回顾昨天的内容
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
异常处理
try
except
一定要在
except
之后写一些提示或者处理的内容
try
:
'''可能会出现异常的代码'''
except
ValueError:
'''打印一些提示或者处理的内容'''
except
NameError:
'''...'''
# except Exception as e:
# '''打印e'''
else
:
'''try中的代码正常执行了'''
finally
:
'''无论错误是否发生,都会执行这段代码,用来做一些收尾工作'''
|
一、re模块
re模块 可以读懂 你写的正则表达式
根据你写的表达式去执行任务
一般网站注册手机,会验证手机号是否有效 根据手机号码一共11位并且是只以13、14、15、18开头的数字这些特点,我们用python写了如下代码:
 判断手机号码是否合法1
判断手机号码是否合法1
上面的代码太冗长了
使用正则
假如有一文件
一段文字
需要匹配出手机号码,用if就不好处理了,需要使用正则
正则表达式是做什么的?
正则表达式 字符串的操作
使用一些规则来检测字符串是否符合我的要求 —— 表单验证
从一段字符串中找到符合我要求的内容 —— 爬虫
网页的内容,最终也是字符串
正则表达式,是专属字符串操作规则
正则表达式不仅在python领域,在整个编程届都占有举足轻重的地位。
正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则。
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式
在线测试工具 http://tool.chinaz.com/regex/
这个是最好的正则表达式工具,正则可以随时匹配出结果
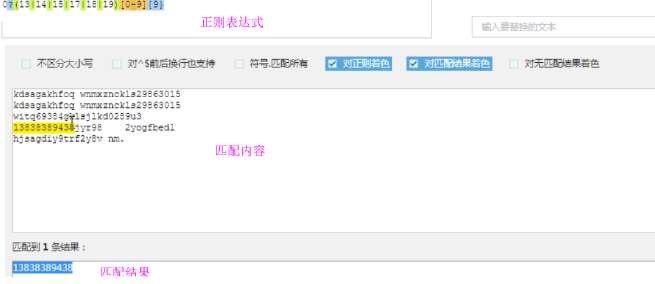
缺点:
如果只会用这个工具,而不会自己写的话,就不行了。
主要是自己写,不要太依赖它。
匹配一个字符串a
|
1
2
3
4
|
import
re
str1
=
'a'
ret
=
re.match(
'a'
,str1)
print
(ret)
|
执行输出:
<_sre.SRE_Match object; span=(0, 1), match='a'>
结果是一个匹配对象,请注意结尾的match='a' 表示匹配出了a
如果没有匹配上,结果为None
打印匹配结果,使用group()方法查看
|
1
2
3
4
|
import
re
str1
=
'a'
ret
=
re.match(
'a'
,str1)
print
(ret.group())
|
执行输出: a
如果没有匹配上,直接使用group()方法,会报错
AttributeError: 'NoneType' object has no attribute 'group'
所以得配合if判断才行
|
1
2
3
4
|
import
re
str1
=
'a'
ret
=
re.match(
'ab'
,str1)
if
ret:
print
(ret.group())
# 即是匹配不上,也不会报错
|
这种情况,是匹配不上的
|
1
2
3
4
|
import
re
str1
=
'a1'
ret
=
re.match(
'a11'
,str1)
if
ret:
print
(ret.group())
|
结论:
完全相等的字符串都可以匹配上
字符组
字符串用[]表示,它只能匹配一个字符串
|
1
2
3
4
|
字符组 : [字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,比如数字、字母、标点等等。
假如你现在要求一个位置
"只能出现一个数字"
,那么这个位置上的字符只能是
0
、
1
、
2.
..
