4.1 residual diagnostics(残差诊断)
一个好的预测方法将产生以下属性的残差:
1. 残差不相关
如果残差之间存在相关性,则残差中会留有信息,这些信息应用于计算预测。
2. 残差均值为零
如果残差的平均值不是零,则预测有偏差。
任何不满足这些属性的预测方法都可以得到改进 (?如何改进使得残差符合这个规律)。 但是,这并不意味着不能改善满足这些属性的预测方法。 对于同一个数据集,可能有几种不同的预测方法,所有这些方法都满足这些属性。 为了查看一种方法是否正在使用所有可用信息,检查这些属性很重要,但这不是选择预测方法的好方法。
改进残差方法:
- 如果残差均值为m,然后只需添加m,所有的预测和偏见问题得到解决
- 相关性修复将在第10章讨论
除了这些基本属性之外,残差还具有以下两个属性是有用的(但不是必需的)。
3. 残差具有恒定的方差
4. 残差是正态分布的
这两个属性使预测间隔的计算更加容易。 但是,不能满足不满足这些特性的预测方法的必要性。 有时应用Box-Cox变换可能会有助于这些属性,但通常,您几乎无法做任何操作来确保残差具有恒定方差和正态分布。 取而代之的是,需要一种获得预测间隔的替代方法。
Ex:预测谷歌每日收盘价
对于股市价格和指数,最佳的预测方法通常是naive的方法。 也就是说,每个预测都等于上一个观测值,或者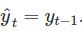 ;这样残差可以简单的等价于两个连续观测值得差
;这样残差可以简单的等价于两个连续观测值得差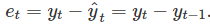
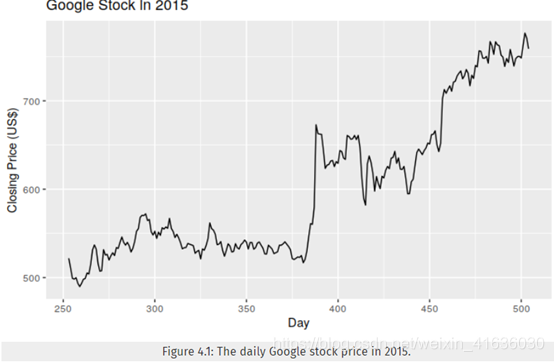

图4.2显示了使用朴素方法预测该系列所得的残差。 大的正残差是7月份价格意外上涨的结果。
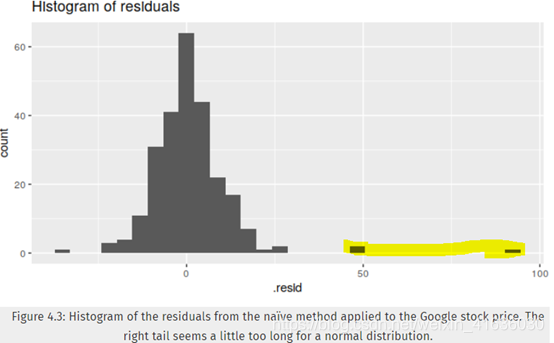
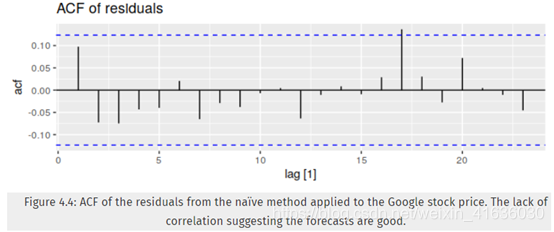
这些图表明,naïve方法所产生的预测可解释所有可用信息;图4.2显示残差平均值接近于0,且残差序列中没有显著相关性;另外,残差时间图(图4.2)还显示除了一个异常值,残差的变化在整个历史数据中保持几乎相同,故残差可以看做是恒定值。在直方图上也可读出上述结论,但是直方图表明残差可能是非正态分布的,即使忽略异常值,右尾似乎太长了。所以,使用naïve的方法预测可能会很好,但是假设正态分布而计算出的预测间隔可能不准确。
Portmanteau自相关检验
’除了查看ACF图外,还可通过考虑整个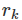 的一组值作为一个整体来做正式的自相关测试,而不是仅分开来考虑。
的一组值作为一个整体来做正式的自相关测试,而不是仅分开来考虑。
:lag为k的自相关系数
当我们查看ACF图确定每个尖峰是否在要求的限制内时,我们隐式的进行了多个假设检验,每个检验都有一定小的概率给出假阳性。在完成足够多测试后,很可能至少有一个假阳性,故我们可得出结论,残差具有一些剩余的自相关,而实际却没有。
为克服这个问题,我们测试下前h个自相关是否显著不同于期望的白噪声过程。一组自相关测试称为portmanteau测试。
Box-Pierce检验就是这样一种检验,它基于以下统计数据
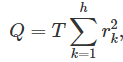
h表示它最大的lag,T表示总观测点个数。如果每个 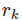 都接近于0,那么Q将会很小。如果一些
都接近于0,那么Q将会很小。如果一些 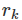 很大(正值或负值),那么Q将会很大。我们建议对于非季节性数据,h=10或者对于季节性数据,h=2m,m表示季节时期。但是由于当h很大时,该结果不好,所以如果h的值超过了T/5,那么我们就取h=T/5.
很大(正值或负值),那么Q将会很大。我们建议对于非季节性数据,h=10或者对于季节性数据,h=2m,m表示季节时期。但是由于当h很大时,该结果不好,所以如果h的值超过了T/5,那么我们就取h=T/5.
Ljung-Box检验:一个相关但更准确的测试

