- EmotiW2015比赛静态表情识别的亚军,采用的方法为cnn的级联,人脸检测方面也采用了当时3种算法的共同检测,通过在FER2013数据库上进行模型预训练,并在SFEW2.0(比赛数据)上fine-tune,从而在比赛的验证集和测试集上取得55.96%和61.29%的准确率,远远超过比赛的baseline(35.96%,39.13%)。
作者本文主要贡献如下:
- 1.实现了CNN架构,在表情识别方面性能卓越。
- 2.提出了一种数据增强和投票模式,应有提高CNN的性能。
- 3.提出了一种优化方法自动的决定级联CNN的权重分配问题。
- 多种串联方式检测人脸
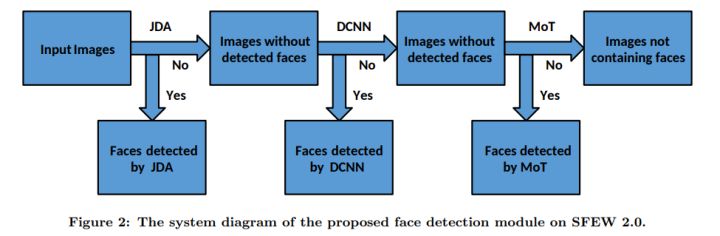
由于SFEW数据库给出的静态图像,背景非常复杂,同时为了后续的CNN表情分类,人脸的检测与对齐是非常重要的,因此作者级联了三个state-of-the-art的人脸检测算法,从而保证人脸检测的正确性.三种检测算法为(JDA,DCNN,MoT),图像事先resize为1024x576.总共帧为372,实验结果如下表所示:
Method JDA DCNN MoT JDA+DCNN JDA+DCNN+MoT Det # 333 358 352 363 371
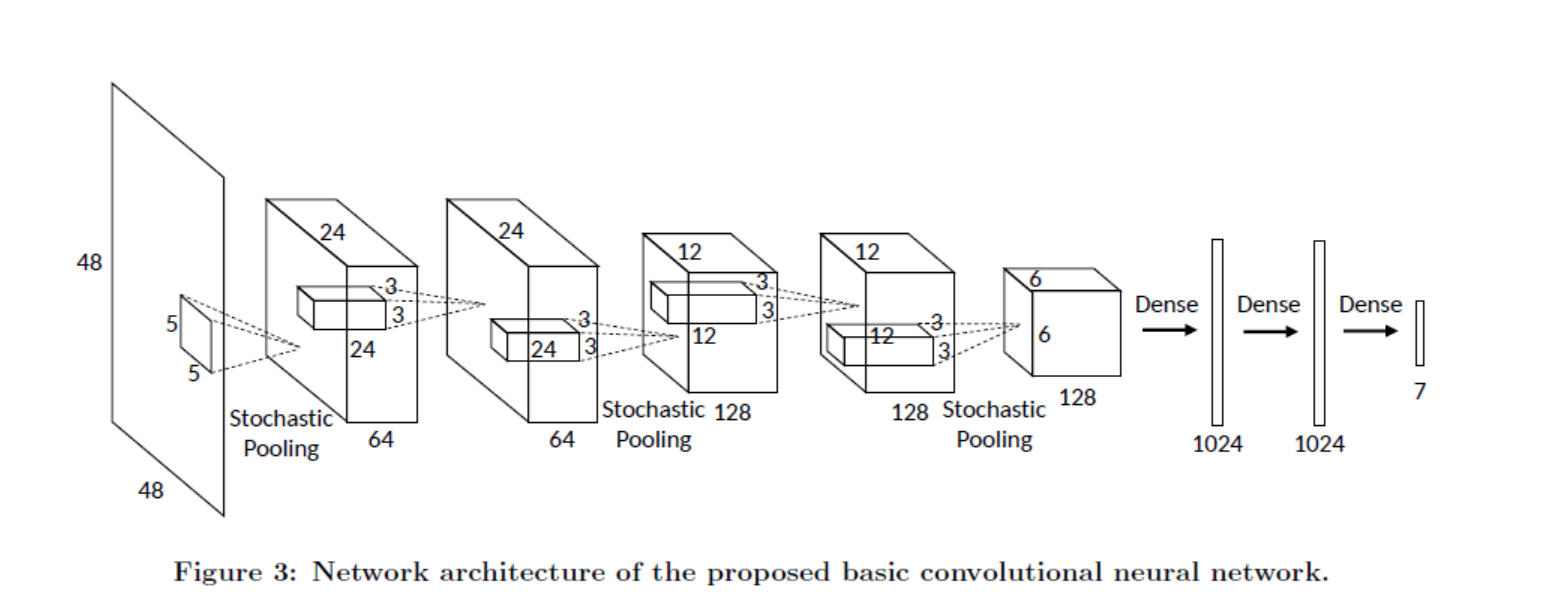
- 2 五个卷积层,三个随机池层和三个完全连接的层的网络结构。
