(1)分布式锁和分布式事务的区别
1.分布式锁是在集群环境下,用来控制不同机器对全局共享资源的访问。
2.分布式事务是在集群环境下,用来保证全局事务的一致性,保证多个数据库的数据整体上能正确的从一个一致性状态转到另一个一致性状态。
(2)分布式锁应用场景
在我们的某个jvm应用程序中,如果需要对某个共享变量进行多线程同步访问,可以使用java多线程的同步工具,例如ReentrantLock、Synchronized等等。但是当我们的系统由单机部署演化成为分布式集群系统后,在不同机器上原来单机的并发控制锁策略就会失效了,这时就需要引入分布式锁。
举个简单的例子,比如某个外卖骑士每天需要购买一份保险,某天在购买保险时,这个骑士多次点击了买保险的按钮,前端没有做控制,导致同时向服务器发送了多个买保险请求,那这个时候就会导致骑士多次购买保险,为了解决这个问题,我们可以使用分布式锁,保证在某个时间段内,只能有一台机器执行买保险操作,这时就能保障骑士不会多次购买保险。分布式锁主要有三种实现方式:
- 基于数据库实现
- 基于redis实现
- 基于ZooKeeper实现
(3)分布式锁实现方式
1.基于数据库实现
我们可以通过数据库表来实现分布式锁,表结构如下: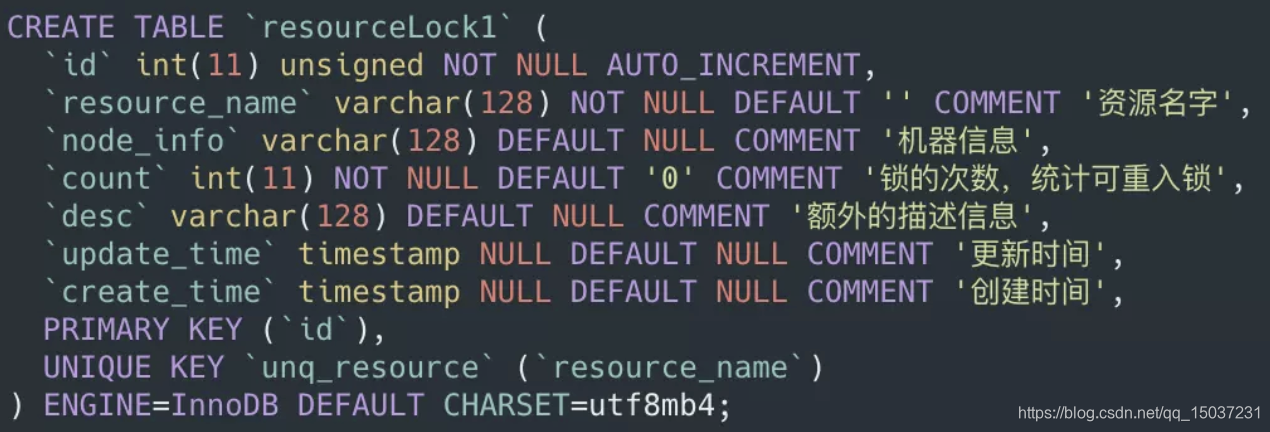
表中的每一条记录就代表一个锁,当我们需要获取锁时就去数据库中查询是否有该共享资源的记录。