这里大的值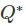 表示自相关不是来自于白噪声序列。
表示自相关不是来自于白噪声序列。
如何定义上面的大:如果自相关来自于白噪声序列,那么Q和 都有(h-K)自由度的卡方分布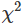 ,而K表示模型的参数个数。如果它们是从raw data里计算的(而不是从模型的残差),那么设定K=0.
,而K表示模型的参数个数。如果它们是从raw data里计算的(而不是从模型的残差),那么设定K=0.
对于Google股票价格示例,naive模型没有参数,因此ķ=0在这种情况下也是如此。
4.2 evaluating forecast accuracy
训练集和测试集
使用真实的预测评估预测准确性非常重要。 因此,残差的大小并不是真实预测误差可能有多大的可靠指示。 预测的准确性只能通过考虑模型在拟合模型时未使用的新数据上的表现如何来确定。
选择模型时,通常分为训练和测试两部分,训练数据用于估计预测方法的任何参数,测试数据用于评估其准确性。由于测试数据未用于确定预测,故可表明模型对新数据预测能力如何。

测试集通常约为总样本的20%,需要注意的是
训练数据拟合较好的模型不一定能很好预测
模型有足够的参数才能训练出好的模型
模型过拟合与无法识别数据中的系统模式一样糟糕
训练数据还可以被称为样本内数据;测试集还可被称为样本外数据。
预测误差:观测值与其预测值之间的差;这里的误差并不意味着错误,而是意味着观察中不可预测的部分,它可以被写为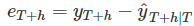
,它的训练集是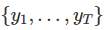 ,测试集是
,测试集是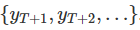
注意:预测误差在两个方面不同于残差
训练集上计算残差,而测试集上计算误差
残差是基于单步预测,而预测误差可能涉及多步预测
我们可通过汇总预测误差来测量预测准确性,换句话说,预测准确性是由衡量预测误差决定的。
比例误差(scale-dependent error)
预测误差与数据范围相同;基于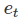 的准确度衡量是比例化的,这样它不能用来在不同系列之间比较。
的准确度衡量是比例化的,这样它不能用来在不同系列之间比较。
两种最常用的比例尺衡量是基于绝对误差或平方误差的:

(?什么是比例尺衡量误差,是将其放在同一比例上吗)
当比较单个时间序列或有相同单位的多个时间序列预测方法时,MAE更受欢迎,因为它易于理解和计算。?最小化MAE预测方法会导致中位数的预测,而最小化RMSE将导致对均值预测。
百分比误差(percentage errors)
百分比误差由下式决定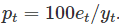
,它的优势是没有单位的,故经常被用于比较数据集之间的预测性能,最常用的度量为
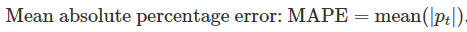
百分比误差三个缺陷:
在 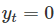 时,百分比误差会出现无限或者不确定的缺陷,或者在Yt接近于0时,百分比误差也会出现极值问题。
时,百分比误差会出现无限或者不确定的缺陷,或者在Yt接近于0时,百分比误差也会出现极值问题。
?(如何理解)百分比误差的另一个缺陷是它们假定测量单位有一个有意义的0点。比如,在华氏或者摄氏度下测量温度预测的准确性时,百分比误差没有意义,因为温度具有任意零点。
百分比误差对负误差的惩罚要大于对正误差的惩罚。这使得Armstrong提出**’对称MAPE’(sMAPE)**来进行修正
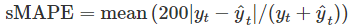
比例误差(scaled errors)
它可以作为在不同单位下使用百分比误差效果不好的替代方法,它可基于简单预测方法的训练MAE来缩放误差。
对于非季节时间序列,定义比例误差一种有效方法是使用Naïve预测

由于分子和分母都涉及原始数据的比例值,所以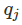 与数据的规模无关;如果一个缩放误差比平均naïve预测的预测效果要好,则它的缩放误差小于1;反之,如果一个缩放误差比平均naïve预测的预测效果要差,则它的缩放误差大于1.
与数据的规模无关;如果一个缩放误差比平均naïve预测的预测效果要好,则它的缩放误差小于1;反之,如果一个缩放误差比平均naïve预测的预测效果要差,则它的缩放误差大于1.
对于季节性时间序列,可使用季节性naïve的预测定义比例误差: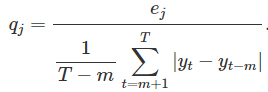
平均绝对比例误差:
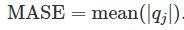
4.3 Time series cross-validation
时间序列交叉验证:此过程中,会有一组测试集,每个测试集会包含唯一的观测点;相应的训练集仅包含在形成测试集的观察之前发生的观察。故将来的观察结果都不能用于构建预测,由于不可能基于小的训练集获得可靠预测,所以最早的观察结果不被视为测试集。
下图蓝色代表训练集,红色代表测试集:
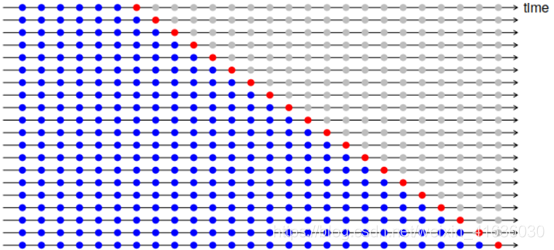
预测的准确性是通过对测试集进行平均计算得出的,此过程有时被称为‘滚动预测原点评估’,因为预测所基于的“原点”会及时向前滚动。
当使用时间序列预测,单步预测可能不如多步预测重要;故在此情况下,我们可修改基于滚动预测原点的交叉验证过程,以允许使用多步误差。
下图显示了我们生成4步预测对应的训练集和测试集
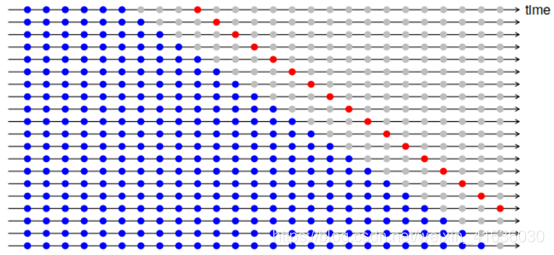
选择最佳预测模型的一个好方法是找到使用时间序列交叉验证计算出的最小RMSE的模型。
