1.需求分析:
1、分析个锤子
2、需求:拿到 电影名、电影封面图片、演员、类型、地区、语言、导演 、上映日期、片长、评分、电影简介、下载链接等
2.源码实现:
import requests
from lxml import etree
from requests.adapters import HTTPAdapter
import time
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"}
zongshu = 1
yeshu = 0
def to_get_url(host, page_num):
global zongshu
global yeshu
yeshu = page_num
hhh_host = "http://www.y80s.com"
s = requests.Session()
s.mount(host, HTTPAdapter(max_retries=10)) # 重连三次
res = s.get(host, headers=header, timeout=10) # 5s超时
res.encoding = "utf-8"
html = etree.HTML(res.text)
print(host, end="---")
print(str(res.status_code), end="---" + str(zongshu) + "\n")
if res.status_code != 200:
return
urls = html.xpath('//ul[@class="me1 clearfix"]/li/a/@href')
titles = html.xpath('//ul[@class="me1 clearfix"]/li/a/@title')
j = 0
mp4_list = []
info_all_list = []
try:
file = open(r"C:\Users\Administrator\Desktop\movie\80s\all_v3.txt", "at", encoding="utf-8")
for url in urls:
url = hhh_host + url
res2 = s.get(url, headers=header, timeout=10)
html2 = etree.HTML(res2.text)
print(url+"---"+str(res2.status_code))
try:
mp4 = html2.xpath('//span[@class="xunlei dlbutton3"]/a/@href')[0].strip() # 获取下载链接
mp4_list.append(mp4)
img = html2.xpath('//div[@class="img"]/img/@src')[0].strip()
info = html2.xpath('//div[@class="clearfix"]/span/a/text()') # 获取演员表
release_date = html2.xpath('//div[@class="clearfix"]/span/text()')[-3:-2][0].strip() # 获取上映时间
time_long = html2.xpath('//div[@class="clearfix"]/span/text()')[-2:-1][0].strip() # 电影时长
score = html2.xpath('//div[@style="float:left; margin-right:10px;"]/text()')[1].strip() # 电影评分
context = html2.xpath('//span[@id="movie_content"]/text()')[0] # 电影简介
except Exception:
continue
info_all = ""
for cc in info:
info_all += cc + "&"
info_all_list.append(info_all)
try:
file.write(url + " | " + titles[j] + " | " + mp4 + " | " + img + " | " + info_all_list[j]
+ " | " + score + " | " + release_date + " | " + time_long + " | " + context + "\n")
except Exception:
pass
finally:
file.close()
print(str(page_num)+"=="+str(j)+"==="+mp4+"---"+release_date+"---"+info_all+"----"+score)
j += 1
res2.close()
except Exception:
if yeshu > page_num: # 出现回滚状态
return
time.sleep(3)
if len(mp4_list) > 18:
pass
else:
if yeshu == page_num:
zongshu += 1
if zongshu >= 3:
# to_get_url(host, page_num+1)
zongshu = 1
yeshu = 0
return
else:
to_get_url(host, page_num)
finally:
s.close()
def main(start, end):
num = start
try:
for i in range(start, end + 1):
if i == 1:
host = "http://www.y80s.com/movie/list"
else:
host = "http://www.y80s.com/movie/list/-----p{}".format(i)
to_get_url(host, i)
num = i
except Exception:
main(num, 761)
# host = "http://www.y80s.com/movie/list"
# to_get_url(host, start)
if __name__ == "__main__":
main(1, 761) #
3.关于代码:
1.保存的信息会写入到桌面的movie文件下的80s文件下的all_v3.txt文件中,注意路径的用户名修改就行了。
2.保存txt文件会以 `|` 符号分割,可以粘贴在excel文件中用数据格式分列,注意排除重复数据。
3.关于网络问题:如果网页请求超时会重新加载,程序中设定一页中最多加载3次,可能会保存有重复的数据。
4.关于网络问题2:因为我这里网络不好,所以程序加入机制,一页中如果爬取超过18个电影后网络超市报错就不要剩下的了,直接跳到下一页爬取。
5.关于程序运行报错终止或者程序不跑了:(这个很少报错)处理方法:看控制台输出信息,比如在228页中不跑了,可以手动结束程序,然后在程序的入口main(1,761)中把1改为229,即更改初始启动页数即可,然后再运行程序。
6.关于程序效率:单线程处理。
4.程序效果:
5.数据处理:
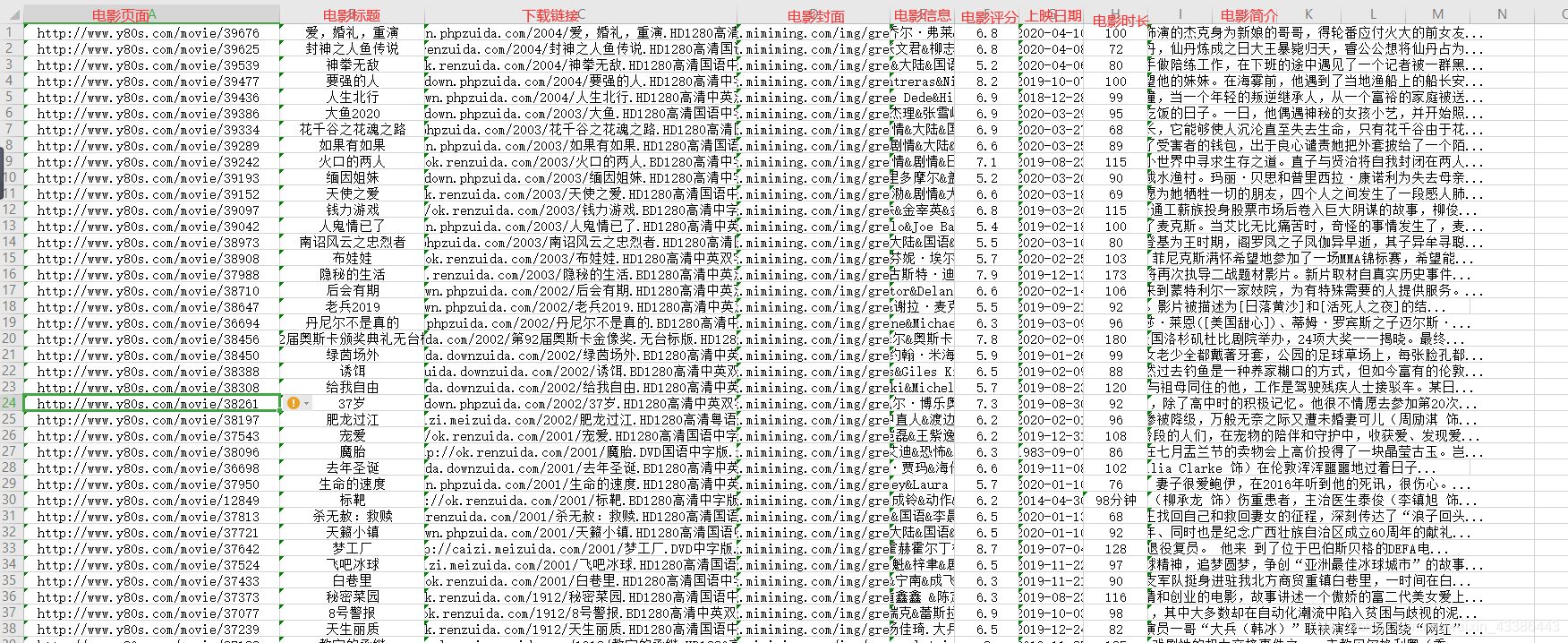
1.新建excel,把txt内容全选粘贴到xlsx中:
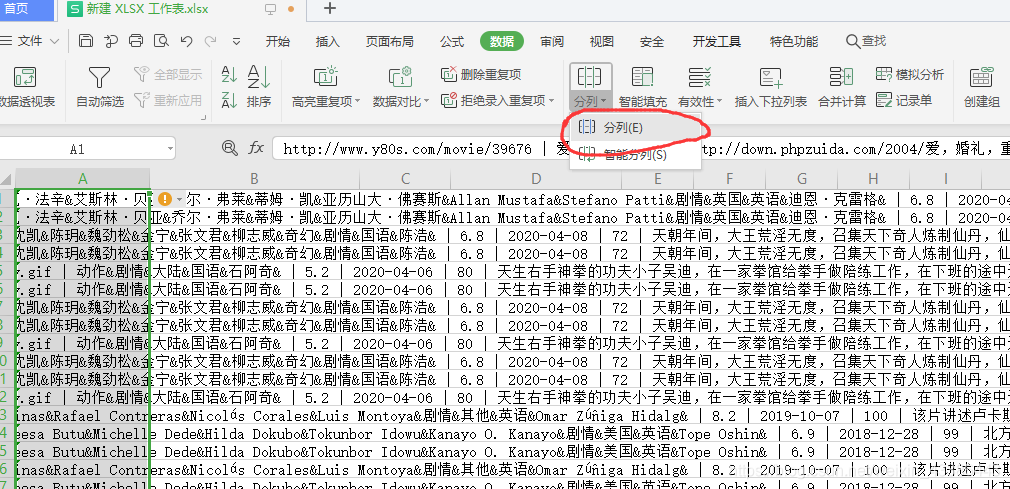
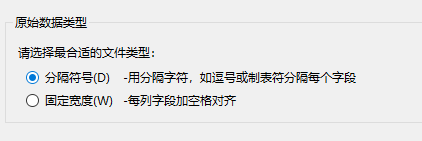
2.选中第一列–》点击数据-》点击分列-》选择分隔符号| -》完成
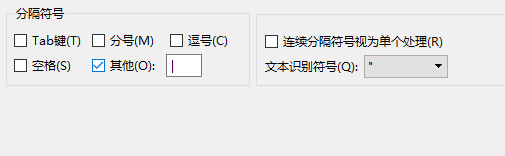
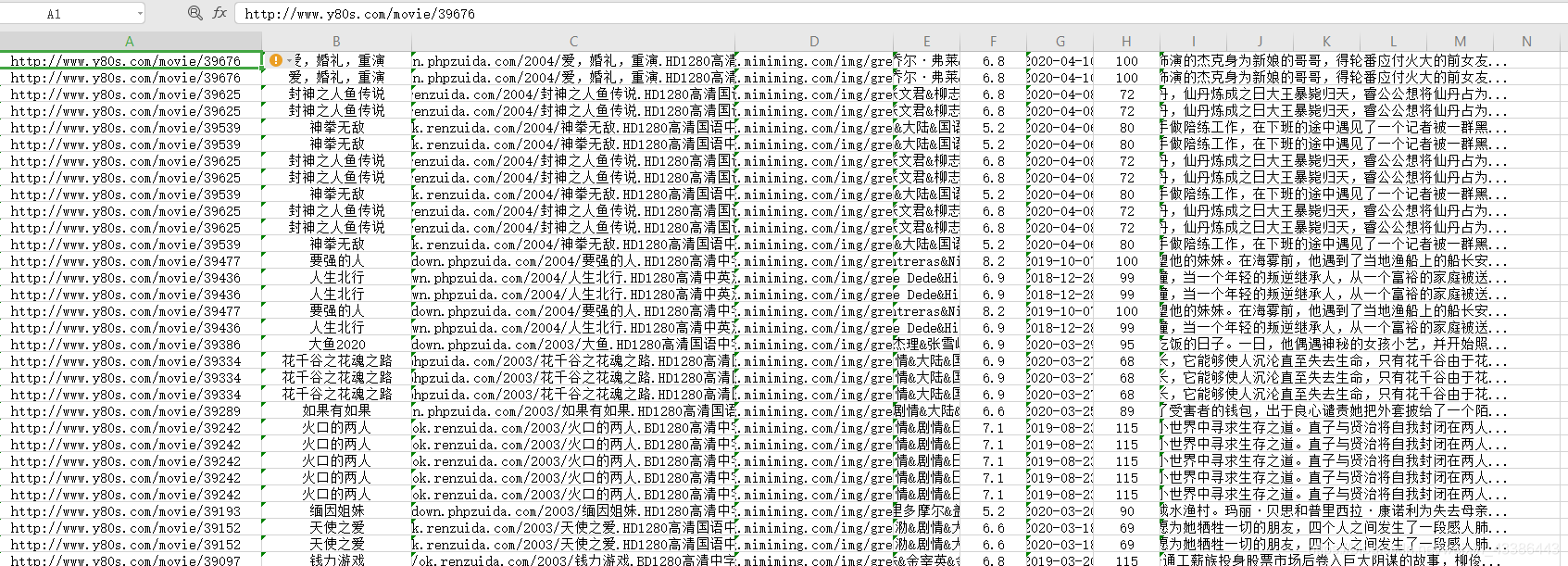
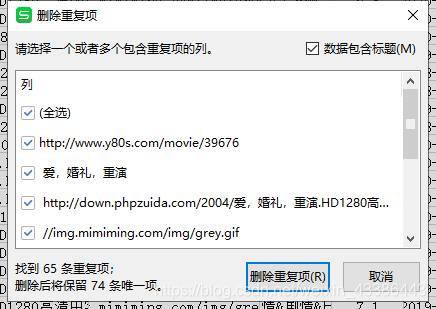
3.数据去重:
选择第一列-》点击删除重复项-》看步骤-》完成
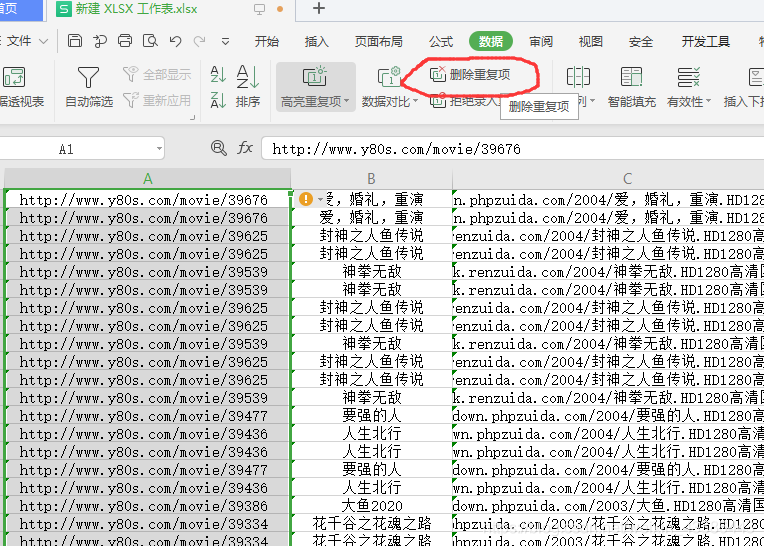
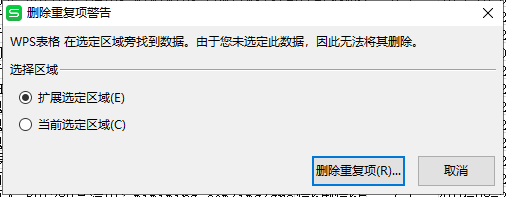
4.注意事项:
关于电影信息,电影信息未完全处理,请自行到80s看着信息截取
6.关于:
转载请说明出处!!!
点赞收藏
