前言
一个高级测试工程师在自学Python后,向我推荐的一个比较容易上手的Python 框架scrapy。在网上搜索了一下资料后感觉挺有趣的,就想着自己也搭建个环境,然后做一个爬取图片的demo玩下。
开发环境搭建
Python安装
下载地址:https://www.python.org/getit/
这里我下载的是3.8.0的版本(我的安装目录是:D:\python\Python38-32)
安装完后设置环境变量:在path中追加:D:\python\Python38-32; D:\python\Python38-32\Scripts
升级pip
输入命令:
python -m pip install --upgrade pip
安装scrapy依赖的模块
安装wheel
进入cmd执行命令命令:
> pip install wheel
安装pywin32
下载地址:https://github.com/mhammond/pywin32/releases
由于我安装的Python是32位的,估选择win32-py3.8版本,下载后双击安装即可

安装 lxml
运行命令:
> pip install lxml
安装Twisted
由于直接使用命令在线安装一直报下载超时,估采用离线安装的方式
下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

运行命令:
> pip install Twisted-19.10.0-cp38-cp38-win32.whl
安装scrapy
运行命令:
> pip install scrapy
到目前为止就完成了scrapy环境的搭建,相对简单
编写demo
准备内容
被爬网站
选择百度图片首页:http://image.baidu.com/
规则分析
首先想到的是通过xpath的方式来爬取图片,xpath语句://div[@class=“imgrow”]/a/img/@src。但是在编写爬虫(Spiders)的时候发现http://image.baidu.com/请求并没有将图片的URL直接返回,而是通过后面的异步请求获取,而且返回的是一个json字符串,估xpath方式行不通。
更换异步请求的URL为被爬网站:http://image.baidu.com/search/acjson?tn=resultjson_com&catename=pcindexhot&ipn=rj&ct=201326592&is=&fp=result&queryWord=&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=pcindexhot&face=0&istype=2&qc=&nc=1&fr=&pn=0&rn=30
创建scrapy项目 ImagesRename
运行命令:
> scrapy startproject ImagesRename
执行完后生成项目的目录结构如图:
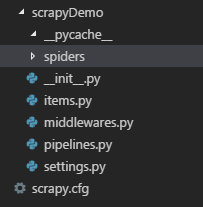
其中:
spiders目录:用于放置爬虫文件
items.py:用于保存所抓取的数据的容器,其存储方式类似于 Python 的字典
pipelines.py:核心处理器,对爬取到的内容进行相应的操作,如:下载,保存等
settings.py:配置文件,修改USER_AGENT、存储目录等信息
scrapy.cfg:项目的配置文件
编写item容器 items.py
import scrapy
class ImagesrenameItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
imgurl = scrapy.Field()
pass
创建蜘蛛文件ImgsRename.py
# -*- coding: utf-8 -*-
import scrapy
import json
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ImagesRename.items import ImagesrenameItem
class ImgsRenameSpider(CrawlSpider):
name = 'ImgsRename'
allowed_domains = ['image.baidu.com']
#http://image.baidu.com/ 并没有返回图片链接,而是通过异步请求接口获取的,爬取的URL必须是异步请求的链接
start_urls = ['http://image.baidu.com/search/acjson?tn=resultjson_com&catename=pcindexhot&ipn=rj&ct=201326592&is=&fp=result&queryWord=&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=pcindexhot&face=0&istype=2&qc=&nc=1&fr=&pn=0&rn=30',]
def parse(self, response):
# 实例化item
item = ImagesrenameItem()
#解析异步请求返回的json字符串
#经过分析需要的图片链接保存在json——》data——》hoverURL
jsonString = json.loads(response.text)
data = jsonString["data"]
imgUrls = []
#循环将图片URL保存到数组中
for d in data:
if d:
hov = d["hoverURL"]
imgUrls.append(hov)
item['imgurl'] = imgUrls
yield item
编写核心处理器图片下载中间件pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import re
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class ImagesrenamePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 循环每一张图片地址下载
for image_url in item['imgurl']:
#发起图片下载的请求
yield Request(image_url)
修改配置文件settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for ImagesRename project
BOT_NAME = 'ImagesRename'
SPIDER_MODULES = ['ImagesRename.spiders']
NEWSPIDER_MODULE = 'ImagesRename.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'ImagesRename (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'ImagesRename.pipelines.ImagesrenamePipeline': 300,
}
# 设置图片存储目录
IMAGES_STORE = 'E:\图片'
启动程序下载图片
运行命令:
scrapy crawl ImgsRename
到目前为止就已经完成了一个简单的图片爬取程序,结果如图:
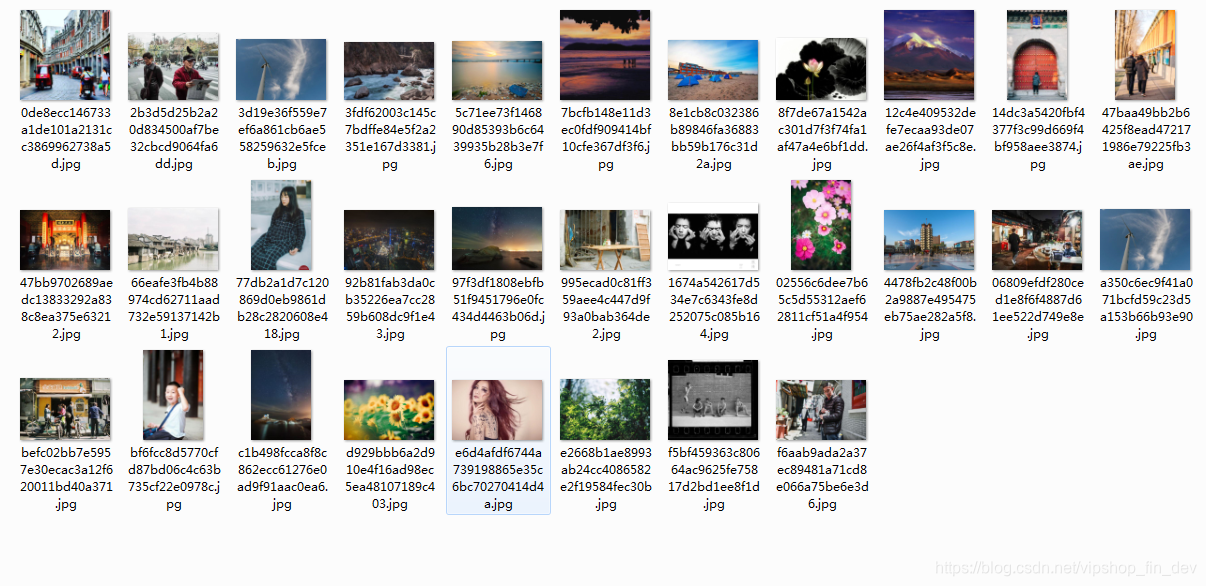
当然这些下载的文件名称是一个随机数,如果需要按照一个格式的文件名存储则可以重新ImagesPipeline类的file_path方法即可,这里就不做详细的介绍