- 3 较完整地对训练图片进行随机裁剪、翻转、旋转、倾斜等等。
- 数据预处理对后续的识别有极大的影响,良好的数据预处理可以去除样本间的无关噪声,并能够一定程度的做到数据增强。图像尺寸归一化(48x48)直方图均衡化,去均值除方差。样本扩增(论文5.2),由于FER数据库包含35000+的图片,因此作者采用fer数据库进行预训练,作者对数据进行了随机的旋转,从而生成了更多的样本,使得网络训练的结果更具有鲁棒性。,样本生成公式以及效果图如下图所示:

-
- 其中θ是从三个不同值随机采样的旋转角度:{ - π/18,0,π/18}。
- s1和s2是沿着x和y方向的偏斜参数,并且都是从{-0.1,0,0.1}随机采样的。
- c是随机尺度参数。定义为c = 47 /(47 - δ),其中δ是[0,4]上随机采样的整数。
- 实际上,用下面的逆映射产生变形的图像:

-
- 其中A是歪斜,旋转和缩放矩阵的组成。输入(x'∈[0,47],y'∈[0,47])是变形图像的像素坐标。简单地计算逆映射以找到对应的(x,y)。由于所计算的映射大多包含非整数坐标,因此使用双线性插值来获得扰动的图像像素值
- t1和t2是两个平移参数,其值从{0,δ}被采样并且与c耦合。
- 4 扰动的学习和投票:
- 架构最后有P个Dense(7),这P个扰动样本的输出结果的平均投票,(合并后)作为该图像的预测值。
- 5 预训练:
- 样本随机扰动
- 训练时候增加了超过25%或者连续5次增加train loss ,则降低学习率为之前的一半,并重新加载之前损失最好的模型,继续训练.
- 6 克服过拟合问题:
- 冻结所有卷积图层的参数,只允许在完全连接的图层上更新参数。
- 7 上述都是单一网络,现采用集成多网络方式。
-
- 常用方法是对输出响应进行简单平均。
- 此处采用自适应地为每个网络分配不同的权重,即要学习集合权重w。采用独立地训练多个不同初始化的CNN并输出他们的训练响应。在加权的集合响应上定义了损失,其中w优化以最小化这种损失。在测试中,学习的w也被用来计算整体的测试响应。
- 在本文中,我们考虑以下两个优化框架:
- 最大似然方法
- 最小化Hinge loss
实验结果
作者分别列出了在FER,SFEW上数据库的单独训练结果以及,采用提升的级联方式对最终结果的提高。
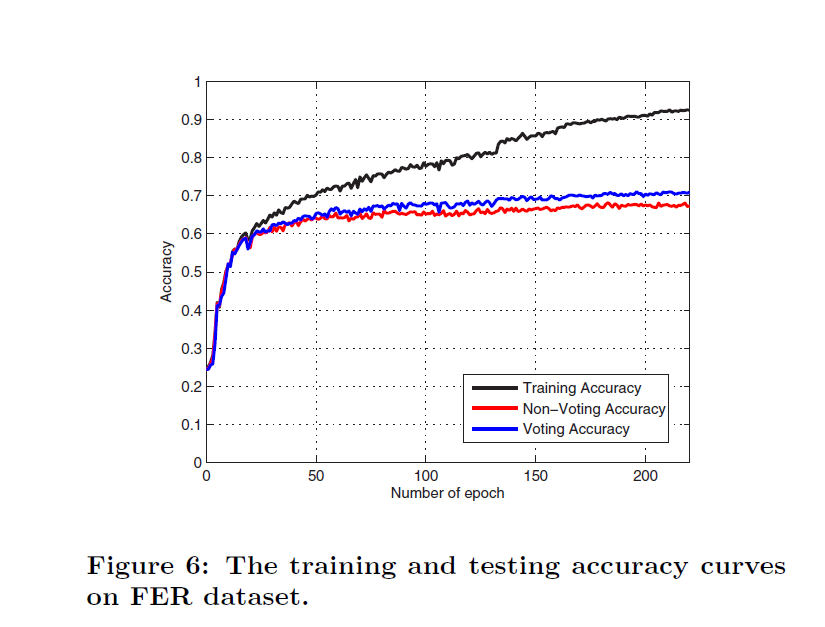 FER数据集trainval结果FER数据集trainval结果
FER数据集trainval结果FER数据集trainval结果
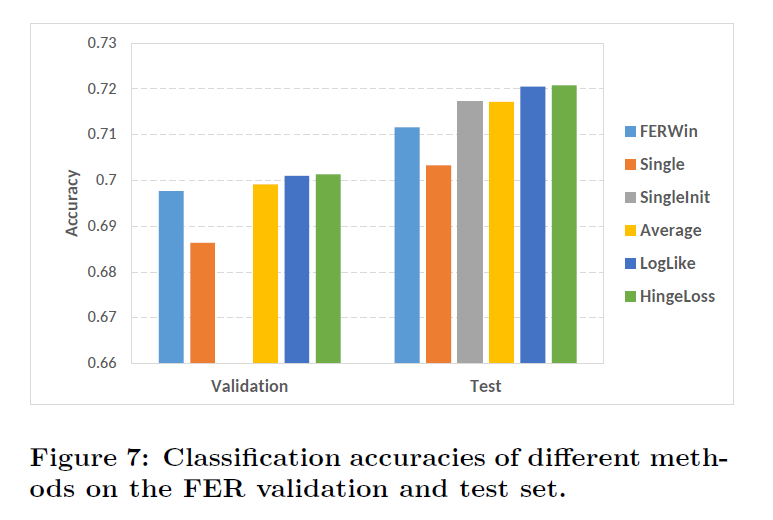
FER数据集不同Loss与级联方式的结果FER数据集不同Loss与级联方式的结果

SFEW数据集VoteNoVote的结果SFEW数据集VoteNoVote的结果
