一.主题式网络爬虫设计方案
1.主题式网络爬虫名称:关于携程景区信息
2.主题式网络爬虫爬取的内容:景区福利评级与热度
3.设计方案概述:
实现思路:爬取网站内容,之后分析提取需要的数据,进行数据清洗,之后数据可视化,并计算不同比率的相关系数
技术难点:因为用的是json分析,所以需要通过查找的方式获取数据
二、主题页面的结构特征分析
1.主题页面的结构与特征分析,通过解析发现数据都通过json传输 ,解析参数循环得数据
2.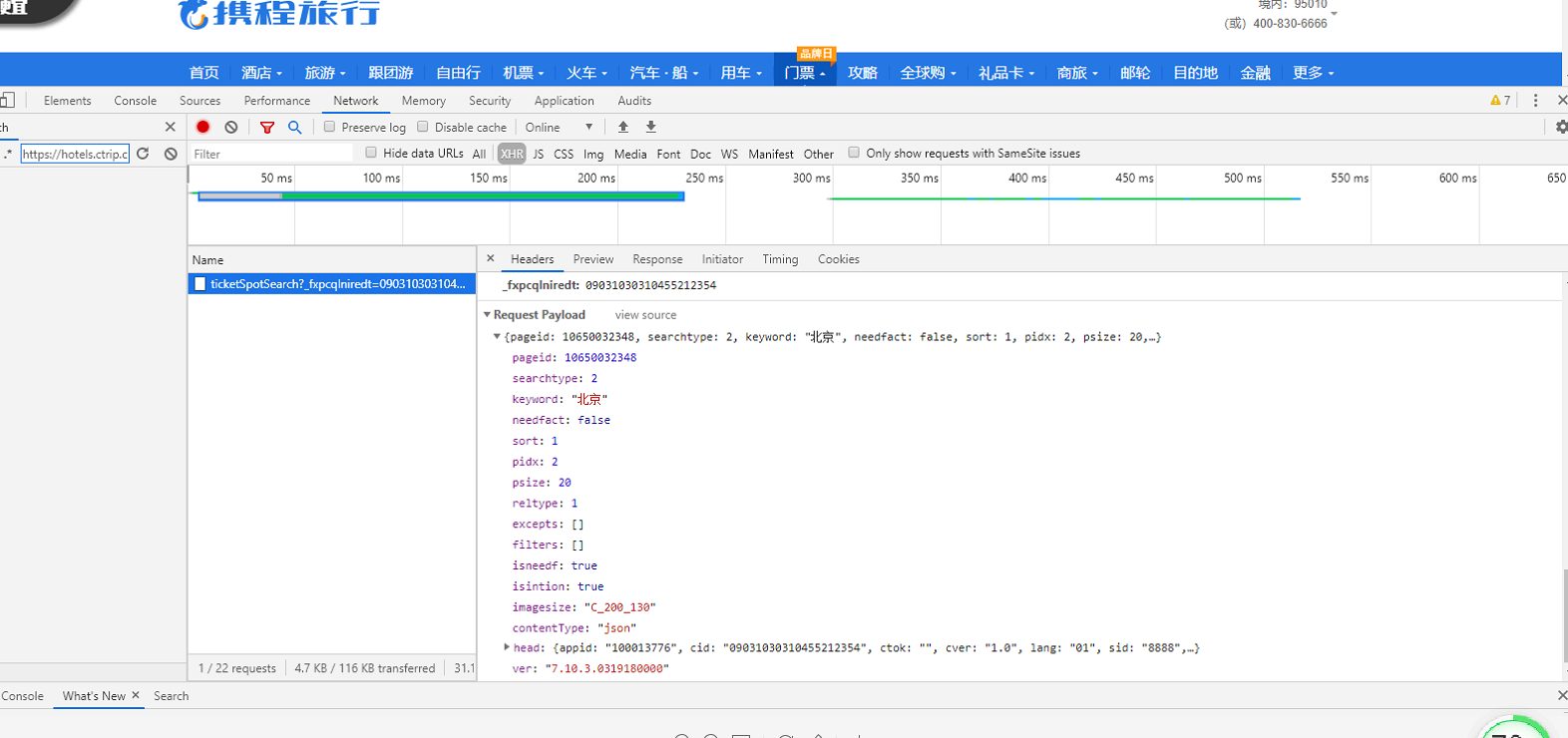
在57行找到基本参数




三、网络爬虫程序设计
1.数据爬取与采集
import json
import time
import pandas as pd
from lxml import etree
import requests
infos = [] # 用来存储所有信息的列表
# 定义目标链接
url = "https://sec-m.ctrip.com/restapi/soa2/12530/json/ticketSpotSearch"
# 定义User_Agent列表,下方headers中使用
ua = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]
# 定义请求头列表,防止携程识别出我们的爬虫程序
headers = {
"Host": "sec-m.ctrip.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://piao.ctrip.com/dest/u-%E5%A4%A9%E6%B4%A5/s-tickets/",
"Content-Type": "application/json",
"cookieorigin": "https://piao.ctrip.com",
"Origin": "https://piao.ctrip.com",
"Content-Length": "423",
"Connection": "keep-alive",
"Cookie": "_abtest_userid=6f592f35-e449-4bc0-b564-d00f956f84ff; _bfa=1.1582097534632.ml3vt.1.1585454134475.1585471635679.48.511.228032; Session=SmartLinkCode=U155952&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=&SmartLinkLanguage=zh; _RF1=116.132.81.181; _RSG=PTaQiACpsx2FxjposHE578; _RDG=2841b6791758af2d7c11b9d9aaab2910e8; _RGUID=2ef6ccc2-ac6a-4759-81c5-391db2cedecf; MKT_CKID=1582097537594.5es03.inf0; _jzqco=%7C%7C%7C%7C1585471664213%7C1.961816114.1582097537604.1585471638835.1585471664156.1585471638835.1585471664156.undefined.0.0.206.206; __zpspc=9.51.1585471638.1585471664.2%233%7Cbzclk.baidu.com%7C%7C%7C%7C%23; _ga=GA1.2.427107527.1582097538; HotelCityID=12split%E6%B5%8E%E5%8D%97splitNanjingsplit2020-3-18split2020-03-22split0; appFloatCnt=93; nfes_isSupportWebP=1; StartCity_Pkg=PkgStartCity=346; FlightIntl=Search=[%22HKG|%E9%A6%99%E6%B8%AF(HKG)|58|HKG|480%22%2C%22BJS|%E5%8C%97%E4%BA%AC(BJS)|1|BJS|480%22%2C%222020-03-02%22]; AHeadUserInfo=VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=1; UUID=04BDE45396F048A5BD505942DCF4AA0E; IsPersonalizedLogin=F; MKT_Pagesource=PC; Union=OUID=index&AllianceID=4897&SID=155952&SourceID=&createtime=1585471639&Expires=1586076438757; GUID=09031158111425303949; __utma=1.427107527.1582097538.1584616142.1584619463.2; __utmz=1.1584619463.2.2.utmcsr=ctrip.com|utmccn=(referral)|utmcmd=referral|utmcct=/; gad_city=b6a29287793c7ffa817a1ee3a6776529; MKT_CKID_LMT=1585454137863; _gid=GA1.2.198710281.1585454139; _bfs=1.4; _gat=1; _bfi=p1%3D10650032348%26p2%3D10650034475%26v1%3D511%26v2%3D510",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"TE": "Trailers",