9
这
10
个数之一。
|
|
1
2
3
4
|
import
re
str1
=
'2'
ret
=
re.match(
'[123abc]'
,str1)
if
ret:
print
(ret.group())
|
执行输出:2
|
1
2
3
4
|
import
re
str1
=
'123'
ret
=
re.match(
'[123abc]'
,str1)
if
ret:
print
(ret.group())
|
执行输出:1
正则 |
待匹配字符 |
匹配 |
说明 |
[0123456789] |
8 |
True |
在一个字符组里枚举合法的所有字符,字符组里的任意一个字符 |
[0123456789] |
a |
False |
由于字符组中没有"a"字符,所以不能匹配 |
[0-9] |
7 |
True |
也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
[A-Z] |
B |
True |
[A-Z]就表示所有的大写字母 |
[0-9a-fA-F] |
e |
True |
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
字符:
红色部分是比较常用的
元字符 |
匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符a或字符b |
| () | 匹配括号内的表达式,也表示一个组 |
| [...] | 匹配字符组中的字符 |
| [^...] | 匹配除了字符组中字符的所有字符 |
量词:
量词 |
用法说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
字符在正则表达式中有特殊意义的
[9-0] 是不可以的
|
1
2
3
4
|
import
re
str1
=
'123'
ret
=
re.match(
'[9-0]'
,str1)
if
ret:
print
(ret.group())
|
执行报错:
sre_constants.error: bad character range 9-0 at position 1
为啥呢?
re模块搜查单字符,其字符集合必须按其ASCII值(或者说编码值)由小到大排列,否则报错: error: bad character range
[5-9] 这种是可以的
[5.5-9] 这种是不可以的,不允许有小数点
匹配3位数字
|
1
2
3
4
|
import
re
str1
=
'123'
ret
=
re.match(
'[1-9][1-9][1-9]'
,str1)
if
ret:
print
(ret.group())
|
执行输出:123
第二种写法:
|
1
2
3
4
|
import
re
str1
=
'123'
ret
=
re.match(
'[1-9]{3}'
,str1)
# {3}表示重复3次
if
ret:
print
(ret.group())
|
执行输出:123
第三种写法:
|
1
2
3
4
|
import
re
str1
=
'123'
ret
=
re.match(
'\d{3}'
,str1)
# \d表示匹配数字
if
ret:
print
(ret.group())
|
执行输出:123
匹配大写
|
1
2
3
4
|
import
re
str1
=
'AUE'
ret
=
re.match(
'[A-Z]{3}'
,str1)
if
ret:
print
(ret.group())
|
执行输出:AUE
匹配大小写
|
1
2
3
4
|
import
re
str1
=
'ilikeSHE'
ret
=
re.match(
'[A-Za-z]{8}'
,str1)
if
ret:
print
(ret.group())
|
执行输出:ilikeSHE
不能写[A-z],因为A-z之间的ASCII码,不是连续的。中间还有特殊字符,比如[
[0-9a-fA-F] 表示匹配十六进制
总结:
字符组 字符组代表一个字符位置上可以出现的所有内容
范围 :
根据asc码来的,范围必须是从小到大的指向
一个字符组中可以有多个范围
. ^ $
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 海. | 海燕海娇海东 | 海燕海娇海东 | 匹配所有"海."的字符 |
| ^海. | 海燕海娇海东 | 海燕 | 只从开头匹配"海." |
| 海.$ | 海燕海娇海东 | 海东 | 只匹配结尾的"海.$" |
* + ? { }
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.? | 李杰和李莲英和李二棍子 | 李杰 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符 |
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 | *表示重复零次或多次,即匹配"李"后面0或多个任意字符 |
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 | +表示重复一次或多次,即只匹配"李"后面1个或多个任意字符 |
| 李.{1,2} | 李杰和李莲英和李二棍子 | 李杰和 |
{1,2}匹配1到2次 |
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.*? | 李杰和李莲英和李二棍子 | 李 李 李 |
惰性匹配 |
正则表示式,不能写在后面。比如海^.
它只能出现在开始位置不能在中间或者后面位置
.*表示匹配所有
惰性匹配
|
1
2
3
4
|
import
re
str1
=
'李杰和李莲英和李二棍子'
ret
=
re.match(
'李.{2,}?'
