import requests
import random
# 基本示例
def use_requset_get():
url = 'http://httpbin.org/get'
response = requests.get(url)
print(response.text)
# 响应
print(type(response.headers),response.headers)
print(type(response.cookies), response.cookies)
print(type(response.url), response.url)
# 传参
def use_requset_get_data():
url = 'http://httpbin.org/get'
data = {
'name':"魏振东",
'age':"20"
}
response = requests.get(url=url,params=data)
print(response.text)
# 获取二进制文件并存储
def use_requset_get_by_byte():
url = 'https://github.com/favicon.ico'
response = requests.get(url=url)
# 乱码
# print(response.text)
# 二进制文件
print(response.content)
with open('githublogo.ico','wb') as f:
f.write(response.content)
# 添加请求头
def use_requset_get_headers():
url = 'https://nba.hupu.com/stats/players'
# 添加多个请求头
headers_list = [
# 谷歌
{"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"},
# uc
{"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36"},
# 火狐
{"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0"},
]
# 随机选择一个
headers = random.choice(headers_list)
response = requests.get(url, headers)
print(response.text)
def use_requset_get_cookie():
url = 'https://www.baidu.com/'
response = requests.get(url)
print(type(response.cookies), response.cookies)
for k,v in response.cookies.items():
print("key = {0} , value = {1}".format(k,v))
# 添加代理
def use_requset_get_proxy():
url = 'https://www.baidu.com/'
# 添加多个请求头
user_agent_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
# uc
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36",
# 火狐
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0",
]
headers= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
}
headers['User-Agent'] = random.choice(user_agent_list)
proxy_list = [
{"http": "121.40.108.76:80"},
{"http": "218.249.45.162:35586"},
{"http": "218.27.136.169:8085"},
]
# 随机选择一个代理,headers也可进行随机选择
proxy = random.choice(proxy_list)
r = requests.post(url, headers=headers, proxies=proxy, )
print(r.text)
if __name__ == '__main__':
use_requset_get()
use_requset_get_data()
use_requset_get_by_byte()
use_requset_get_headers()
use_requset_get_cookie()
use_requset_get_proxy()
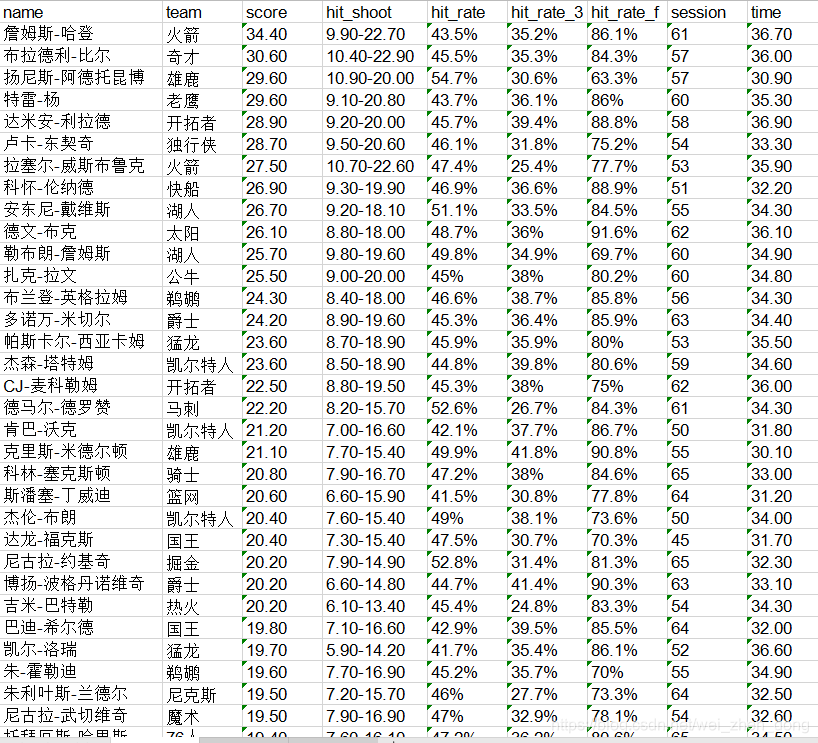
爬取虎扑体育NBA球星数据
import requests
from lxml import etree
from opdata.opexcel import Operatingexcel
# 小例子,获取虎扑体育NBA球星数据
def use_requsert_dome():
url = 'https://nba.hupu.com/stats/players'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
}
response = requests.get(url,headers)
if response.status_code == 200:
return response.text
else:
return None
def text_to_dic(text):
dict = {}
html = etree.HTML(text)
pags = html.xpath('//*[@id="data_js"]/div[4]/div/table/tbody')
for i in pags:
name = i.xpath('//tr/td[2]/a/text()')
team = i.xpath('//tr/td[3]/a/text()')
score = i.xpath('//tr/td[4]/text()')
hit_shoot = i.xpath('//tr/td[5]/text()')
hit_rate = i.xpath('//tr/td[6]/text()')
hit_rate_3 = i.xpath('//tr/td[8]/text()')
hit_rate_f = i.xpath('//tr/td[10]/text()')
session = i.xpath('//tr/td[11]/text()')
time = i.xpath('//tr/td[12]/text()')
dict["name"]=name
dict["team"] = team
dict["score"] = score[1:]
dict["hit_shoot"] = hit_shoot[1:]
dict["hit_rate"] = hit_rate[1:]
dict["hit_rate_3"] = hit_rate_3[1:]
dict["hit_rate_f"] = hit_rate_f[1:]
dict["session"] = session[1:]
dict["time"] = time[1:]
return dict
if __name__ == '__main__':
text = use_requsert_dome()
if text != None:
dict = text_to_dic(text)
ol = Operatingexcel()
ol.set_excel_dic(dict,"data\csdn_data.xlsx",0,0)