(1)如果有则获取其中的node_info,与自己的机器信息进行比较,如果发现是自己已经获取过的锁,那直接使用共享资源,将count数加1,在使用完数据后将count数减1,当count数为0时将记录删除掉。否则就返回错误信息,提示已经有人获取了锁。
(2)如果获取不到就建立一条记录,那就自己建立一条记录,并记录下自己的机器信息,然后使用共享资源。
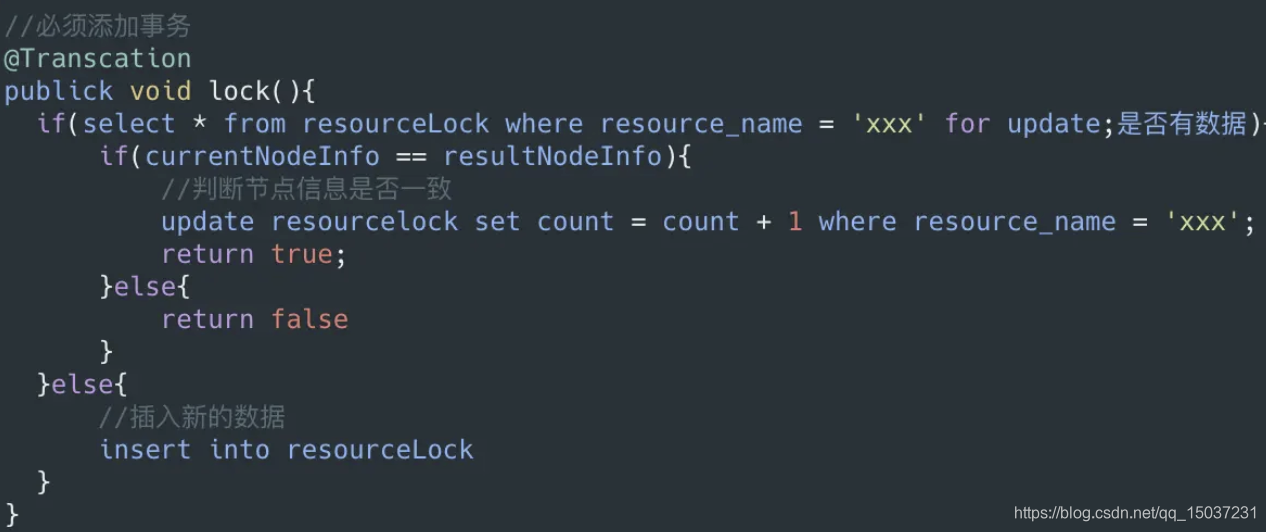
上面其实就是利用数据库实现锁的简单方式。这种方式存在比较严重的问题:1.数据库机器可能存在单点、2.没有超时时间,数据库宕掉后可能导致无法获取锁、3.数据库是磁盘文件,获取锁的时间和性能并不好。
2.基于redis实现
基于redis的分布式锁,主要依赖于redis的几个命令:
- setnx():set if not exists,其主要有两个参数 setnx(key, value)。该方法是原子的,如果 key 不存在,则设置当前 key 成功,返回 1;如果当前 key 已经存在,则设置当前 key 失败,返回 0。
- expire():expire 设置过期时间,要注意的是 setnx 命令不能设置 key 的超时时间,只能通过 expire() 来对 key 设置。
使用步骤:
1、setnx(lockkey, 1) 如果返回 0,则获取锁失败;如果返回 1,则说明获取锁成功。
