一、环境配置
IDEA作为常用的开发工具使用maven进行依赖包的统一管理,配置Scala的开发环境,进行Spark Streaming的API开发;
1、下载并破解IDEA,并加入汉化的包到lib,重启生效;
2、在IDEA中导入离线的Scala插件:首先下载IDEA的Scala插件,无须解压,然后将其添加到IDEA中,具体为new---setting--plugins--"输入scala"--install plugin from disk

3、新建maven工程,模板中搜索带有scala的模板;

二、Scala和Spark的RDD基础
Scala是函数式编程的代表,Spark使用Scala语言开发,函数式Scala的一等公民,其有两种定义方式:
1、def定义一个方法,其实际上是类中方法:

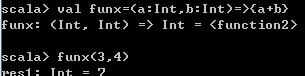
2、val定义一个函数变量:
部署Spark的on yarn模式后,可以读取HDFS上文件并计算,Spark采用了惰性机制,在执行转换操作的时候,即使输入了错误的语句,spark-shell也不会马上报错(假设文件不存在),下例读取hdfs上的txt文件,并将其空格拆分后筛选含有i字符的成员+'a'操作后,按照i分割后拍扁:

常用的RDD操作:

读取hdfs文件后的一个wordCount词频统计:读hdfs系统文件后,按照空格拍散,转化为一个Map键值对类型后统计其词频量,将其保存到hdfs上;

![]()
其任务计算过程如下:

Json数据是生产上最常用的数据类型,Spark提供了一个JSON样例数据文件,存放在“/usr/local/spark/examples/src/main/resources/people.json”中:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
使用Idea和maven工具进行开发scala代码如下,将其打包成jar使用spark-submit进行任务的提交。
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import scala.util.parsing.json.JSON
object JSONRead {
def main(args: Array[String]) {
val inputFile = "hdfs://172.22.241.177:8020/user/yzg/people.json"
val conf = new SparkConf().setAppName("JSONRead")
val sc = new SparkContext(conf)
val jsonStrs = sc.textFile(inputFile)
val result = jsonStrs.map(s => JSON.parseFull(s))
result.foreach( {r => r match {
case Some(map: Map[String, Any]) => println(map)
case None => println("Parsing failed")
case other => println("Unknown data structure: " + other)
}
}
)
}
}
如果使用IDEA进行Java的开发,在打包成jar包时,需要将主类放在porm的配置文件中,以cmos.yzg.spark.HelloWorld主类为例,如下:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>1.2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cmos.yzg.spark.HelloWorld</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>使用IDEA和maven工具进行打包的方法为:

打包完成后,使用spark-submit指令提交jar包并执行,如果提示cannot find main class的错误,可以删除--class选项后,继续提交任务(亲试有效)
/usr/local/spark/bin/spark-submit --class "JSONRead" /usr/local/spark/mycode/json/target/scala-2.11/json-project_2.11-1.0.jar
提交成功后,相关显示信息如下:

三、API开发
Spark Streaming是Spark Core扩展而来的一个高吞吐、高容错的实时处理引擎,它的数据源可以是多种,处理后的数据也可以有多种,如下:

它实时读取数据并将数据分为小批量的batch,然后在spark 引擎中被处理后生成了批量的结果集;

Spark Streaming提供了称为离散流或DStream的高级抽象,它表示连续的数据流。DStreams既可以从Kafka、Flume和Kinesis等源的输入数据流创建,也可以通过在其他DStreams上应用高级操作创建。在内部,DStream表示为RDD序列。
类似于Spark,Spark Streaming可以通过Maven Central获得。要编写自己的Spark Streaming程序,必须向SBT或Maven项目添加以下依赖项。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.0</version>
</dependency>为了从Spark Streaming核心API中没有的Kafka、Flume和Kinesis等源获取数据,您必须向依赖项添加相应的工件spark-streaming-xyz_2.11。例如:


