摘要
采用谱减法、维纳滤波、LMS滤波、NLMS滤波,进行信号降噪。
选用残余噪声、归一化均方根MRMS、相关系数、信噪比的指标,对LMS和NLMS进行简单的比较。
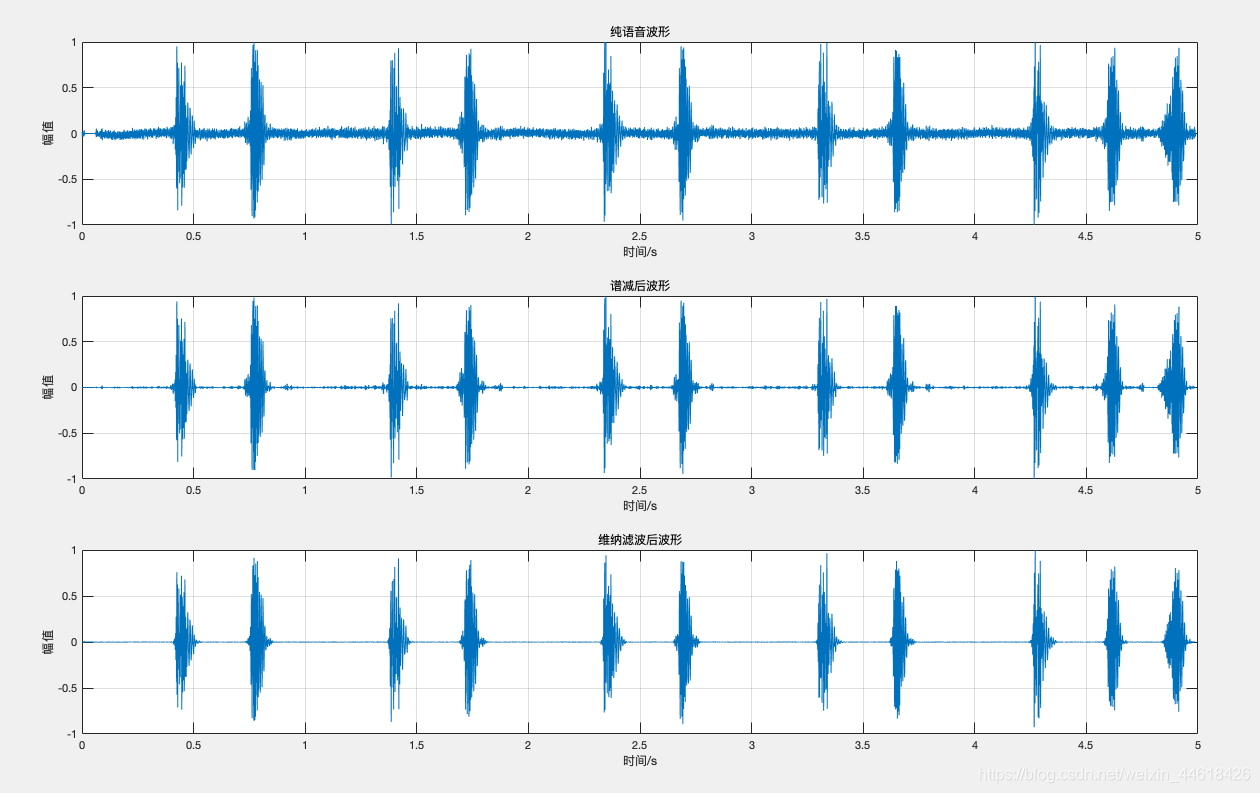
(1)谱检法、维纳滤波
输入:含噪的心音signal
输出:output_subspec、output_wn
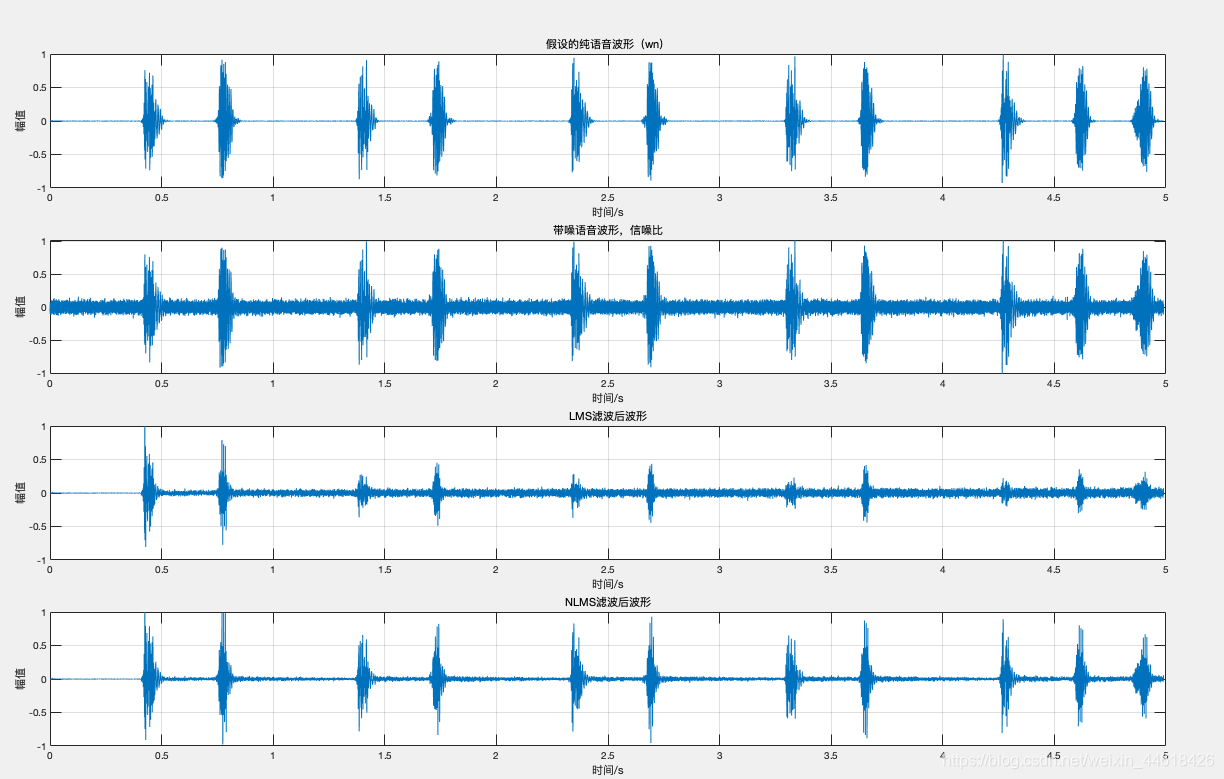
(2)LMS、NLMS
输入:不含噪的心音dn、增加白噪音生成的xn
输出:output_lms、output_nlms
评价指标:残余噪声、归一化均方根MRMS、相关系数、信噪比
实验结果

降噪算法综述


维纳滤波器
-
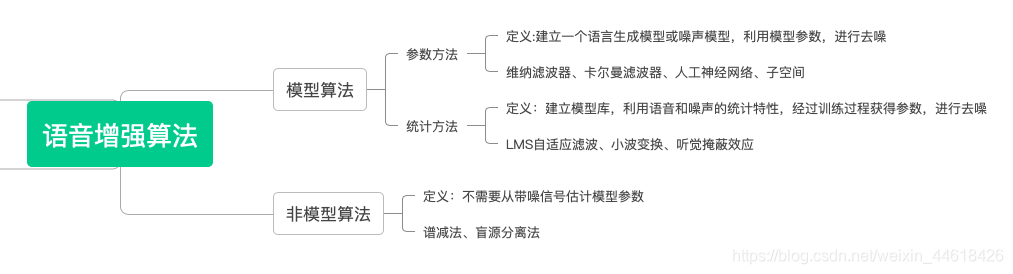
对加性噪声污染信号,通常采用自适应滤波器进行降噪。自适应滤波,是利用前一时刻已经获得的滤波器参数等结果,自动地调节现在时刻的滤波器参数,以适应信号和噪声未知的或随机变化的统计特性。因此,其对信号和噪声的先验知识需求较少。-宋;自适应滤波是一个很大的领域,有 维纳滤波器、最小均方自适应滤波器、归一化最小均方自适应滤波器、递归最小二乘自适应滤波器、卡尔曼滤波器、平方根自适应滤波器…-西蒙
-
维纳自适应滤波器
-
背景:人们只能测量到带噪声的语音信号y,
-
目标:当噪声v与信号s无关时,滤波得到的s^, 使其与s的最小均方误差最小,即完成滤波。
-
步骤:


代码
function output=WienerScalart96m_2(signal,fs,IS,T1)
% output=WIENERSCALART96(signal,fs,IS)
% Wiener filter based on tracking a priori SNR usingDecision-Directed
% method, proposed by Scalart et al 96. In this method it is assumed that
