CPU views:
CPU消耗的分布及时间(cpu时间或者运行时间); 方法的执行图; 方法的执行统计(最大,最小,平均运行时间等)

实践
为了方便实践,直接以JProfiler8自带的一个例子来帮助理解上面的相关概念。
JProfiler 自带的例子如下:模拟了内存泄露和线程阻塞的场景:
具体源码参考: /jprofiler install path/demo/bezier
(图12 )

(图13 Leak Memory 模拟内存泄露, Simulate blocking 模拟线程间锁的阻塞)

A1. 首先来分析下内存泄露的场景:(勾选图13中 Leak Memory 模拟内存泄露)
1. 在**Telemetries-> Memory**视图中你会看到大致如下图的场景(在看的过程中可以间隔一段时间去执行Run GC这个功能):看到下图蓝色区域,老生代在gc后(**波谷**)内存的大小在慢慢的增加(理想情况下,这个值应该是稳定的)
(图14)


在 Live memory->Recorded Objects 中点击**record allocation data**按钮,开始统计一段时间内创建的对象信息。执行一次**Run GC**后看看当前对象信息的大小,并点击工具栏中**Mark Current**按钮(其实就是给当前对象数量打个标记。执行一次Run GC,然后再继续观察;执行一次Run GC,然后再继续观察...。最后看看哪些对象在不断GC后,数量还一直上涨的。最后你看到的信息可能和下图类似
(图15 绿色是标记前的数量,红色是标记后的增量)在Heap walker中分析刚才记录的对象信息
(图16)
(图17)点击上图中实例最多的class,右键**Use Selected Instances->Reference->Incoming Reference**.
发现该Long数据最终是存放在**bezier.BeaierAnim.leakMap**中。
(图18)




在Allocations tab项中,右键点击其中的某个方法,可查看到具体的源码信息.
(图19)

【注】:到这里问题已经非常清楚了,明白了在图17中为什么哪些实例的数量是一样多,并且为什么内存在fullgc后还是回收不了(一个old 区的对象leakMap,put的信息也会进入old区, leakMap如回收不掉,那么该map中包含的对象也回收不掉)。
A2. 模拟线程阻塞的场景(勾选图13中Simulate blocking 模拟线程间锁的阻塞)
为了方便区分线程,我将Demo中的BezierAnim.java的L236的线程命名为test
public void start() { thread = new Thread(this, "test"); thread.setPriority(Thread.MIN_PRIORITY); thread.start();
}
正常情况下,如下图
(图20)

勾选了Demo中"Simulate blocking"选项后,如下图(注意看下下图中的状态图标), test线程block状态明显增加了。
(图21)

在**Monitors & locks->Monitor History**观察了一段时间后,会发现有4种发生锁的情况。
第一种:
AWT-EventQueue-0 线程持有一个Object的锁,并且处于Waiting状态。
图下方的代码提示出Demo.block方法调用了object.wait方法。这个还是比较容易理解的。
(图22)

第二种:
AWT-EventQueue-0占有了bezier.BezierAnim$Demo实例上的锁,而test线程等待该线程释放。
注意下图中下方的源代码, 这种锁的出现原因是Demo的blcok方法在AWT和test线程
都会被执行,并且该方法是synchronized.
(图23)

第三种和第四种:
test线程中会不断向事件Event Dispatching Thread提交任务,导致竞争java.awt.EventQueue对象锁。
提交任务的方式是下面的代码:repaint()和EventQueue.invokeLater
public void run() {
Thread me = Thread.currentThread(); while (thread == me) {
repaint(); if (block) {
block(false);
} try {
Thread.sleep(10);
} catch (Exception e) { break;
}
EventQueue.invokeLater(new Runnable() { @Override public void run() {
onEDTMethod();
}
});
}
thread = null;
}
(图24)