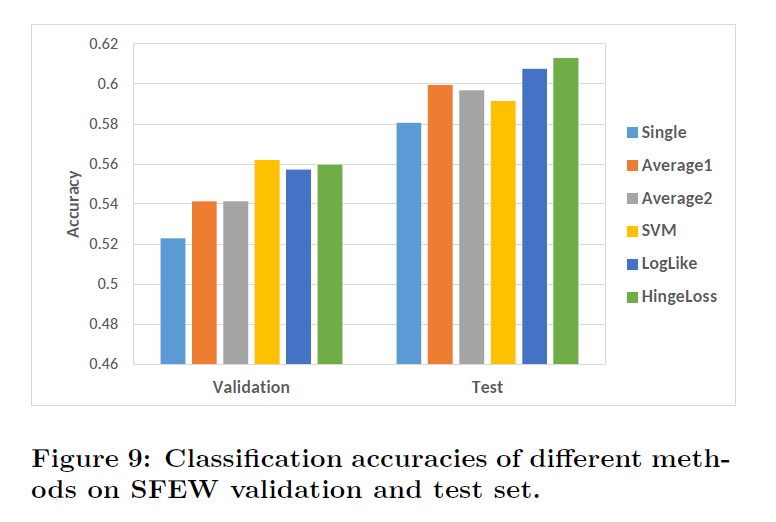
SFEW数据集不同Loss与级联方式的结果SFEW数据集不同Loss与级联方式的结果
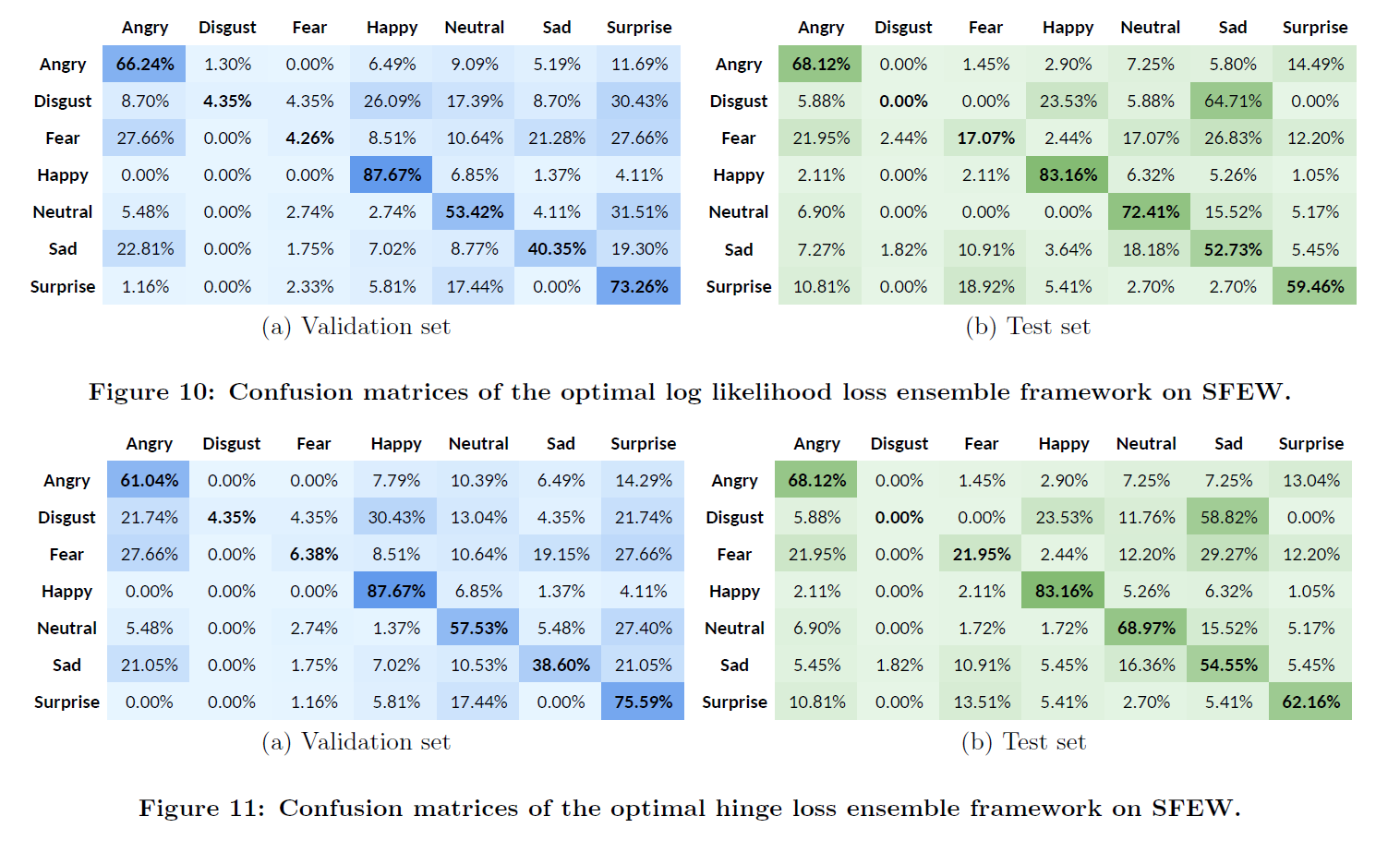
SFEW数据库上的测试混淆矩阵SFEW数据库上的测试混淆矩阵结论
预训练+提升的级联方式对最终的识别效果有效。同时,样本扩增对实验提升也是有作用的。
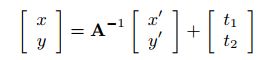


《Hierarchical Committee of Deep CNNs with Exponentially-Weighted Decision Fusion for Static Facial Expression Recognition》
EmotiW 2015的冠军,和《2015-Image based Static Facial Expression Recognition with Multiple Deep Network Learning》类似的方法。
- 先对图片做align,
- 然后设计了三种CNN,由不同的输入,不同的训练数据和不同的初始化训练了216个model,
- 然后用自己提出的方法将这些model组合起来
- 都是想办法增加训练集,让一张图片生成多张,
- 又比如训练多个model结合起来
- 就经常见到的那些方法。