Javac和Java是JDK自带的工具,其中Javac是编译工具,Java工具启动JVM虚拟机并执行java程序。这两个工具都带有设置字符编码的选项。本文讨论字符编码选项的使用场景,和出现乱码的原因。先把结论写在这里,如不想阅读后面的章节,可只看这里的结论。
注:文中的字符编码和字符集是同一概念。我之前有篇博客专门阐述这个问题:https://www.cnblogs.com/jayson-jamaica/p/12652873.html
结论:Javac 的字符编码选项
- 形式:javac -encoding CharSet XXXX.java //CharSet为XXXX.java文件的字符编码。
- javac编译器根据-encoding后跟随的字符编码,解析.java文件。-encoding不设置的时候,使用系统默认字符集解析.java文件。Windows的默认字符集是GBK。
- 无论之前的.java文件采用什么编码,编译后的.class文件都使用utf8编码。
- 如果-encoding指定的字符编码与.java文件的字符编码不一致,不一定编译失败,会给后续乱码埋下隐患。
结论:JVM的字符编码选项
- 形式:java -Dfile.encoding= CharSet XXXX //XXXX为class文件,CharSet是本地设备支持的字符集。
- -Dfile.encoding并不是设置JVM虚拟机内存字符编码的。JVM虚拟机内存的字符编码是无法设置的,都是UTF-16.
- JVM加载.class文件中的字符,转化为UTF-16存在内存中。在字符需要与本地设备交互时才根据encoding选项后的字符集编码或解码。
- -Dfile.encoding不设置的时候,使用系统默认字符集,Windows的默认字符集是GBK。
JVM的字符编码选项不太好理解,举个简单的例子,以下面这段代码来说明:
String str = "脑袋里有一盆酱";
OutputStream outputStream = new FileOutputStream("D:\\test\\t.txt");
outputStream.write(str.getBytes());
上面的代码就是把几个中文字符写到t.txt文件中,程序执行完成后,t.txt文件的字符编码是GBK还是UTF-8,这取决于-Dfile.encoding选项,如果选项指定为GBK,那么t.txt文件的字符编码就是GBK;如果指定为UTF-8,那么t.txt文件的字符编码就是UTF-8.
详解:Javac与JVM的字符编码选项
这一篇博客写的非常好,https://blog.csdn.net/lgh1992314/article/details/77482046。很多细节我是看了这篇博客才理清楚的。后面很多地方也会引用这篇博客的图以及观点,先表示感谢。先上图吧。
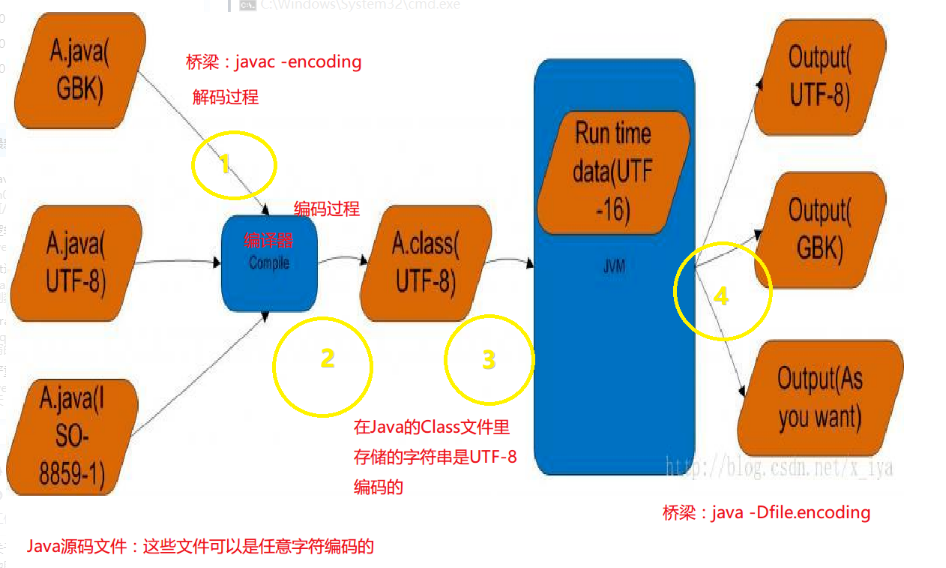
上图是.java文件从编译到执行的几个过程,这几个过程涉及到字符编码,具体解释摘抄如下:
①、A.java就是一个文本文件(以某种编码格式来存储:UTF-8、GBK、ISO-8859-1等),java编译器要解析这个文本文件并编译生成.class文件。而要想解析它,就必须知道它的编码方式。(javac - encoding charset)如果encoding指定的编码与文件的编码不一致,要么编译失败,要么导致class文件中的字符乱码。
②:以不同编码方式编码的A.java经过Java编译器编译生成了同一个相同的A.class。(字符串以UTF-8格式存储) 字节码解读见:http://blog.csdn.net/x_iya/article/details/77073112