内存泄漏的现象:
1. 在服务器中执行某些批量操作的时候,发现内存只升不降;就算gc后,内存也不能被完全释放;
2. 除非重启tomcat服务器,内存永远不会被释放,反复执行这些操作,会导致无可用内存,tomcat死掉;
使用JProfiler检查内存泄漏的步骤:
1. 初始化检验环境:
切换到“Live Memory-->All Objects”标签,可以看到当前tomcat中的对象情况,注意jprofiler其他版本可能位置不一样.
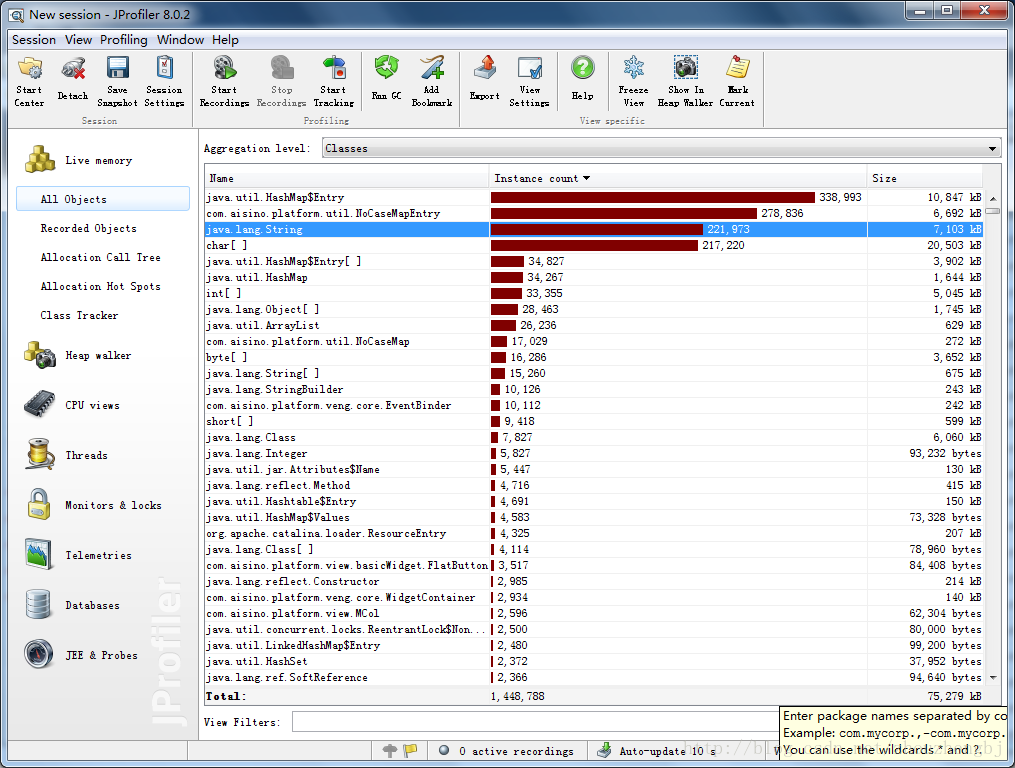
在执行操作前,需要先F4,运行“Run GC”,使jvm进行内存回收清理无效的对象.为了便于比较内存的增长情况,可以点击右键--->"Mark Current",
来将当前内存使用情况作为参照;点击后会显示“Difference”列,该列会列出对象数量的变化和变化比率
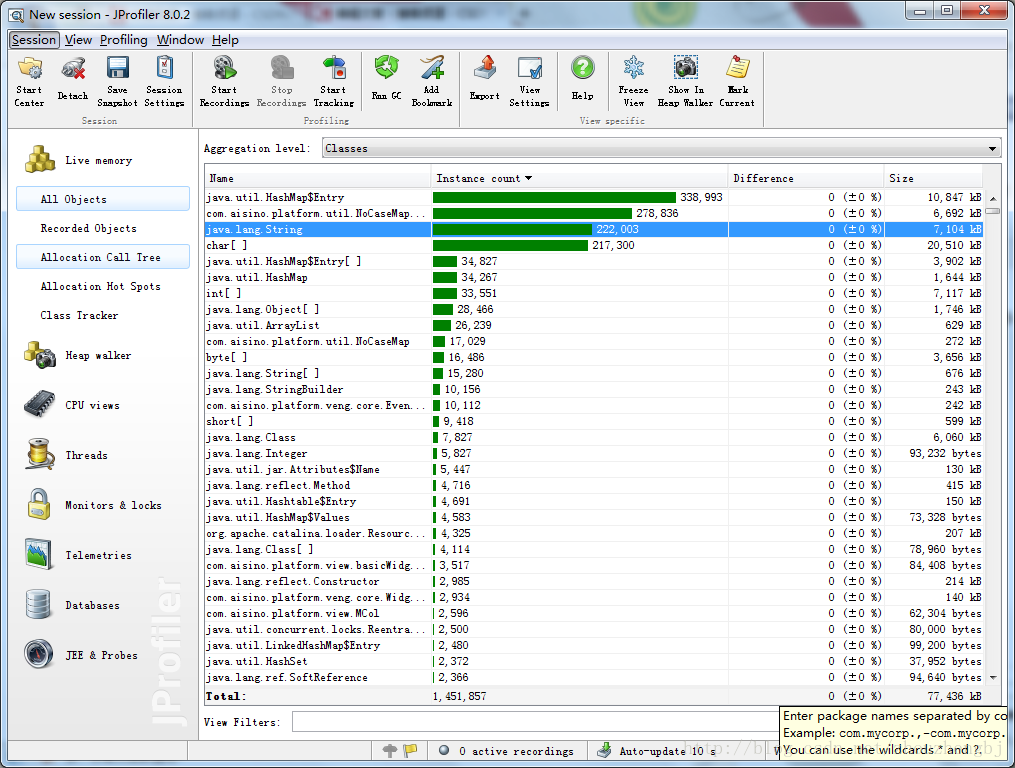
2.打开内存记录:
点击“Start Recordings”按钮,开始记录。执行这步的主要目的是为下面“Heap Walker”设置一个监控区间;如果不记录的话“Heap Walker”将分析jvm虚拟机的所有内存,即耗时又不能准确的发现内存泄漏的原因。
3. 执行操作,执行gc;
使用压力工具访问被测应用,执行完之后再次F4进行GC----这样是为了消除可以回收的对象。执行内存回收后,仍然存在于内存中的对象有可能是泄漏的对象。如下图instance count中红色的部门为不能回收的对象,difference列列出了增加的对象数量和增。以String为例,在该操作中增加了31751个对象增幅达到了14%,随后会在HeapWalker中观察这些对象,分析哪些对象是泄漏的。一般引起泄漏的对象包括:String、char[]、HashMap、Concurrenthashmap等,这类对象需要重点关注下;
4. 关闭内存记录:
点击“Stop Recordings”关闭内存记录,告诉jProfiler把这段记录作为分析对象;
5. 找到增加迅速的对象类型,打开HeapWalker:
在视图中找到增长快速的对象类型,本例Concurrenthashmap的增长速度很快。在memory视图中找到Concurrenthashmap---点右键----选择“Show Selectiion In Heap Walker”,切换到HeapWarker 视图;切换前会弹出选项页面,注意一定要选择“Select recorded objects”,这样Heap Walker会在刚刚的那段记录中进行分析;否则,会分析tomcat的所有内存对象,这样既耗时又不准确;