% SNRpost=SNRprior +1. based on this the Wiener Filter can be adapted to a
% model like Ephraims model in which we have a gain function which is a
% function of a priori SNR and a priori SNR is being tracked using Decision
% Directed method.
% 基于威纳滤波的先验信噪比跟踪采用决策导向方法,
% 在这个方法中,我们假设SNRpost=SNRprior +1。
% 基于此,维纳滤波器可以适用于类似于Ephraims的模型,
% 在这种模型中,我们有一个增益函数,它是先验信噪比的函数,
% 而先验信噪比是通过决策指导法进行跟踪的。
% Author: Esfandiar Zavarehei
% Created: MAR-05
if (nargin<3 | isstruct(IS)) % 如果输入参数小于3个或IS是结构数据
IS=.25;
end
W=fix(.025*fs); % 帧长为25ms
SP=.4; % 帧移比例取40%(10ms)
wnd=hamming(W); % 设置窗函数
% 如果输入参数大于或等于3个并IS是结构数据(为了兼容其他程序)
if (nargin>=3 & isstruct(IS))
SP=IS.shiftsize/W;
nfft=IS.nfft;
wnd=IS.window;
if isfield(IS,'IS')
IS=IS.IS;
else
IS=.25;
end
end
pre_emph=0;
signal=filter([1 -pre_emph],1,signal); % 预加重
NIS=fix((IS*fs-W)/(SP*W) +1); % 计算无话段帧数
y=segment(signal,W,SP,wnd); % 分帧
Y=fft(y); % FFT
YPhase=angle(Y(1:fix(end/2)+1,:)); % 带噪语音的相位角
Y=abs(Y(1:fix(end/2)+1,:)); % 取正频率谱值
numberOfFrames=size(Y,2); % 计算总帧数
FreqResol=size(Y,1); % 计算频谱中的谱线数
N=mean(Y(:,1:NIS)')'; % 计算无话段噪声平均谱值
LambdaD=mean((Y(:,1:NIS)').^2)'; % 初始噪声功率谱方差
alpha=.99; % 设置平滑系数
fn=numberOfFrames;
miniL=5; % 设置miniL
[voiceseg,vosl,SF,Ef]=pitch_vad1(y,fn,T1,miniL); %端点检测
NoiseCounter=0; % 初始化NoiseCounter
NoiseLength=9; % 设置噪声平滑区间长度
G=ones(size(N)); % 初始化谱估计器
Gamma=G;
X=zeros(size(Y)); % 初始化X
h=waitbar(0,'Wait...'); % 设置运行进度条图
for i=1:numberOfFrames
SpeechFlag=SF(i);
if i<=NIS % 若i<=NIS在前导无声(噪声)段
SpeechFlag=0;
NoiseCounter=100;
%else % i>NIS判断是否为有话帧
%[NoiseFlag, SpeechFlag, NoiseCounter, Dist]=vad(Y(:,i),N,NoiseCounter);
end
if SpeechFlag==0 % 在无话段中平滑更新噪声谱值
N=(NoiseLength*N+Y(:,i))/(NoiseLength+1);
LambdaD=(NoiseLength*LambdaD+(Y(:,i).^2))./(1+NoiseLength);%更新和平滑噪声方差
end
gammaNew=(Y(:,i).^2)./LambdaD; % 计算后验信噪比