}
# 此列表用来存储每一页的请求参数
das = []
for i in range(1,100):
# 循环便利将每一页的请求参数赋值到列表中
das.append({"pageid":10650032348,"searchtype":2,"keyword":"天津","sort":1,"pidx":int("{}".format(i)),"psize":20,"reltype":1,"excepts":[],"filters":[],"imagesize":"C_200_130","contentType":"json","head":{"appid":"100013776","cid":"09031158111425303949","ctok":"","cver":"1.0","lang":"01","sid":"8888","syscode":"09","auth":"","extension":[{"name":"protocal","value":"https"}]},"ver":"7.10.3.0319180000"})
# 循环便利取出对应的请求参数
for k,da in enumerate(das):
print(k+1) # 打印进度,声明第几次循环
time.sleep(10) # 控制程序峰值速度,防止携程检测
# requests模块发送post请求并携带headers与data,得到返回内容并解码
resp = requests.post(url, headers=headers, data=json.dumps(da)).content.decode()
# 将回返内容转化为json类型
js_info = json.loads(resp)
# 取出转化后的json类型中景点信息部分
c = js_info['data']['viewspots']
信息处理
# 循环遍历取出每一家景点对应详细数据 for i in c: # 判断该景区是否为A级景区,是则赋值,不是则用“无”来声明 xj = i['star'] if i['star'] else "无" # 定义临时集合 temp = set() # 取出评论数 pls = i['commentCount'] if i['commentCount'] else "无" # 循环取出每一条tag标签并添加到temp集合中,籍此实现数据清洗去重 for tg in i['taginfos']: temp.add(tg['tags'][0]['tname']) # 将结构化完毕的数据添加到infos列表中 infos.append({ '景点名称':i['name'], '星级':xj, '评分':i['cmtscore'], '推荐度':i['cmttag'], '简介':i['feature'], '标签':str(temp)[1:-1], '评论数':pls, 'id':i['id'] }) # 文件名 fileName = "景点基本信息.csv" # 将信息传入pandas库中的DataFram对象中,得到DataFram对象 data = pd.DataFrame(infos) # 写入csv文件,csv_headers列表定义所需字段 csv_headers = ['景点名称', '星级', '评分', '推荐度', '简介', '标签','评论数','id'] # 传入数据,规定编码utf_8_sig,规定写入模式W data.to_csv(fileName, header=csv_headers, index=False, mode='w', encoding='utf_8_sig')
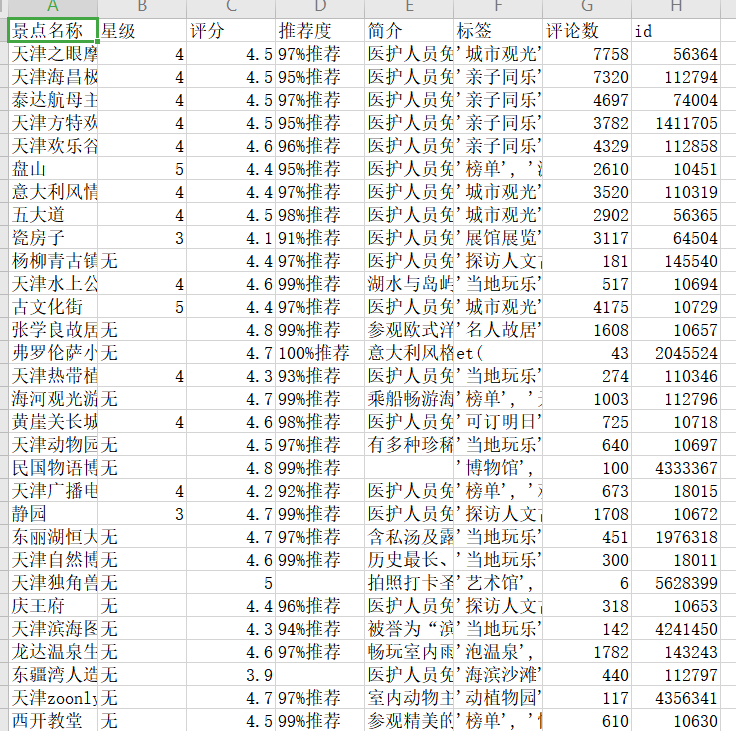
景点评论信息读取
import json import random import time from pprint import pprint import pandas as pd import requests import csv from xlrd import open_workbook import matplotlib.pyplot as plt from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] ids = [] names = [] # 打开文件读取数据并处理 with open("信息/测试.csv", "r", encoding="utf-8") as csvfile: reader = csv.reader(csvfile) for