2、expire() 命令对 lockkey 设置超时时间,为的是避免死锁。
3、执行完业务代码后,可以通过 delete 命令删除 key。
使用问题:
上面的使用方式是能满足我们大部分的业务需求的,但是在某些极端的情况下,还是会存在问题。
- 问题: 当节点A执行完setnx后,还没来得及执行expire,那么会导致其他节点一直无法获取锁。
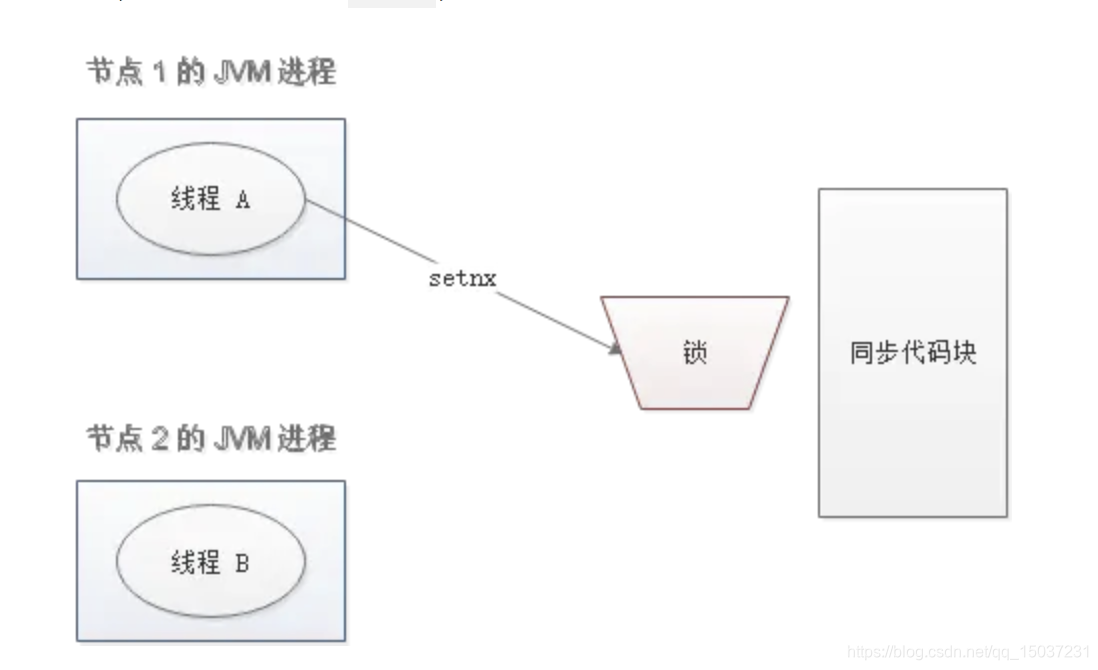
解决方案: 使用set命令代替setnx和expire。
// NX表示:key不存在就返回true,存在就返回false
// PX表示:指定的过期时间
SET anyLock value NX PX
- 问题: 节点A获取了锁,并设置了30秒的过期时间,但是由于某些原因业务代码执行了很久(超过了30秒),delete操作还没执行。这时因为节点A获取的锁过期了,节点B获取了锁,而节点A执行了delete操作,释放了节点B的锁。
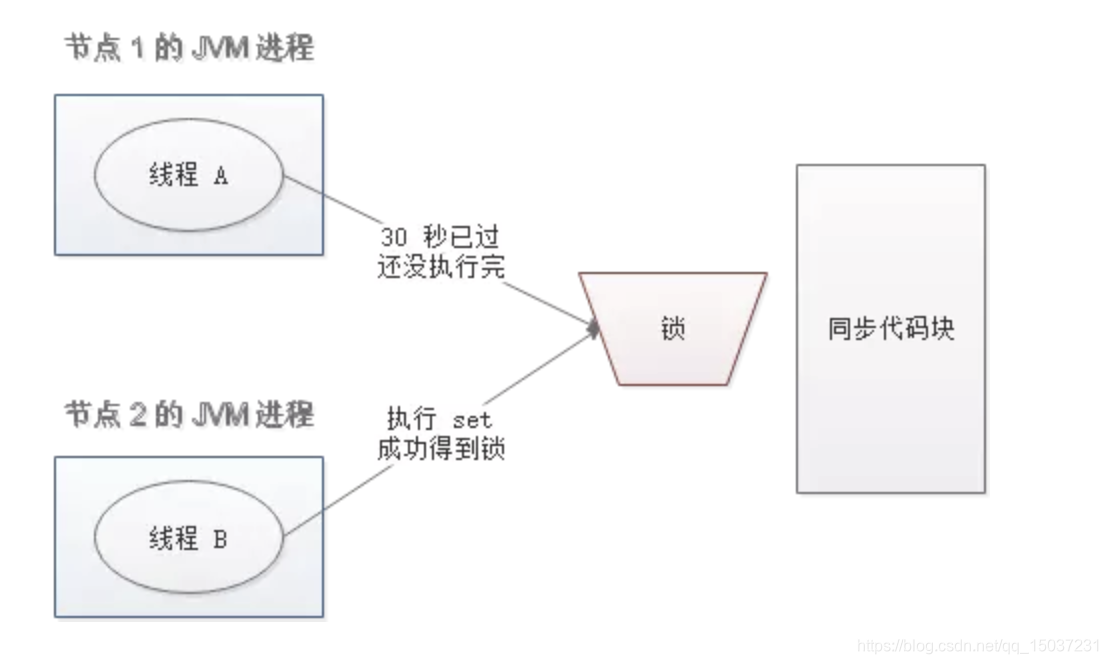
解决方案: 在通过delete操作释放锁之前判断当前的锁是不是自己加的。
当然我们也可以使用RedLock,RedLock是redis实现的分布式锁算法(RedLock),可以有效防止单点故障 。另外还有基于Zookeeper的实现,对于Zookeeper我不咋懂,所以这里就不写了。

