城市的学校名,接下来需要提权所有城市的学校名信息。通过比较每个城市网页的链接发现,只是文件名最后的数字不同。所以可以使用 for 循环切换网页链接
https://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html
https://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-3.html
同时在网页的最下端也发现所需提取城市的数量范围是 2 - 32

① python 源码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import lxml
import io,sys
from bs4 import BeautifulSoup
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
def school():
for i in range(2,34,1):
url = "http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-%s.html"%(str(i))
r = requests.get(url)
soup = BeautifulSoup(r.content,"lxml")
content = soup.find_all(name="tr",attrs={"height":"29"})
for content1 in content:
try:
soup_content = BeautifulSoup(str(content1),"lxml")
soup_content1 = soup_content.find_all(name="td")
print(soup_content1[1].string)
except IndexError:
pass
if __name__ == '__main__':
school()
② 结果
结果就是将所有城市的所有大学都打印出来了
5 逐个存储关键信息
基于上面的基础,将获取的每一个城市的大学名存储在 txt 文件中,并以所属城市名命名,以 find_all 方法搜索 <tr colspan="7"> 标签定位到第二行的城市名
① python 源码
由于在遍历每个城市的时候又出现 列表索引超出范围 的错误,所以在 for 循环之后又使用了一次异常处理。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import lxml
import io,sys
from bs4 import BeautifulSoup
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
def school():
for i in range(2,34,1):
try:
url = "http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-%s.html"%(str(i))
r = requests.get(url)
soup = BeautifulSoup(r.content,"lxml")
filename = soup.find_all(name="td",attrs={"colspan":"7"})[0].string
file = open("file/%s.txt"%(filename),"w")
content = soup.find_all(name="tr",attrs={"height":"29"})
for content1 in content:
try:
soup_content = BeautifulSoup(str(content1),"lxml")
soup_content1 = soup_content.find_all(name="td")
file.write(soup_content1[1].string + "\n")
print(soup_content1[1].string)# 用 string 方法获取文字
except IndexError:
pass
except IndexError:
pass
if __name__ == '__main__':
school()
② 结果
猪头
2020.3.26