k, i in enumerate(reader): if k == 0: continue ids.append(i[7]) # 第7列内容 names.append(i[0]) print(ids[10:20]) print(names) url = "https://sec-m.ctrip.com/restapi/soa2/12530/json/viewCommentList" ua = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"] for k_n,id_ in enumerate(ids[0:20]): infos = [] print("第",k_n+1,"家") print(id_) time.sleep(1) try: for i in range(1,150): time.sleep(random.randint(1,5)) headers = { "Host": "sec-m.ctrip.com", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Referer": "https://piao.ctrip.com/dest/t62366.html", "Content-Type": "application/json", "cookieorigin": "https://piao.ctrip.com", "Origin": "https://piao.ctrip.com", "Content-Length": "301", "Connection": "keep-alive", "Cookie": "_RSG=IAKbfurzgT67orE1HidVdB; _RGUID=676af75e-2995-4292-b9df-9ec4413b5c87; _RDG=28082a428bdd5028b729a37e7358dc92a0; _ga=GA1.2.991982228.1577102675; MKT_CKID=1577102676203.kutn3.1xoq; _abtest_userid=6226bfd3-af4b-4b3e-9944-1481b77ec4e1; GUID=09031037111575175981; nfes_isSupportWebP=1; AHeadUserInfo=VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=1; UUID=2EB823AD79CF4F9782A3B6F1A4BC785A; IsPersonalizedLogin=F; MKT_Pagesource=PC; FlightIntl=Search=[%22HKG|%E9%A6%99%E6%B8%AF(HKG)|58|HKG|480%22%2C%22BJS|%E5%8C%97%E4%BA%AC(BJS)|1|BJS|480%22%2C%222020-03-02%22]; StartCity_Pkg=PkgStartCity=4; HotelCityID=28split%E5%A4%AA%E5%8E%9FsplitChengdusplit2020-3-8split2020-03-09split0; cticket=BE530BE5BB7E7811F220525E8C33169DD87C02F75B700B8245C86572EE2C02A2; ticket_ctrip=bJ9RlCHVwlu1ZjyusRi+ypZ7X2r4+yojzPTkvQyq9vImDzFP2o8THKDAyqgI/WdJuBe/PrX8z0uYhEi1ZEdd4z11qlPjrfQUSVGcfWg/4uN12MIM0gt3isFtN5F0BxIdZatidUi2UsVxx0i60xSK44YC5SJQx5m3ECqGoByW6jwfN/he0qPZxyQ1SaAJHlFcmtMH3529rMYVqLXi/AqJ6gIef4VItVL6I9SWudNZ04LL+pRNDTXIu0vl5ikJi29mpk0wo3EPysbqVbIg9DAlADh8vboQ2wJqh5AHiykS/CY=; DUID=u=6DAFC943576FCF25C099C08E47501D5F&v=0; IsNonUser=u=6DAFC943576FCF25C099C08E47501D5F&v=0; Session=SmartLinkCode=U155952&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=&SmartLinkLanguage=zh; __utma=1.991982228.1577102675.1584941982.1585295364.5; __utmz=1.1585295364.5.5.utmcsr=piao.ctrip.com|utmccn=(referral)|utmcmd=referral|utmcct=/dest/u-%E6%9D%AD%E5%B7%9E/s-tickets/; _RF1=116.132.81.181; _gid=GA1.2.754446494.1585453219; Union=OUID=index&AllianceID=4897&SID=155952&SourceID=&createtime=1585557042&Expires=1586161842447; MKT_CKID_LMT=1585557042481; gad_city=b6a29287793c7ffa817a1ee3a6776529; _bfs=1.8; _bfa=1.1577102671675.3iqikw.1.1585533737761.1585557037493.106.937.10650016817; _bfi=p1%3D10650000804%26p2%3D10650032348%26v1%3D937%26v2%3D936; _jzqco=%7C%7C%7C%7C1585557042635%7C1.2086882401.1577102676198.1585557078796.1585557097675.1585557078796.1585557097675.undefined.0.0.378.378; __zpspc=9.96.1585557042.1585557097.4%232%7Csp0.baidu.com%7C%7C%7C%25E6%2590%25BA%25E7%25A8%258B%7C%23; appFloatCnt=70", "Pragma": "no-cache", "Cache-Control": "no-cache", "TE": "Trailers" } da = {"viewid":id_,"pagenum":i,"head":{"appid":"100013776"}} resp = requests.post(url, headers=headers, data=json.dumps(da)).content.decode() js_info = json.loads(resp) c = js_info['data']['comments']
数据清洗
if c: for k,info in enumerate(c): # 如果评论内容小于5则不在采集范围之内,从源头实现数据清洗 if len(info['content']) < 5: continue infos.append({ '评分':info['score'], '时间':info['date'], '内容':info['content'] }) else: break except: print("外层错误"*30) continue
数据写入
# fileName = "./new_pl/{}.csv".format(names[k_n]) data = pd.DataFrame(infos) # 写入csv文件,'a+'是追加模式 csv_headers = ['评分', '时间', '内容'] data.to_csv(fileName, header=csv_headers, index=False, mode='w', encoding='utf_8_sig')
整理
import json import random import time from pprint import pprint import pandas as pd import requests import csv from xlrd import open_workbook import matplotlib.pyplot as plt from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] ids = [] names = [] # 打开文件读取数据并处理 with open("信息/测试.csv", "r", encoding="utf-8") as csvfile: reader = csv.reader(csvfile) for k, i in enumerate(reader): if k == 0: continue ids.append(i[7]) # 第7列内容 names.append(i[0]) print(ids[10:20]) print(names) url = "https://sec-m.ctrip.com/restapi/soa2/12530/json/viewCommentList" ua = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"] for k_n,id_ in enumerate(ids[0:20]): infos = [] print("第",k_n+1,"家") print(id_) time.sleep(1) try: for i in range(1,150): time.sleep(random.randint(1,5)) headers = { "Host": "sec-m.ctrip.com", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Referer": "https://piao.ctrip.com/dest/t62366.html", "Content-Type": "application/json", "cookieorigin": "https://piao.ctrip.com", "Origin": "https://piao.ctrip.com", "Content-Length": "301", "Connection": "keep-alive", "Cookie": "_RSG=IAKbfurzgT67orE1HidVdB; _RGUID=676af75e-2995-4292-b9df-9ec4413b5c87; _RDG=28082a428bdd5028b729a37e7358dc92a0; _ga=GA1.2.991982228.1577102675; MKT_CKID=1577102676203.kutn3.1xoq; _abtest_userid=6226bfd3-af4b-4b3e-9944-1481b77ec4e1; GUID=09031037111575175981; nfes_isSupportWebP=1; AHeadUserInfo=VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=1; UUID=2EB823AD79CF4F9782A3B6F1A4BC785A; IsPersonalizedLogin=F; MKT_Pagesource=PC; FlightIntl=Search=[%22HKG|%E9%A6%99%E6%B8%AF(HKG)|58|HKG|480%22%2C%22BJS|%E5%8C%97%E4%BA%AC(BJS)|1|BJS|480%22%2C%222020-03-02%22]; StartCity_Pkg=PkgStartCity=4; HotelCityID=28split%E5%A4%AA%E5%8E%9FsplitChengdusplit2020-3-8split2020-03-09split0; cticket=BE530BE5BB7E7811F220525E8C33169DD87C02F75B700B8245C86572EE2C02A2; ticket_ctrip=bJ9RlCHVwlu1ZjyusRi+ypZ7X2r4+yojzPTkvQyq9vImDzFP2o8THKDAyqgI/WdJuBe/PrX8z0uYhEi1ZEdd4z11qlPjrfQUSVGcfWg/4uN12MIM0gt3isFtN5F0BxIdZatidUi2UsVxx0i60xSK44YC5SJQx5m3ECqGoByW6jwfN/he0qPZxyQ1SaAJHlFcmtMH3529rMYVqLXi/AqJ6gIef4VItVL6I9SWudNZ04LL+pRNDTXIu0vl5ikJi29mpk0wo3EPysbqVbIg9DAlADh8vboQ2wJqh5AHiykS/CY=; DUID=u=6DAFC943576FCF25C099C08E47501D5F&v=0; IsNonUser=u=6DAFC943576FCF25C099C08E47501D5F&v=0; Session=SmartLinkCode=U155952&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=&SmartLinkLanguage=zh; __utma=1.991982228.1577102675.1584941982.1585295364.5; __utmz=1.1585295364.5.5.utmcsr=piao.ctrip.com|utmccn=(referral)|utmcmd=referral|utmcct=/dest/u-%E6%9D%AD%E5%B7%9E/s-tickets/; _RF1=116.132.81.181; _gid=GA1.2.754446494.1585453219; Union=OUID=index&AllianceID=4897&SID=155952&SourceID=&createtime=1585557042&Expires=1586161842447; MKT_CKID_LMT=1585557042481; gad_city=b6a29287793c7ffa817a1ee3a6776529; _bfs=1.8; _bfa=1.1577102671675.3iqikw.1.1585533737761.1585557037493.106.937.10650016817; _bfi=p1%3D10650000804%26p2%3D10650032348%26v1%3D937%26v2%3D936; _jzqco=%7C%7C%7C%7C1585557042635%7C1.2086882401.1577102676198.1585557078796.1585557097675.1585557078796.1585557097675.undefined.0.0.378.378; __zpspc=9.96.1585557042.1585557097.4%232%7Csp0.baidu.com%7C%7C%7C%25E6%2590%25BA%25E7%25A8%258B%7C%23; appFloatCnt=70", "Pragma": "no-cache", "Cache-Control": "no-cache", "TE": "Trailers" } da = {"viewid":id_,"pagenum":i,"head":{"appid":"100013776"}} resp = requests.post(url, headers=headers, data=json.dumps(da)).content.decode() js_info = json.loads(resp) c = js_info['data']['comments'] if c: for k,info in enumerate(c): # 如果评论内容小于5则不在采集范围之内,从源头实现数据清洗 if len(info['content']) < 5: continue infos.append({ '评分':info['score'], '时间':info['date'], '内容':info['content'] }) else: break except: print("外层错误"*30) continue # fileName = "./new_pl/{}.csv".format(names[k_n]) data = pd.DataFrame(infos) # 写入csv文件,'a+'是追加模式 csv_headers = ['评分', '时间', '内容'] data.to_csv(fileName, header=csv_headers, index=False, mode='w', encoding='utf_8_sig')
数据可视化分析
标签热度
import csv import xlrd import matplotlib.pyplot as plt from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] new_list = [] # 存储所有标签数据 time_list = [] # 标签列表 # 打开文件读取数据并处理 with open("景点基本信息.csv", "r", encoding="utf-8") as csvfile: reader = csv.reader(csvfile) for k, i in enumerate(reader): if k == 0: continue time_list.append(i[5]) for i in time_list: temp_list = i.split(',') for i2 in temp_list: new_list.append(i2.replace("'", "").replace(" ","")) data_dict = {} for i in new_list: if i == "榜单" or i == "et(": continue if i not in data_dict: data_dict[i] = 1 else: data_dict[i] += 1 # # new_data = sorted(data_dict.items(), key=lambda item: item[1], reverse=True)[0:20] x = [] y = [] for i in new_data: x.append(i[0]) y.append(i[1]) # 规定柱体样式 plt.figure(figsize=(33,6)) plt.bar(x, y, align='center', width=0.8) # 为每个条形图添加数值标签 for k,i in enumerate(y): plt.text(k,i,i) plt.title('景点热度图示') plt.ylabel('热度') plt.xlabel('景点名称') plt.savefig("./images/标签.png")

A级景区比例
from fractions import Fraction import matplotlib.pyplot as plt from pylab import mpl import csv # 声明编码 mpl.rcParams['font.sans-serif'] = ['SimHei'] temp = [] # 打开文件读取数据并处理 with open("景点基本信息.csv", "r", encoding="utf-8") as csvfile: reader = csv.reader(csvfile) for k, i in enumerate(reader): if k == 0: continue # 取出所有的评论存入content temp.append(i[1]) data_dict = {} for k,i in enumerate(temp): if i == "无": continue if i not in data_dict: data_dict[i] = 1 else: data_dict[i] += 1 print(data_dict) # # print(data_dict) # 对字典进行排序,按照value值,返回列表类型,嵌套元组 data_dict = sorted(data_dict.items(), key=lambda item: item[1], reverse=True) print(data_dict) nums = [] # 存储频率次数 vles = [] # 存储A级 for i in data_dict: vles.append(i[0]+"A") nums.append(i[1]) sum_nums = len(nums) squares = [x/sum_nums for x in nums] print(vles) print(squares) # # 保证圆形 plt.axes(aspect=1) plt.pie(x=squares, labels=vles, autopct='%3.1f %%') plt.savefig("./images/A级景区占比饼状图示.png")

月份热度(五大道为例)
import matplotlib.pyplot as plt from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] file_name = "五大道" # 景区名字 time_list = [] # 时间信息列表 # 打开文件读取数据并处理 with open("./new_pl/{}.csv".format(file_name), "r", encoding="utf-8") as csvfile: reader = csv.reader(csvfile) for k, i in enumerate(reader): if k == 0: continue time_list.append(i[1]) time_dict = {} for i in time_list: new_i = i[5:7].replace('/','') if new_i not in time_dict: time_dict[new_i] = 1 else: time_dict[new_i] += 1 new_data = sorted(time_dict.items(), key=lambda item: int(item[0]), reverse=False) month = [] nums = [] for i in new_data: month.append(i[0]) nums.append(i[1]) plt.plot(month, nums, linewidth=2,) # 调用绘制函数,传入输入参数和输出参数 plt.title("景区月份热度图示", fontsize=24) # 指定标题,并设置标题字体大小 plt.xlabel("月份", fontsize=14) # 指定X坐标轴的标签,并设置标签字体大小 plt.ylabel("数量", fontsize=14) # 指定Y坐标轴的标签,并设置标签字体大小 plt.tick_params(axis='both', labelsize=14) # 参数axis值为both,代表要设置横纵的刻度标记,标记大小为14 plt.savefig("./images/五大道淡旺季.png") # 打开matplotlib查看器,并显示绘制的图形

医护情况
from fractions import Fraction import matplotlib.pyplot as plt from pylab import mpl import csv # 声明编码 mpl.rcParams['font.sans-serif'] = ['SimHei'] desc = [] # 打开文件读取数据并处理 with open("景点基本信息.csv", "r", encoding="utf-8") as csvfile: reader = csv.reader(csvfile) for k, i in enumerate(reader): if k == 0: continue # 取出所有简介 desc.append(i[4]) # true 与 false t = 0 f = 0 # 我们仅对排名较为靠前的一些景区进行分析,较后的小型景区无人管理不在目标之中 for i in desc[0:100]: if i == "医护人员免费": t += 1 else: f += 1 vles = ['医护免费景区','其他'] sum_nums = 100 squares = [x/sum_nums for x in [t,f]] # 保证圆形 plt.axes(aspect=1) plt.pie(x=squares, labels=vles, autopct='%3.1f %%') plt.savefig("./images/医护福利占比饼状图示.png")

五、总结
1.经过对数据的分析和可视化,从几个图形分析得人们更愿意就近游玩,8-10月为旅游旺季,4A景点占据主流,过半景点没有医疗免费。
2.小结:在这次对旅游景点要素分析中,我从中学会了很多知识。很多次都卡在一个点上,绞尽脑汁去想解决问题的办法,通过观看b站的视频,百度搜索去找寻答案,求助于热心网友。认识到了编程的丰富内容,对于旅游要注意的几个内容有了了解。深刻意识到了难者不会会者不难,熟能生巧,要多做多练的道理。