③:java虚拟机以二进制字节流的形式加载A.class,A.class中的字符编码是utf8,加载到JVM虚拟机内存中后,字符编码是utf16。
④:输出结果,如代码中指定了字符集,则按照代码中指定的字符集输出到设备中。如果代码中未指定字符集,则按照JVM启动时 -Dfile.encoding指定的字符集输出到设备中。如设备不支持该字符集,则显示乱码。
Javac的字符编码选项
上图的过程1,就是java的编译过程,JDK自带的编译工具javac支持设定encoding选项,形式如下:
javac -encoding CharSet xxxx.java //CharSet应为xxxx.java文件的字符集
javac根据encoding指定的字符集解析xxxx.java中的字符,如果encoding指定的字符集与.java文件的字符集一致,则能正常解析和编译。如果encoding指定的字符集与.java文件的字符集不一致,解析的结果有两种:一种是解析失败,编译失败;另一种是解析为其他字符,编译成功,但是class文件中的字符编码有误(也就是乱码)。
javac编译实验1
String str = "脑袋里有一盆酱"; OutputStream outputStream = new FileOutputStream("D:\\test\\t.txt"); outputStream.write(str.getBytes());
根据上面的代码,创建两个Java类,分别为GbkCode和Utf8Code,GbkCode使用gbk字符集,Utf8Code使用utf-8字符集,把上面的代码整理到两个类中。分别使用javac,javac -encoding gbk, javac -encoding utf8 编译两个java文件。然后查看class文件的字符编码。得到以下表格。
| 编译命令 | 编译结果 | class文件字符编码 |
|---|---|---|
| javac GbkCode.java | 成功,生成GBKCode.class文件 | utf-8编码 |
| javac -encoding gbk GbkCode.java | 成功,生成GBKCode.class文件 | utf-8编码 |
| javac -encoding utf8 GbkCode.java | 失败,utf8不可映射字符xxxx | \ |
| javac Utf8Code.java | 失败,gbk不可映射字符xxxx | \ |
| javac -encoding gbk Utf8Code.java | 失败,gbk不可映射字符xxxx | \ |
| javac -encoding utf8 Utf8Code.java | 成功,生成Utf8Code.class文件 | utf-8编码 |
注:判断class文件字符编码的方法有很多,我是使用Notepad++来确认class文件的编码的。使用notepad++打开class文件,查看二进制,搜索“脑袋里有一盆酱”的utf8对应的二进制序列,如果搜到,就说明是utf-8编码。Notepad++查看二进制的方法请看我另一篇博客:https://www.cnblogs.com/jayson-jamaica/p/12659229.html
实验1测试了-encoding选项指定的字符集与.java文件字符集各种匹配情况。得出的结论是encoding选项指定的字符集与.java文件字符集一致,则编译成功;不一致时,则编译失败。但是这个实验不够充分,因为如果不一致就编译失败,那编译环节就永远不会存在乱码问题了。因此继续实验2.