,str1)
# 最多2次
if
ret:
print
(ret.group())
|
执行输出:李杰和
匹配多个数字
|
1
2
3
4
|
import
re
str1
=
'22675853324354'
ret
=
re.match(
'\d+'
,str1)
if
ret:
print
(ret.group())
|
执行输出:22675853324354
匹配11位以上,不能低于11位
|
1
2
3
4
|
import
re
str1
=
'12345678910111'
ret
=
re.match(
'\d{11,}'
,str1)
if
ret:
print
(ret.group())
|
执行输出:12345678910111
匹配11~15位,如果符合15位,优先显示15
|
1
2
3
4
|
import
re
str1
=
'12345678910111213'
ret
=
re.match(
'\d{11,15}'
,str1)
if
ret:
print
(ret.group())
|
执行输出:123456789101112
匹配所有数字
|
1
2
3
4
|
import
re
str1
=
'12345678910111213'
ret
=
re.match(
'\d*'
,str1)
# *表示零次或者更多次
if
ret:
print
(ret.group())
|
执行输出:12345678910111213
匹配一位数字
|
1
2
3
4
|
import
re
str1
=
'1233335446575865'
ret
=
re.match(
'\d?'
,str1)
# ? 重复零次或者一次
if
ret:
print
(ret.group())
|
执行输出:1
重点:
量词只能约束一个字符组
这里是约束[A-Z]
|
1
2
3
4
|
import
re
str1
=
'2A32345446'
ret
=
re.match(
'\d[A-Z]*'
,str1)
if
ret:
print
(ret.group())
|
执行输出:2A
约束\d和[A-Z]
|
1
2
3
4
|
import
re
str1
=
'22323A454W46'
ret
=
re.match(
'\d*[A-Z]*'
,str1)
if
ret:
print
(ret.group())
|
执行输出:22323A
元字符,一般和量词使用
分组 ()与 或 |[^]
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
步骤分析:
1.匹配非零的,使用 [1-9]
2.匹配15位数字,使用 [1-9]\d{14}
3.匹配18位数字,使用 [1-9]\d{16}[0-9x],优化成 [1-9]\d{16}[\dx]
4.将15位和18位的,一并判断,使用| ,规则为 [1-9]\d{16}[\dx]|[1-9]\d{14}
如果两个正则表达式之间用"或"连接,且有一部分正则规则相同,
那么一定要把规则长的放在前面
测试号码:
|
1
2
3
4
|
import
re
str1
=
'110101198001017'
ret
=
re.match(
'[1-9]\d{16}[\dx]|[1-9]\d{14}'
,str1)
if
ret:
print
(ret.group())
|
执行输出:110101198001017
再测试一个
|
1
2
3
4
|
import
re
str1
=
'11010119800101702x'
ret
=
re.match(
'[1-9]\d{16}[\dx]|[1-9]\d{14}'
,str1)
if
ret:
print
(ret.group())
|
执行输出:11010119800101702x
分组
|
1
2
3
4
|
import
re
str1
=
'1101011980010172345'
ret
=
re.match(
'[1-9]\d{14}(\d{2}[\dx])?'
