结构体是一块连续的内存,
定义结构体需要使用关键字struct修饰
下面我将定义2个结构体,他们分别是
struct MyStruct1
{
char a;
double b;
int c;
};
struct MyStruct2
{
double b;
char a;
int c;
};
int main()
{
MyStruct1 mys1;
MyStruct2 mys2;
std::cout << sizeof(mys1) << "\n";
std::cout << sizeof(mys2) << "\n";
}
上述打印结果为:
24
16
因为结构体的字节对齐特性导致结构体的大小不一样,下面是我自己对字节对齐特性的理解,仅供同行参考,因为每个人有每个人自己的学习方法与理解方式
字节对齐
我定义了一个结构体,如下,因为为了阐述字节对齐这个特性,我觉得上面两个结构体有些复杂,所以下面的结构体用来解释字节对齐
struct MyStruct3
{
char a;//1个字节
int c;//4个字节
short b;//2个字节
};
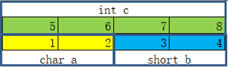
MyStruct3在内存中实际是这样的,其中1表示内存中第1个字节,2表示内存中第2个字节,以此类推,12表示内存中的第12个字节

从图中可以看出,
char a占用了黄色的内存,是4个字节
int c占用了绿色的内存,4个字节
short b占用了浅蓝的内存,4个字节
因为
int4个字节>short2个字节>char1个字节,所以该结构体所有类型都向int看齐
又因为
先定义的char,之后定义的int,之后定义的short
所以从图中可以看出第1排是char,第2排是int,第3排是short
综上两个"因为",所以才出现上述的图,它占用了12个字节
下面我又定义了一个结构体
struct MyStruct4
{
int c;//4个字节
char a;//1个字节
short b;//2个字节
};
MyStruct4在内存中是下面这样存在的
其中绿色依然表示int c,黄色表示char a,蓝色表示short b,从图中可知结构体MyStruct4占了8个字节
综上所述,我个人通常会把结构体的"字节对齐",理解成,"根据最长类型的字节补全内存"
但是一个新的问题产生了,为什么要出现字节对齐这种性质呢??
我们回到上面的MyStruct3
struct MyStruct3
{
char a;//1个字节,我依然用黄色表示
int c;//4个字节,我依然用绿色表示
short b;//2个字节,我依然用蓝色表示
};
现在我们进行几个假设:
假设1:不存在字节对齐这个概念
那么MyStruct3在内存中的数据应该是下面这样子的,很简单,就是按照顺序排列呗

黄色表示char a,可以看出占用1个字节
蓝色表示short b,可以看出占用2个字节
绿色表示int c,可以看出占用4个字节
最后的内存8没有使用到,综上,假设不存在字节对齐这个概念,那么该结构体占用7个字节
接下来,我在假设1的基础上,进行假设2
假设2:CPU一次只读取一个字节
若CPU一次只读取一个字节,这是没有什么问题的,完全不需要字节对齐,因为无论如何,CPU如果一次只读取一个字节,那么某个数据占几个字节,CPU就要读取几次数据,所以,若CPU一次只能读取1个字节,那么就不需要,也没必要存在字节对齐
可是,现在的CPU一次并不是读取一个字节,现代CPU一次都是读取4字节,或者8字节,那么这就出现个问题,根据上面的图,可以看出若一次读取4字节,那么,会读取1234,然而4是int c中的第一个字节,也就是说,这会读取int 前四分之一,后四分之三没有读取到,若是再读int,只能读取后面四分之三,然后将前面四分之一和后面读取的四分之三拼接起来,所以我个人认为字节对齐就是为了避免拆分字(word)的一种行为,因为拆分字之后,再将字组合,会很麻烦
NOTE:
什么叫做字?我理解这叫做字