要初始化流程序,必须创建一个流上下文对象,这是所有流功能的主要入口点,可以从SparkConf对象创建StreamingContext对象,appName参数是应用程序在集群UI上显示的名称。master是Spark、Mesos或YARN集群URL地址:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))定义StreamingContext之后,必须执行以下操作:
1、通过创建输入DStreams定义输入源。
2、通过向DStreams应用转换和输出操作来定义流计算。
3、开始接收数据并使用streamingContext.start()对其进行处理。
4、等待使用streamingContext.awaitTermination()停止处理(手动或由于任何错误)。
5、使用streamingContext.stop()手动停止处理。
需要记住的几点:
1、一旦启动了Context,就不能设置或添加新的流计算。
2、一旦停止了Context,就不能重新启动Context。
3、只有一个StreamingContext可以同时在JVM中活动。
4、StreamingContext上的stop()也停止SparkContext。为了仅停止StreamingContext,将stop()的可选参数stopSparkContext设置为false。
5、SparkContext可以重新用于创建多个StreamingContexts,只要在创建下一个StreamingContext之前停止前一个StreamingContext(不停止SparkContext)。
DStream
离散流或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流或者是从源接收的输入数据流或者是通过转换输入流生成的处理数据流。在内部DStream由一系列连续的RDD表示,这是Spark对不可变的分布式数据集的抽象,DStream中的每个RDD都包含来自某个时间间隔的数据,如下图所示。

应用于DStream的任何操作都转换为底层RDD上的操作。例如,在将行流转换为单词示例中,行DStream中的每个RDD应用flatMap操作以生成单词DStream的RDD。如下图所示:
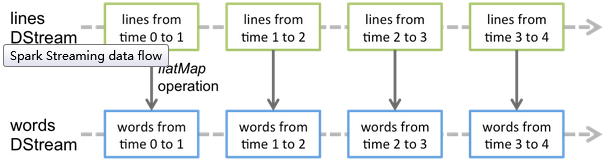
这些基础RDD转换由Spark引擎计算。DStream操作隐藏了大多数这些细节,并为开发人员提供了更高级别的API;
Input DStreams and receiver
如果希望在应用程序中并行接收多个数据流,则可以创建多个输入DStream,这将创建同时接收多个数据流的多个receiver。但注意Spark worker/executor是一个长期运行的任务,因此它占用分配给Spark Streaming应用程序的core。因此Spark Streaming应用程序需要分配足够的core(或线程,如果本地运行的话)来处理接收的数据,以及运行接收器。
在本地运行Spark Streaming程序时,不要使用“local”或“local[1]”作为主URL。这两者中的任何一个都意味着在本地运行任务只使用一个线程。如果使用基于receiver的输入DStream(如Kafka、Flume等)则单个线程将用于运行receiver,而不留下用于处理所接收数据的线程。因此,在本地运行时,始终使用“local[n]”作为主URL,其中n>要运行的receiver数量,将逻辑扩展为在集群上运行,分配给Spark Streaming应用程序的core数量必须大于接收者的数量。否则,系统将接收数据,但不能处理它。
Spark Streaming提供了两类内置的streaming sources
Basic sources:在StreamingContext API中直接可用的来源;
Advanced sources:kafka,flume等可以通过额外的实用程序类;
Basic sources:
ssc.socketTextStream(...)通过TCP套接字连接接收的文本数据创建DStream。除了套接字之外StreamingContext API还提供了从文件创建DStreams作为输入源的方法。为了从与HDFS API(即,HDFS、S3、NFS等)兼容的任何文件系统上的文件读取数据;
可以通过StreamingContext.fileStream[KeyClass、ValueClass、InputFormatClass]创建DStream
文件流不需要运行接收器,因此不需要为接收文件数据分配任何core。
对于简单的文本文件,最简单的方法是StreamingContext.textFileStream(dataDirectory)。
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
For text files
streamingContext.textFileStream(dataDirectory)Spark Streaming将监视目录dataDirectory并处理在该目录中创建的任何文件,例如“hdfs://namenode:8040/logs/”。所有直接位于此路径下的文件都将在发现时进行处理,可以提供匹配模式,例如“hdfs://namenode:8040/logs/2017/*”。这里,DStream将包含与模式匹配的目录中的所有文件
Advanced sources:
Kafka、Kinesis和Flume这类源需要外部非Spark库依赖包,其中一些库具有复杂的依赖关系(如Kafka和Flume)。因此为了最小化与依赖关系的版本冲突相关的问题,从这些源创建DStream的功能已经被转移到单独的库,这些库可以在必要时显式地链接到;
Spark shell中没有这些高级源代码,因此无法在shell中测试基于这些高级源代码的应用程序。如果你真的想在Shell shell中使用它们,你必须下载相应的Maven工件的jar以及它的依赖项,并将其添加到类路径中。
Receiver 的可靠性:
基于可靠性的考虑,可以将数据源分为两类。允许传输的源数据被确认(如Kafka和Flume)。如果从这些可靠的源接收数据的系统正确地接收所接收的数据,则可以确保由于任何类型的故障而不会丢失数据。这导致了两种接收器:
可靠的接收器:数据被接收后,Receiver 发送确认到源头,并将数据存储在spark;
不可靠的接收器:不可靠的接收器不会向源发送确认。
DStream的转换操作:
与RDD类似转换操作允许修改来自输入DStream的数据。DStreams支持在普通Spark RDD上可用的许多转换。一些常见的转换如下。