6. 在HeapWalker中,找到泄漏的对象;
HeapWarker 会分析内存中的所有对象,包括对象的引用、创建、大小和数量;

HeapWarker视图下方可以进行页面切换:
通过切换到References页签,可以看到这个类的具体对象实例。

为了在这些内存对象中,找到泄漏的对象(应该被回收),可以在该对象上点击右键,选择“Use Selected Instances”缩小对象范围;

单击OK按钮
7. 通过引用分析该对象:
在References引用页签中,可以看到该对象的的引用关系,可以切换incoming/outcoming,显示引用的类型:
incoming 表示显示这个对象被谁引用;
outcoming 表示显示这个对象引用的其他对象;

选择“Show In Graph”将引用关系使用图形方式展现;
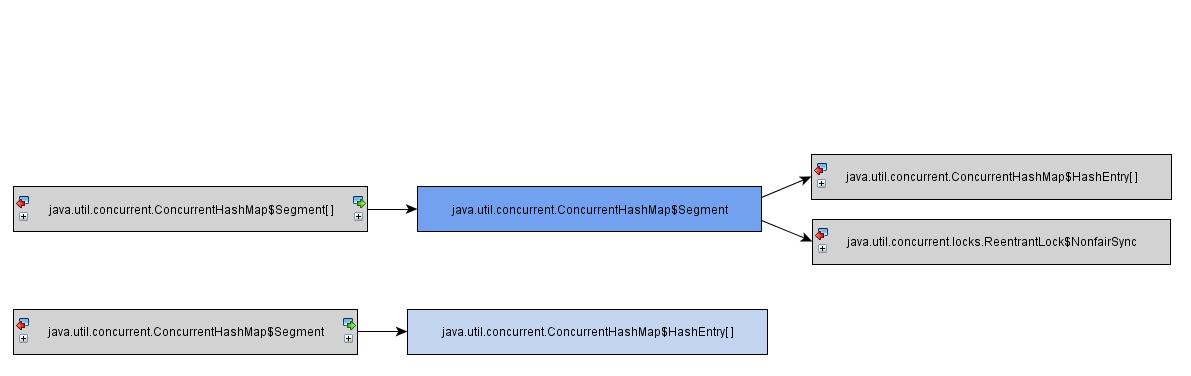
选中该对象,点击“Show Paths To GC Root”,会找到引用的根节点;

在上图中,我们可以发现,这个HashMap Segment对象最终的引用是在ConcurrentHashMap和ReentranLock对象中;
8. 通过创建分析该对象:
如果第7步还不能定位内存泄露的地方,我们可以尝试使用Allocations页签,该页签显示对象是如何创建出来的;
我们可以从创建方法开始检查,检查所有用到该对象的地方,直到找到泄漏位置;

概述:
JProfiler是用于分析J2EE软件性能瓶颈并能准确定位到Java类或者方法有效解决性能问题的主流工具,它通常需要与性能测试工具如:LoadRunner配合使用,因为往往只有当系统处于压力状态下才能反映出性能问题。
分析内存:
系统的内存消耗过多往往有以下几种原因:
频繁创建Java对象,如:数据库查询时,没分页,导致查出表中所有记录;
存在大对象,如:读取文件时,不是边读边写而是先读到一个byte数组,这样如果读取的文件时50M则仅此一项操作就会占有JVM50M内存。
存在内存泄漏,导致已不被使用的对象不被GC回收,从而随着系统使用时间的增长,内存不断受到解压,最终OutOfMemory。
当需要预判或者问题发生需要解决系统的内存问题时,可以借助JProfiler的Memory Views和VM Telemetry Views两种视图:
解决问题1和2,需借助Memory Views视图,如下:

图:1
图1主体表格的三列是解决问题的关键,可以通过如下步骤分析:
通过单击Size列列名可排列出最占内存的对象,查看所占内存大小,如果过大并且它对应的Instance Count比较小则说明该对象是大对象,这时可以对应Name列指示的Java类路径找到项目里的Java类进行分析,如果不合理则改之。
通过单击Instance Count列列名可排列出内存中实例数最多的Java对象,通过Name列指示的Java类路径逐一排查可能存在的设计问题。
注:在JProfiler的下方可以通过包路径过滤需要关注的对象,如图:

图:2
在图2中的ViewFilters输入框中输入“org.sotower”回车,则在列表中只有列出sotower包下的对象相关信息。
注意:在该视图下方的Recorded Objects子视图可以记录对象,从而查看类在一段时间里的总共实例数、GC数和活动数,但是在使用这些功能时会导致系统的性能严重降低,例如:没开此功能时,1000并发响应时间为1s,开此功能后500并发时响应时间才能达到1s,因此只有当存在内存泄漏时才开启该功能。Recorded Objects子视图记录功能没开启前的截图如下:

图:3
解决问题3说明的内存溢出问题,需要同时借助Memory Views和VM Telemetry Views视图。

图:4
在VM Telemetry Views试图里,可以看出JVM的总共内存分配大小、内存占用大小和内存空闲大小以及GC后内存占用的变化。在图4中可以看出蓝色区域上线有一个陡降的坡度,这时GC后内存占用下降的结果,在分析是否存在内存泄漏问题时,该下坡具有重要意义,在用LoadRunner疲劳测试时,在稳压期间,良好的系统内存占用应该是比较稳定,并且GC后下坡的幅度也应该比较一致,比如:前次GC释放200M,下次GC大致也是200M,这是一般规律,具体在分析时或有不同,性能分析人员应灵活运用。
当发现GC后回收的力度越来越小,则说明很有可能存在内存泄漏,这时需要开启该视图的Memory Views视图的Recorded Objects子视图,开启前的视图请见:图3,开启后视图如下:

图:5

图:6
如图6,在该视图里打开右键菜单,不断切换GC、Live和GC Live这三种模式,并结合项目的Java类,找出本该被回收但却没有得到回收的对象的对应Java类,从而找出问题根源。
分析CPU:
通常一个方法的执行时间越长则占用CPU的资源则越多,在JProfiler里就是通过方法的执行时间来描述对CPU的使用情况。如图:

图:7
在图7中,可以发现JProfiler以很清楚的层级结构描述出在一段时间里涉及类方法的执行时间,这些时间是从开始记录到查看该视图这段时间所发生的执行时间的合计,如此可以准确反映出真实场景下的方法执行情况。
一般是用LoadRunner压一段时间后再查看该视图,通过占用时间的不同,找出系统里最耗时的类方法进行调优解决问题。
发现执行一次请求,响应时间不能满足需求时,通过这种CPU时间占有的方式分析可优化点是一种简单而有效的方式。
分析线程:
线程的运行情况可以直接反应出系统的瓶颈所在,对线程一般有以下三个关注点:
Web容器的线程最大数管理,Web容器允许开启的线程数与系统要求的最大并发数有一定的对应关系,通常是Web容器运行的线程数略大于最大并发数,以Tomcat为例,在{$tomcat}/conf/server.xml文件的Connector选项里配置maxThreads,它的默认值时150;
线程阻塞;
线程死锁。
在JProfiler里有专门的线程视图:Thread Views,该视图能很好的发现并解决线程相关的大多问题。线程运行历史图:

图:8
如图8在Thread Views的Thread History视图里可以查看Web容器共打开的线程数以及这些线程的使用情况,在视图里红色表示阻塞的时间段,红色线条越长代表阻塞的时间越长,说明在存在阻塞情况这时切换到Current Monitor Usage或者Monitor Usage History视图,如:

图:9
通过视图上方的
指定只显示阻塞时间超过一定s(秒)数的线程,在本例中指定5s,在线程表格中选中一行,一般会在下方表格里显示出等待线程和拥有线程的执行堆栈,通过分析这些执行堆栈并在项目中找到对应的Java类方法,分析阻塞原因(往往是使用synchronized同步关键字导致阻塞,因此在用到synchronized关键字时一定要谨慎),从而解决问题。
如果系统里存在线程死锁情况,则会显示在Deadlock Detection视图:

图:10
在该视图里会把死锁线程的Java对象调用关系以关系网的方式展示,并能定位到造成死锁的类方法,通过结合该图和Java代码分析解决问题。