,str1)
# 最多匹配18位数字
if
ret:
print
(ret.group())
|
执行输出:110101198001017234
如果对一组正则表达式整体有一个量词约束,就将这一组表达式分成一个组
在组外进行量词约束
转义符 \
在正则表达式中,有很多有特殊意义的是元字符,比如\d和\s等,如果要在正则中匹配正常的"\d"而不是"数字"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\d",字符串中要写成'\\d',那么正则里就要写成"\\\\d",这样就太麻烦了。这个时候我们就用到了r'\d'这个概念,此时的正则是r'\\d'就可以了。
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| \d | \d | False | 因为在正则表达式中\是有特殊意义的字符,所以要匹配\d本身,用表达式\d无法匹配 |
| \\d | \d | True | 转义\之后变成\\,即可匹配 |
| "\\\\d" | '\\d' | True | 如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次 |
| r'\\d' | r'\d' | True | 在字符串之前加r,让整个字符串不转义 |
匹配\n,需要使用\\n
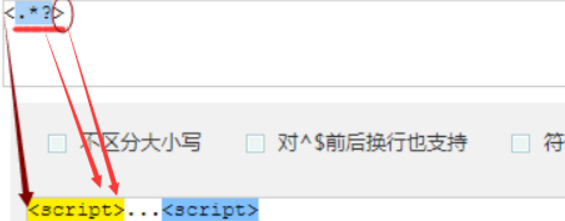
贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| <.*> | <script>...<script> |
<script>...<script> | 默认为贪婪匹配模式,会匹配尽量长的字符串 |
| <.*?> | r'\d' | <script> |
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串 |
几个常用的非贪婪匹配Pattern
|
1
2
3
4
5
|
*
? 重复任意次,但尽可能少重复
+
? 重复
1
次或更多次,但尽可能少重复
?? 重复
0
次或
1
次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
|
.*?的用法
|
1
2
3
4
5
6
7
|
. 是任意字符
*
是取
0
至 无限长度
? 是非贪婪模式。
何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在:
.
*
?x
就是取前面任意长度的字符,直到一个x出现
|

因为它要回到原来很难,所以它尽可能,多匹配一点
匹配多次,直到遇到<停下来
?先匹配后面的。
用的最多的是.*?
取前面任意长度的字符,直到一个xxx出现
|
1
2
3
4
|
import
re
str1
=
'dfhyyufddxxx123'
ret
=
re.match(
'.*?xxx'
,str1)
if
ret:
print
(ret.group())
|
执行输出:dfhyyufddxxx
re模块下的常用方法
findall
把所有匹配到的字符放到以列表中的元素返回
findall接收两个参数 : 正则表达式 要匹配的字符串
一个列表数据类型的返回值:所有和这条正则匹配的结果
匹配a
|
1
2
3
|
import
re
ret
=
re.findall(
'a'
,
'eva egon yuan'
)
print
(ret)
|
执行输出:
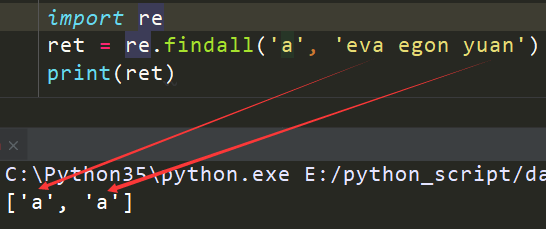
返回所有满足匹配条件的结果,放在列表里
如果没有找到匹配结果,返回空列表[]
匹配所有数字
|
1
2
3
|
import
re
ret
=
re.findall(
'\d+'
,
'fdsfe5hy5j2436sfd'
)
print
(ret)
|
执行输出:['5', '5', '2436']
有一个文件a.txt,内容如下:
|
1
2
3
4
|
fefsfsd13838383838
f138383838389
13838383840ffsfsd
fdsa13838383841et413838383842
|
需要找出所有的手机号码,使用正则表达式
分析:
首先手机号码段是13|14|15|16|17|18|19
使用正则 1[3-9]表示
匹配11位手机号,使用1[3-9]\d{9} 花括号的数字为啥是9呢?
