Sqoop增量数据导入
实验1:增量数据导入3条。
导入初始数据:
[root@bigdata tempfolder]# sqoop import --connect jdbc:mysql://localhost:3306/sqooptest --username root --password admin --table bigdata
20/04/13 17:36:49 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`class_id`), MAX(`class_id`) FROM `bigdata` 20/04/13 17:36:49 INFO db.IntegerSplitter: Split size: 1; Num splits: 4 from: 1 to: 7 20/04/13 17:36:49 INFO mapreduce.JobSubmitter: number of splits:4
20/04/13 17:37:11 INFO mapreduce.ImportJobBase: Transferred 908.5771 KB in 24.5775 seconds (36.9678 KB/sec)
20/04/13 17:37:11 INFO mapreduce.ImportJobBase: Retrieved 7 records.
结果:
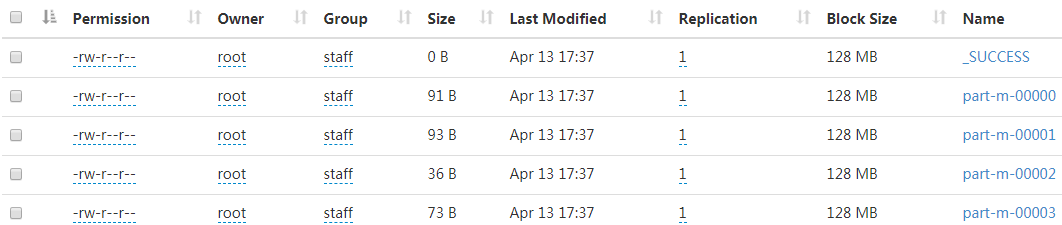
在表中插入3条数据。
导入增量
[root@bigdata tempfolder]# sqoop import --connect jdbc:mysql://localhost:3306/sqooptest --username root --password admin
--table bigdata --check-column class_id --incremental append --last-value 7
导入:
20/04/13 17:49:29 INFO mapreduce.ImportJobBase: Transferred 672.2295 KB in 22.4879 seconds (29.8929 KB/sec) 20/04/13 17:49:29 INFO mapreduce.ImportJobBase: Retrieved 3 records. 20/04/13 17:49:29 INFO util.AppendUtils: Appending to directory bigdata 20/04/13 17:49:29 INFO util.AppendUtils: Using found partition 4 20/04/13 17:49:29 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments: 20/04/13 17:49:29 INFO tool.ImportTool: --incremental append 20/04/13 17:49:29 INFO tool.ImportTool: --check-column class_id 20/04/13 17:49:29 INFO tool.ImportTool: --last-value 10 20/04/13 17:49:29 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')
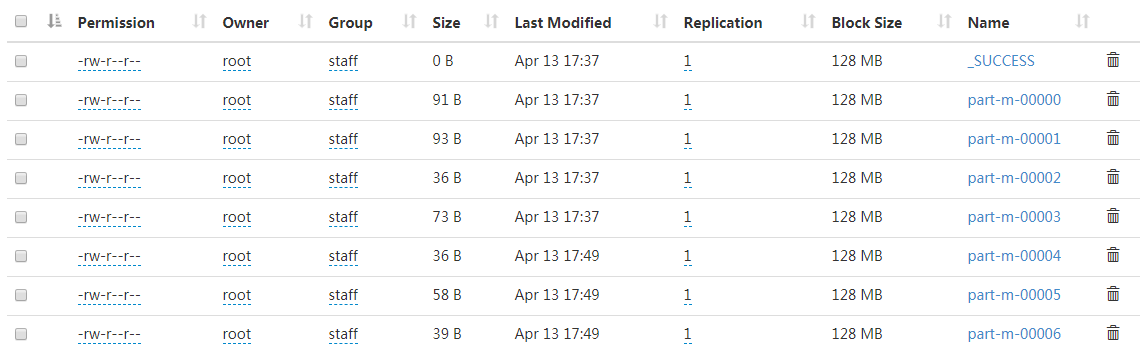
查看数据:虽然默认map是4,但是新增数据太少了,只有3行,所以只生成了3个文件。
ata tempfolder]# hdfs dfs -cat /user/root/bigdata/part-m-00004 8,9,hive,2020-04-14 06:39:44.0,Mars [root@bigdata tempfolder]# hdfs dfs -cat /user/root/bigdata/part-m-00005 9,10,Hive example:log analysis,2020-04-14 06:39:44.0,Mars [root@bigdata tempfolder]# hdfs dfs -cat /user/root/bigdata/part-m-00006 10,10,hbase,2020-04-14 06:39:44.0,Mars
******额外补充*******
如果是按照视频中 -m 1(1个map)来操作的话,就是多1个文件,里面是新增的3行数据。


*******额外补充*******
实验2:在新增一条数据:我们不加 --last-value 1, 看看会有什么结果?
[root@bigdata tempfolder]# sqoop import --connect jdbc:mysql://localhost:3306/sqooptest --username root --password admin --table bigdata
--check-column class_id --incremental append -m 1
20/04/13 18:08:25 INFO mapreduce.ImportJobBase: Transferred 218.0459 KB in 22.4301 seconds (9.7211 KB/sec) 20/04/13 18:08:25 INFO mapreduce.ImportJobBase: Retrieved 11 records. 20/04/13 18:08:25 INFO util.AppendUtils: Appending to directory bigdata 20/04/13 18:08:25 INFO util.AppendUtils: Using found partition 7 20/04/13 18:08:25 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments: 20/04/13 18:08:25 INFO tool.ImportTool: --incremental append 20/04/13 18:08:25 INFO tool.ImportTool: --check-column class_id 20/04/13 18:08:25 INFO tool.ImportTool: --last-value 11 20/04/13 18:08:25 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')

结果就是,系统把所有11条数据又重新全部导入了进来。
所以必须要加 --last-value x , 否则数据冗余。
[root@bigdata tempfolder]# hdfs dfs -cat /user/root/bigdata/part-m-00007 1,8,bigdata intro.,2020-04-13 11:26:45.0,Mars 2,8,hadoop intro.,2020-04-13 11:26:45.0,Mars 3,8,hadoop components,2020-04-13 11:26:45.0,Mars 4,8,hadoop arch.,2020-04-13 11:26:45.0,Mars 5,9,hdfs,2020-04-13 11:26:45.0,Mars 6,9,yarn,2020-04-13 11:26:45.0,Mars 7,9,sqoop,2020-04-13 11:26:45.0,Mars 8,9,hive,2020-04-14 06:39:44.0,Mars 9,10,Hive example:log analysis,2020-04-14 06:39:44.0,Mars 10,10,hbase,2020-04-14 06:39:44.0,Mars 11,11,kylin,2020-04-14 07:07:03.0,Mars
实验3:
再新增一条数据,