xi=alpha*(G.^2).*Gamma+(1-alpha).*max(gammaNew-1,0); % 计算先验信噪比
Gamma=gammaNew;
G=(xi./(xi+1)); % 计算维纳滤波器的谱估计器
X(:,i)=G.*Y(:,i); % 维纳滤波后的幅值
%显示运行进度条图
waitbar(i/numberOfFrames,h,num2str(fix(100*i/numberOfFrames)));
end
close(h); % 关闭运行进度条图
output=OverlapAdd2(X,YPhase,W,SP*W); % 语音合成
output=filter(1,[1 -pre_emph],output); % 消除预加重影响
output=output/max(abs(output));
N=length(signal);
ol=length(output); % 把output补到与x等长
if ol<N
output=[output; zeros(N-ol,1)];
end
LMS自适应滤波器
- 最小均方(LMS)自适应滤波算法是 以已知期望响应和滤波器输出信号之间误差的均方值最小为准。

计算步骤:

注意图7-1-3的对应x/w/d/y
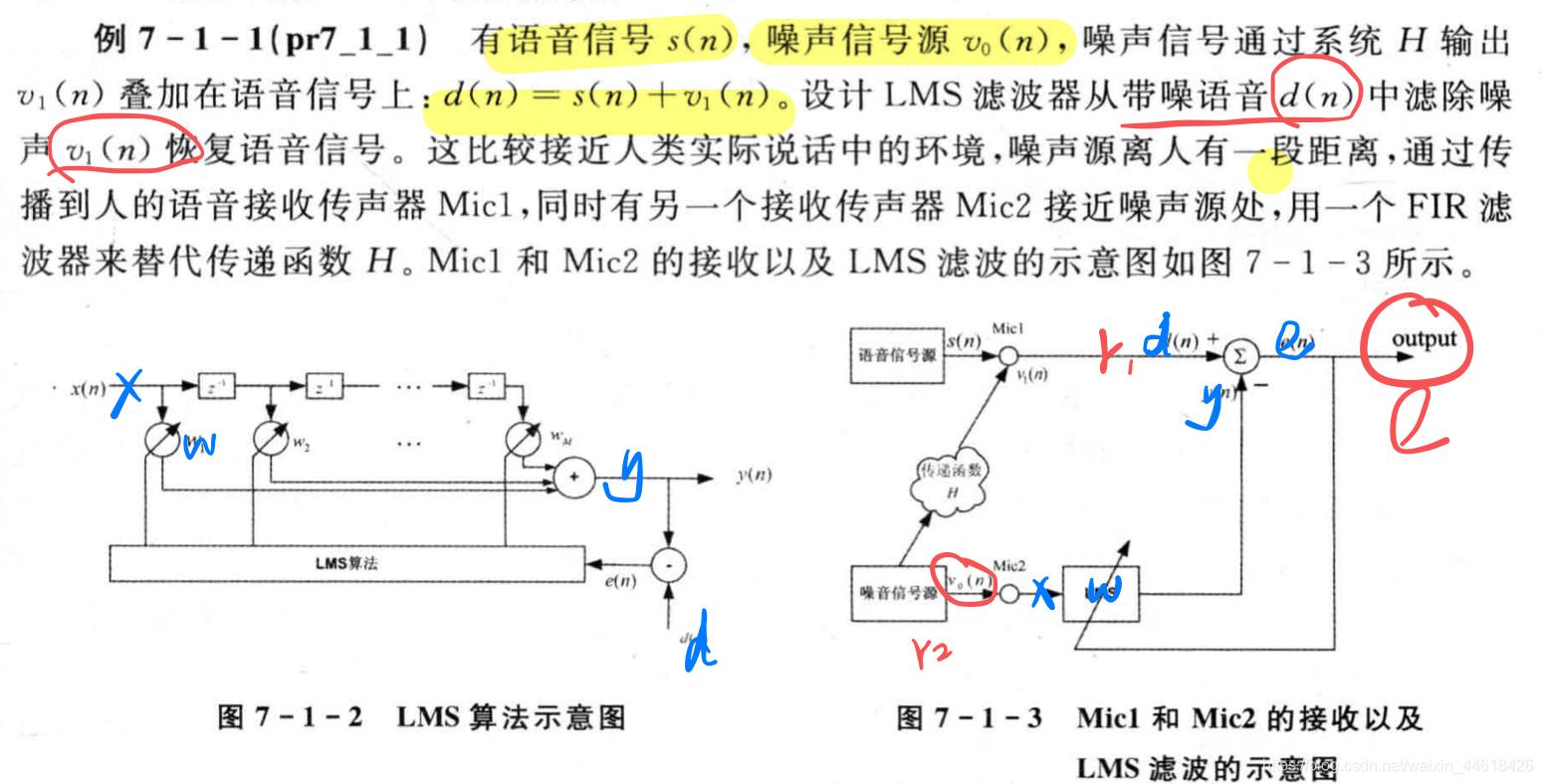
理解:
(1)LMS最终达到的目的是:e=d-y最小。根据7-1-3可以这样理解,d是含噪音信号,y是噪音信号。当e=d-y最小时,不要惯性以为e=0,经过处理后的e信号,是含噪信号-噪音=语音信号。因此说:output_lms=e。
(2)比较NLMS与LMS的性能差异
代码
function [y,w,e]=LMS(xn,dn,M,mu)
% LMS(Least Mean Squre)算法
% 输入参数:
% xn 输入的信号序列 (列向量)
% dn 所期望的响应序列 (列向量)
% M 滤波器的阶数 (标量)
% mu 收敛因子(步长) (标量) 要求大于0,小于xn的相关矩阵最大特征值的倒数