窗口操作
Spark Streaming提供窗口计算,允许您在滑动数据窗口上应用转换,如图所示每当窗口在源DStream上滑动时,落入窗口内的源RDD被组合并操作以产生窗口化DStream的RDD。在这种特定情况下,操作应用于最后3个时间单位的数据,并按2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
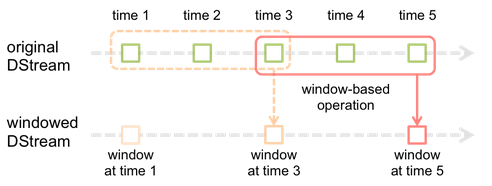
窗口长度: 窗口的持续时间(图中是3)
滑动间隔 :执行窗口操作的间隔(图中是2)
这两个参数必须是源DStream的批处理间隔的倍数(图中是1)
举例说明窗口操作:希望通过每隔10秒在最后30秒的数据中生成字数来扩展前面的示例。为此,我们必须在最后30秒的数据上对(word,1)对的DStream对应用reduceByKey操作。这是使用reduceByKeyAndWindow操作完成的。
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))一些常见的窗口操作如下。 所有这些操作都采用上述两个参数 - windowLength和slideInterval。

多流关联:
可以轻松地在Spark Streaming中执行不同类型的连接。
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)Dstreaming的输出:
输出操作允许将DStream的数据推送到外部系统,如数据库或文件系统。 由于输出操作实际上允许外部系统使用转换后的数据,因此它们会触发所有DStream转换的实际执行(类似于RDD的操作)。 目前,定义了以下输出操作:

使用foreachRDD的设计模式
Dstream.foreachRDD是一个功能强大的原语,允许将数据发送到外部系统。 但是,了解如何正确有效地使用此原语非常重要。 一些常见的错误要避免如下。
通常将数据写入外部系统需要创建连接对象(例如,到远程服务器的TCP连接)并使用它将数据发送到远程系统。 为此,开发人员可能无意中尝试在Spark驱动程序中创建连接对象,然后尝试在Spark工作程序中使用它来保存RDD中的记录。 例如(在Scala中),
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}这是不正确的,因为这需要连接对象被序列化并从驱动程序发送到worker。 这种连接对象很少可以跨机器转移。 此错误可能表现为序列化错误(连接对象不可序列化),初始化错误(需要在worker处初始化连接对象)等。正确的解决方案是在worker处创建连接对象。但是,这可能会导致另一个常见错误 - 为每条记录创建一个新连接。 例如,
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}通常,创建连接对象会产生时间和资源开销。 因此,为每个记录创建和销毁连接对象可能会产生不必要的高开销,并且可能显着降低系统的总吞吐量。 更好的解决方案是使用rdd.foreachPartition - 创建单个连接对象并使用该连接发送RDD分区中的所有记录。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}这会在许多记录上分摊连接创建开销。最后通过跨多个RDD /批处理重用连接对象,可以进一步优化这一点。 由于多个批次的RDD被推送到外部系统,因此可以维护连接对象的静态池,而不是可以重用的连接对象,从而进一步减少了开销。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
} 请注意,池中的连接应根据需要延迟创建,如果暂时不使用,则会超时。 这实现了最有效的数据发送到外部系统。
其他要记住的要点:
DStreams由输出操作延迟执行,就像RDD由RDD操作延迟执行一样。 具体而言,DStream输出操作中的RDD操作会强制处理接收到的数据。 因此,如果您的应用程序没有任何输出操作,或者具有dstream.foreachRDD()之类的输出操作而其中没有任何RDD操作,则不会执行任何操作。 系统将简单地接收数据并将其丢弃。默认情况下,输出操作一次执行一次。 它们按照应用程序中定义的顺序执行。
DataFrame和SQL操作:
可以轻松地对流数据使用DataFrames和SQL操作。 您必须使用StreamingContext正在使用的SparkContext创建SparkSession。 此外,必须这样做以便可以在驱动器故障时重新启动。 这是通过创建一个延迟实例化的SparkSession单例实例来完成的。 这在以下示例中显示。 它修改了早期的单词计数示例,以使用DataFrames和SQL生成单词计数。 每个RDD都转换为DataFrame,注册为临时表,然后使用SQL进行查询。
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// Get the singleton instance of SparkSession
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
// Convert RDD[String] to DataFrame
val wordsDataFrame = rdd.toDF("word")
// Create a temporary view
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on DataFrame using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}您还可以对从不同线程(即,与正在运行的StreamingContext异步)的流数据上定义的表运行SQL查询。 只需确保将StreamingContext设置为记住足够数量的流数据,以便查询可以运行。 否则,不知道任何异步SQL查询的StreamingContext将在查询完成之前删除旧的流数据。 例如,如果要查询最后一批,但查询可能需要5分钟才能运行,则调用streamingContext.remember(Minutes(5))(在Scala中,或在其他语言中等效)。有关DataFrame的详细信息,请参阅DataFrames和SQL指南。
四、Spark Streaming读取Kafka计算
Kafka 0.10的Spark Streaming集成在设计上与0.8 Direct Stream方法类似。 它提供简单的并行性,Kafka分区和Spark分区之间的1:1对应关系,以及对偏移和元数据的访问。
maven的配置spark依赖如下:
groupId = org.apache.spark
artifactId = spark-streaming-kafka-0-10_2.11
version = 2.4.0不要在org.apache.kafka(例如kafka-clients)上手动添加依赖项。 spark-streaming-kafka-0-10工件已经具有适当的传递依赖性。
创建Direct Stream:
导入的命名空间包括版本org.apache.spark.streaming.kafka010
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092,anotherhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topicA", "topicB")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(record => (record.key, record.value)) 有关可能的kafka参数,请参阅Kafka消费者文档。如果Spark批处理持续时间大于默认的Kafka心跳会话超时(30秒),请适当增加heartbeat.interval.ms和session.timeout.ms。对于大于5分钟的批次,这将需要在broker上更改group.max.session.timeout.ms。请注意,该示例将enable.auto.commit设置为false。
本地策略:
新版本的Kafka消费者API会将预先获取的消息写入缓存。因此Spark在Executor端缓存消费者(而不是每次都重建)对于性能非常重要 ,并且系统会自动为分区分配在同一主机上的消费者进程(如果有的话),一般来讲,你最好像上面的Demo一样使用LocationStrategies的PreferConsistent方法。它会将分区数据尽可能均匀地分配给所有可用的Executor。
消费策略:
新的Kafka消费者API有许多不同的方式来指定主题。它们相当多的是在对象实例化后进行设置的。ConsumerStrategies提供了一种抽象,它允许Spark即使在checkpoint重启之后(也就是Spark重启)也能获得配置好的消费者。
ConsumerStrategies允许订阅确切指定的一组Topic。
ConsumerStrategies的Subscribe方法通过一个确定的集合来指定Topic
ConsumerStrategies的SubscribePattern方法允许你使用正则表达式来指定Topic,
注意,与0.8集成不同,在SparkStreaming运行期间使用Subscribe或SubscribePattern,应该响应添加分区。最后,ConsumerStrategies.Assign()方法允许指定固定的分区集合。所有三个策略(Subscribe,SubscribePattern,Assign)都有重载的构造函数,允许您指定特定分区的起始偏移量。如果上述不满足您的特定需求,可以对ConsumerStrategy进行扩展、重写