比如13占用了2位,加上9,正好就是11位。
代码如下:
|
1
2
3
4
5
6
7
8
9
|
import
re<br>with
open
(
'a.txt'
,encoding
=
'utf-8'
) as f:
li
=
[]
# 空列表
for
i
in
f:
i
=
i.strip()
#print(i)
ret
=
re.findall(
'1[3-9]\d{9}'
,i)
# 匹配每一行的内容
#print(ret)
li.extend(ret)
# 扩展列表。由于findall的返回结果是列表,可以直接使用extend
print
(li)
# 打印结果
|
执行输出:
['13838383838', '13838383838', '13838383840', '13838383841', '13838383842']
search
匹配包含
从整个文本中去搜索,结果只会返回一次。
如果有多个结果,只会返回第一个结果
搜索字符串b是否存在
|
1
2
3
|
import
re
ret
=
re.search(
'b'
,
'eva egon yuan'
)
print
(ret)
|
执行输出:None
搜索字符串a是否存在
|
1
2
3
|
import
re
ret
=
re.search(
'a'
,
'eva egon yuan'
)
if
ret:
print
(ret.group())
# 从结果对象中获取结果
|
执行输出:a
总结:
如果匹配到了,返回一个结果对象。否则,返回一个None
使用search的group方法,必须要if判断,否则为None时,就会报错。
search和findall的区别:
1. search找到一个就返回,findall是找所有
2. findall是直接返回一个结果的列表,search返回一个对象
match
从头开始匹配
|
1
2
3
|
import
re
ret
=
re.match(
'a'
,
'eva egon yuan'
)
if
ret:
print
(ret.group())
|
执行程序,没有返回结果
为什么呢?
match:
1. 意味着在正则表达式中添加了一个^
2. 和search一样 匹配返回结果对象 没匹配到返回None
3. 和search一样 从结果中获取值 仍然用group
split
根据正则表达式切割
|
1
2
|
ret
=
re.split(
'[ab]'
,
'abcd'
)
# 先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割
print
(ret)
|
执行输出:['', '', 'cd']
sub
匹配字符并替换
将数字替换为H
|
1
2
3
|
import
re
ret
=
re.sub(
'\d'
,
'H'
,
'eva3egon4yuan4'
,
1
)
#将数字替换成'H',参数1表示只替换1个
print
(ret)
|
执行输出:evaHegon4yuan4
如果最后一个参数不指定,表示替换所有。
subn
统计sub替换次数
|
1
2
3
|
import
re
ret
=
re.subn(
'\d'
,
'H'
,
'eva3egon4yuan4'
)
#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print
(ret)
|
执行输出:('evaHegonHyuanH', 3)
compile
编译一个正则表达式模式,返回一个模式对象
|
1
2
3
4
|
import
re
obj
=
re.
compile
(
'\d{3}'
)
#将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret
=
obj.search(
'abc123eeee'
)
#正则表达式对象调用search,参数为待匹配的字符串
print
(ret.group())
|
执行输出:123
正则表达式 -->根据规则匹配字符串
从一个字符串中找到符合规则的字符串 --> python
正则规则 -编译-> python能理解的语言
多次执行,就需要多次编译 浪费时间 re.findall('1[3-9]\d{9}',line)
编译 re.compile('\d{3}')
比如下面的例子:
|
1
2
3
4
5
6
7
|
import
re
obj
=
re.
compile
(
'\d{3}'
)
# 编译 在多次执行同一条正则规则的时候才适用
ret1
=
obj.search(
'abc123eeee'
)
obj.match(
'abc123efdsffdsfd'
)
ret2
=
obj.findall(
'c123ekufs'
)
print
(ret1.group())
print
(ret2)
|
执行输出:
123
['123']
提前编译正则,可以执行多个方法
编译 在多次执行同一条正则规则的时候才适合使用compile
finditer
返回一个存放匹配结果的迭代器
findall和finditer两者相似,但却有很大区别。
两者都可以获取所有的匹配结果,不同的是一个返回list,一个返回一个MatchObject类型的iterator