javac编译实验2
我试着编造个字符串,看能不能骗过编译器。我通过Notepad++发现了一对字符串,“人民” 的utf8编码 与“浜烘皯” 的gbk编码一致,于是我把上面的代码做如下修改:
String str = "人民";// 用utf8编码,保存在Utf8Code.java文件中,使用encoding gbk编译。 String str = "浜烘皯";//用gbk编码,保存在GbkCode.java文件中,使用encoding utf8编译。
果然骗过了编译器,class文件中的编码,就出现了乱码,结果如下:
| 编译命令 | 编译结果 | class文件字符编码 |
|---|---|---|
| javac -encoding gbk Utf8Code.java | 成功,生成Utf8Code.class文件 | 本应是“人民”的utf8编码,变成了“浜烘皯”的utf8编码 |
| javac -encoding utf8 GbkCode.java | 成功,生成GBKCode.class文件 | 本应是“浜烘皯”的utf8编码,变成了“人民”的utf8编码。 |
实验二证明了,在有些时候,encoding选项指定的字符集与.java文件的字符集不一致,但是也能编译成功,但是class文件中的编码有问题。这会导致执行过程中出现乱码。
JVM的字符编码选项
使用java XXXX命令,启动JVM虚拟机,并执行XXXX.class文件。前面已经说过,class文件中的字符编码是utf8. JVM虚拟机中存储字符使用的是utf16字符编码,且不能设置。那java -Dfile.encoding=CharSet xxxx `的作用是什么呢?
JVM虚拟机有时与本地设备进行IO操作,因此需要知道设备兼容的字符编码。-Dfile.encoding就是告知虚拟机本地设备的字符编码。有些设备支持多种字符编码,比如说文件;有些设备可能仅支持一种字符编码,比如说终端/Terminal/Console等。下面做两个实验分别验证下。
Java encoding实验1
String str = "脑袋里有一盆酱"; OutputStream outputStream = new FileOutputStream("D:\\test\\t.txt"); outputStream.write(str.getBytes());
依然是这段代码,分别使用utf8/gbk编码,使用正确的-encoding选项编译;对class文件使用不同的-Dfile.encoding选项执行,得到如下结果:
| 编译命令 | 执行命令 | t.txt文件字符编码 |
|---|---|---|
| javac -encoding utf8 Utf8Code.java |
java -Dfile.encoding=UTF-8 Utf8Code | UTF-8 |
| java -Dfile.encoding=GBK Utf8Code | GBK | |
| javac -encoding gbk GBKCode.java |
java -Dfile.encoding=UTF-8 GBKCode | UTF-8 |
| java -Dfile.encoding=GBK GBKCode | GBK |
注意:每次使用java命令执行程序前,需要把上次执行得到的t.txt文件删除。不然得到的结果可能会异常。
通过这个实验,可以得到-Dfile.encoding的用途:适配本地设备兼容的字符集(这个实验是适配文件系统的字符集,估计网络IO的字符集适配也是同样的)。大家写测试代码的时候,似乎更喜欢使用console打印的形式,而非把结果打印到文件。下面的实验将测试把字符打印到console。
Java encoding 实验2
String str = "脑袋里有一盆酱";
System.out.println(str);
System.out.println(Arrays.toString(str.getBytes()));//此行代码的目的是验证str是确实受-Dfile.encoding影响。
这段代码把结果打印到控制台。分别使用utf8/gbk编码编写.java文件,使用正确的-encoding选项编译;对class文件使用不同的-Dfile.encoding选项执行。为了让测试结果更有说服力,使用三种终端来执行。一种是windows自带的cmd命令行,一种是Cygwin64 Terminal,一种是在Ubuntu的Terminal中。
这里先说明一下终端的默认字符集:我的电脑是win10系统,cmd命令行和Cygwin64 Terminal都默认使用GBK字符编码;Ubuntu的Terminal默认的使用utf8字符编码。