|
1
2
3
|
import
re
ret
=
re.finditer(
'\d'
,
'ds3sy4784a'
)
#finditer返回一个存放匹配结果的迭代器
print
(ret)
|
执行输出:
<callable_iterator object at 0x000001A99A96E9E8>
既然是迭代器,就可以使用__next__()方法获取值
|
1
2
3
4
|
import
re
ret
=
re.finditer(
'\d'
,
'ds3sy4784a'
)
#finditer返回一个存放匹配结果的迭代器
for
i
in
ret:
print
(i.group())
|
执行输出:
3
4
7
8
4
finditer适用于结果比较多的情况下,能够有效的节省内存
当分组遇到re模块
findall的优先级查询:
|
1
2
3
4
|
import
re
ret
=
re.findall(
'www\.(baidu|oldboy).com'
,
'www.oldboy.com'
)
ret2
=
re.findall(
'www\.(baidu|oldboy).com'
,
'www.baidu.com'
)
print
(ret,ret2)
|
执行输出:
['oldboy'] ['baidu']
结论:
findall会优先显示组内匹配到的内容
如果想取消分组优先效果,在组内开始的时候加上?:
|
1
2
3
4
|
import
re
ret
=
re.findall(
'www\.(baidu|oldboy).com'
,
'www.oldboy.com'
)
ret2
=
re.findall(
'www\.(?:baidu|oldboy).com'
,
'www.baidu.com'
)
# 取消分组优先
print
(ret,ret2)
|
执行输出:['oldboy'] ['www.baidu.com']
split的优先级查询
|
1
2
3
|
import
re
ret
=
re.split(
"\d+"
,
"eva3egon4yuan"
)
# 以数字为分割点
print
(ret)
|
执行输出:
['eva', 'egon', 'yuan']
从结果中来看,分割的数字消失了。
|
1
2
3
|
import
re
ret
=
re.split(
"(\d+)"
,
"eva3egon4yuan"
)
print
(ret)
|
执行输出:
['eva', '3', 'egon', '4', 'yuan']
从结果中来看,分割的数字会留下来
在匹配部分加上()之后所切出的结果是不同的,
没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
这个在某些需要保留匹配部分的使用过程是非常重要的。
结论:
split分割一个字符串,默认被匹配到的分隔符不会出现在结果列表中,
如果将匹配的正则放到组内,就会将分隔符放到结果列表里
综合练习与扩展
1、匹配标签
分组命名 和 search遇到分组
标签 .html 网页文件 标签文件
|
1
2
3
|
import
re
ret
=
re.search(
"<\w+>\w+</\w+>"
,
"<h1>hello</h1>"
)
if
ret:
print
(ret.group())
|
执行输出:
<h1>hello</h1>
如果是这种内容,就不合法了。
|
1
2
3
|
import
re
ret
=
re.search(
"<\w+>\w+</\w+>"
,
"<h1>hello</h2>"
)
if
ret:
print
(ret.group())
|
执行输出:
<h1>hello</h2>
它依然匹配了处理,但是结果不是我想要的。
这个时候,就需要用到分组了。
分组就是用一对圆括号“()”括起来的正则表达式,匹配出的内容就表示一个分组
获取hello
|
1
2
3
|
import
re
ret
=
re.findall(
"<\w+>(\w+)</\w+>"
,
"<h1>hello</h2>"
)
if
ret:
print
(ret)
|
执行输出:['hello']
这种情况下,不通过匹配周围的,无法匹配到想要的内容
分组的意义
1.对一组正则规则进行量词约束
2.从一整条正则规则匹配的结果中优先显示组内的内容
分组的命名
命名分组就是给具有默认分组编号的组另外再给一个别名。命名分组的语法格式如下:
|
1
|
(?P<name>正则表达式)
#name是一个合法的标识符
|
举例:
|
1
2
3
|
import
re
ret
=
re.search(
"<(?P<tag>\w+)>\w+</(?P=tag)>"
,
"<h1>hello</h2>"
)<br>
print
(ret)
if
ret:
print
(ret.group())
|
执行程序,输出None
因为(?P<tag>\w+)匹配的是h1,而</(?P=tag)>匹配的是h2
结果不相等,所以ret的结果为None
将h2改为h1
|
1
2
3
|
import
re
ret
=
re.search(
"<(?P<tag>\w+)>\w+</(?P=tag)>"