对于终端默认的字符集,可以简单测试验证下,分别使用命令查看utf8的文本文件和gbk的文本文件,若gbk的文本文件显示正常,utf8的文本文件出现乱码,则说明终端的默认字符集是gbk。cmd查看文件的命令是type 文件名, Cygwin64 Terminal的命令与Ubuntu命令一样,查看文件的命令是cat 文件名。具体做法可以参照下面这篇博客:https://blog.csdn.net/lgh1992314/article/details/77482046
实验的结果如下:
| 编译命令 | 执行命令 | cmd控制台输出 | Cygwin64 Terminal输出 | Ubuntu Ternimal输出 |
|---|---|---|---|---|
| javac -encoding utf8 Utf8Code.java |
java -Dfile.encoding=GBK Utf8Code | 正常 | 正常 | 乱码 |
| java -Dfile.encoding=UTF-8 Utf8Code | 正常 | 乱码 | 正常 | |
| javac -encoding gbk GBKCode.java |
java -Dfile.encoding=GBK GBKCode | 正常 | 正常 | 乱码 |
| java -Dfile.encoding=UTF-8 Utf8Code | 正常 | 乱码 | 正常 |
这个实验结果比较有意思,win10的cmd控制台的结果都正常,结果似乎不能推断出什么,这里后面再讨论。 Cygwin64 Terminal和Ubuntu Terminal的结果在意料之中, Cygwin64 Terminal默认的编码格式是GBK,因此Dfile.encoding=UTF-8执行文件会乱码,在 Dfile.encoding=GBK是显示正常。Ubuntu Terminal的默认编码格式是utf8,因此Dfile.encoding=UTF-8显示正常,在 Dfile.encoding=GBK显示乱码。
UbuntuTerminal 设置字符集非常方便,我们做更多测试试一下,测试结果如下:
| 执行命令 | Terminal字符集utf8 | Terminal字符集gbk | Terminal字符集gb18030 |
|---|---|---|---|
| -Dfile.encoding=UTF-8 | 正常 | 乱码 | 乱码 |
| -Dfile.encoding=GBK | 乱码 | 正常 | 正常 |
| -Dfile.encoding=gb18030 | 乱码 | 正常 | 正常 |
由于gbk字符集和gb18030兼容,因此Terminal字符集为gb18030时,-Dfile.encoding=GBK执行文件没有乱码。因此实验2,可以得出结论:-Dfile.encoding设置字符编码要与终端/console/Terminal的字符编码兼容。
小结:
关于Javac的encoding问题和java -Dfile.encoding问题,已经清楚了。
- javac 的encoding选项跟随的字符集,必须与.java文件使用的字符集一致,不然会在class文件中产生乱码。
- java -Dfile.encoding跟随的字符集,必须与设备支持的字符集兼容,这里的设备可能是文件系统,可能是终端,也有可能是网络。网络部分我还没学到,暂时不讨论。
写在最后:
为了搞清楚javac和JVM字符编码问题,我花了一个多星期时间,看了很多博客,做了很多实验,甚至还专门安装了虚拟机和Ubuntu。但现在仍然有两个问题遗留。一个是Win10自带的cmd终端,执行class文件时,无论 -Dfile.encoding跟随的字符集是什么,都不会出现打印乱码;第二个问题是Cygwin64 Terminal的字符集改为utf8时, -Dfile.encoding=UTF-8,依然打印乱码。
对于这两个遗留问题,我的猜测是Win10系统的终端与JVM虚机存在互优化,JVM执行class文件时,会读到Win10的默认字符集,打印输出的时候,无论-Dfile.encoding设置为什么字符集,都会转化为GBK输出。Cygwin64 Terminal修改字符集为utf8后,JVM执行class文件时,仍然读到Win10的默认字符集是GBK,因此无论-Dfile.encoding设置为什么字符集,输出都是GBK,而此时Cygwin64 Terminal只能显示UTF8,因此产生了乱码。
对于这两个遗留问题,不好验证,需要一台默认字符集是utf8的win电脑,或者把win10的系统字符集修改为utf8.暂时先遗留在这里吧。
下面的参考博客,写的都不错,可以作为参考。
https://www.qqxiuzi.cn/bianma/zifuji.php
https://www.qqxiuzi.cn/bianma/Unicode-UTF.php
https://blog.csdn.net/PacosonSWJTU/article/details/79118928
https://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/