,
"<h1>hello</h1>"
)
if
ret:
print
(ret.group())
# search中没有分组优先的概念
|
执行输出:<h1>hello</h1>
|
1
2
3
4
5
6
|
import
re
ret
=
re.search(r
"<(\w+)>(\w+)</\1>"
,
"<h1>hello</h1>"
)
print
(ret.group())
#结果 : <h1>hello</h1>
print
(ret.group(
0
))
#结果 :<h1>hello</h1>
print
(ret.group(
1
))
#结果 :h1
print
(ret.group(
2
))
#结果 :hello
|
执行输出:
<h1>hello</h1>
<h1>hello</h1>
h1
hello
如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
获取的匹配结果可以直接用group(序号)拿到对应的值
0是完整的,1是第一组的,2是后面一组的。
今日作业:
|
1
2
|
实现能计算类似
1
-
2
*
( (
60
-
30
+
(
-
40
/
5
)
*
(
9
-
2
*
5
/
3
+
7
/
3
*
99
/
4
*
2998
+
10
*
568
/
14
))
-
(
-
4
*
3
)
/
(
16
-
3
*
2
) )等类似公式的计算器程序
|
思路讲解:
计算一个字符串数据类型的表达式 : 整数 小数 加减乘除 小括号
不准用eval函数
将字符串中所有的空格都去掉
使用正则表达式 先匹配最内层的小括号
使用正则表达式 匹配最内层括号中最先出现的第一个乘法或者除法的(原子)表达式
计算这个原子表达式 比如'2*3' 或者 '4/50'
将乘除法的结果填回表达式中
再计算下一个出现的乘除法,直到这个小括号中再也没有乘除
计算加减法,替换
这个小括号中的所有内容都计算成一个结果
如果实在搞不定呢?
从小的功能开始
先最简单的 a+b c*d
再计算没有括号的表达式 a+c*b
再算 a-b+c*d/e
再算有一个括号的
再算有两个括号并排的
再算有两个括号嵌套的
...
老师的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
import
re
def
cal(exp):
if
'*'
in
exp:
a,b
=
exp.split(
'*'
)
return
str
(
float
(a)
*
float
(b))
elif
'/'
in
exp:
a, b
=
exp.split(
'/'
)
return
str
(
float
(a)
/
float
(b))
def
format
(exp):
exp
=
exp.replace(
'++'
,
"+"
)
exp
=
exp.replace(
'-+'
,
"-"
)
exp
=
exp.replace(
'+-'
,
"-"
)
exp
=
exp.replace(
'--'
,
"+"
)
return
exp
def
dealwith(no_bracket_exp):
# 匹配乘除法
while
True
:
mul_div
=
re.search(
'\d+(\.?\d+)?[*/]-?\d+(\.?\d+)?'
, no_bracket_exp)
if
mul_div:
exp
=
mul_div.group()
result
=
cal(exp)
no_bracket_exp
=
no_bracket_exp.replace(exp, result,
1
)
# (-8)
else
:
break
no_bracket_exp
=
format
(no_bracket_exp)
# 计算加减法
lst
=
re.findall(r
'[-+]?\d+(?:\.\d+)?'
, no_bracket_exp)
res
=
str
(
sum
([
float
(i)
for
i
in
lst]))
return
res
# 返回一个计算完毕的字符串数据类型的 数字
def
remove_bracket(s):
s
=
s.replace(
' '
, '')
# 去掉空格
while
True
:
ret
=
re.search(r
'\([^()]+\)'
, s)
# 匹配最内层的括号
if
ret:
# 能匹配到括号 就先处理括号内的加减乘除
no_bracket_exp
=
ret.group()
# 拿到括号中的表达式
ret
=
dealwith(no_bracket_exp)
# 把括号中的表达式交给的dealwith
s
=
s.replace(no_bracket_exp, ret,
1
)
else
:
# 不能匹配到括号 就字节处理加减乘除
ret
=
dealwith(s)
# 把表达式交给的dealwith
return
ret
s
=
'1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )'
print
(remove_bracket(s))
|
执行输出:
2776672.6952380957