% itr 迭代次数 (标量) 默认为xn的长度,M<itr<length(xn)
% 输出参数:
% W 滤波器的权值矩阵 (矩阵)
% 大小为M x itr,
% e 误差序列(itr x 1) (列向量)
% y 实际输出序列 (列向量)
% 参数个数必须为4个或5个
itr=length(xn);
if nargin == 4 % 4个时递归迭代的次数为xn的长度
itr = length(xn);
elseif nargin == 5 % 5个时满足M<itr<length(xn)
if itr>length(xn) | itr<M
error('迭代次数过大或过小!');
end
else
error('请检查输入参数的个数!');
end
% 初始化参数
e = zeros(itr,1); % 误差序列,en(k)表示第k次迭代时预期输出与实际输入的误差
w = zeros(M,itr); % 每一行代表一个加权参量,每一列代表-次迭代,初始为0
en = zeros(itr,1);
% 迭代计算
for k = M:itr % 第k次迭代
x = xn(k:-1:k-M+1); % 滤波器M个抽头的输入
y = w(:,k-1).' * x; % 滤波器的输出
e(k) = dn(k) - y ; % 第k次迭代的误差
% 滤波器权值计算的迭代式
w(:,k) = w(:,k-1)+2*mu*e(k)*x;
en(k) = en(k)+e(k)^2;
end
% % ?求最优时滤波器的输出序列
% y = inf * ones(size(xn));
% for k = M:length(xn)
% x = xn(k:-1:k-M+1);
% y(k) = w(:,end).'* x;
% end
LMS自适应陷波法
- 背景:如果信号中的噪声是频率为w0的正弦波干扰,可用陷波器降噪。
- 应用:噪声已知的降噪(如测量心电图时,混入50Hz工频信号及其谐波,可用LMS自适应陷波器滤波)
- 原理:
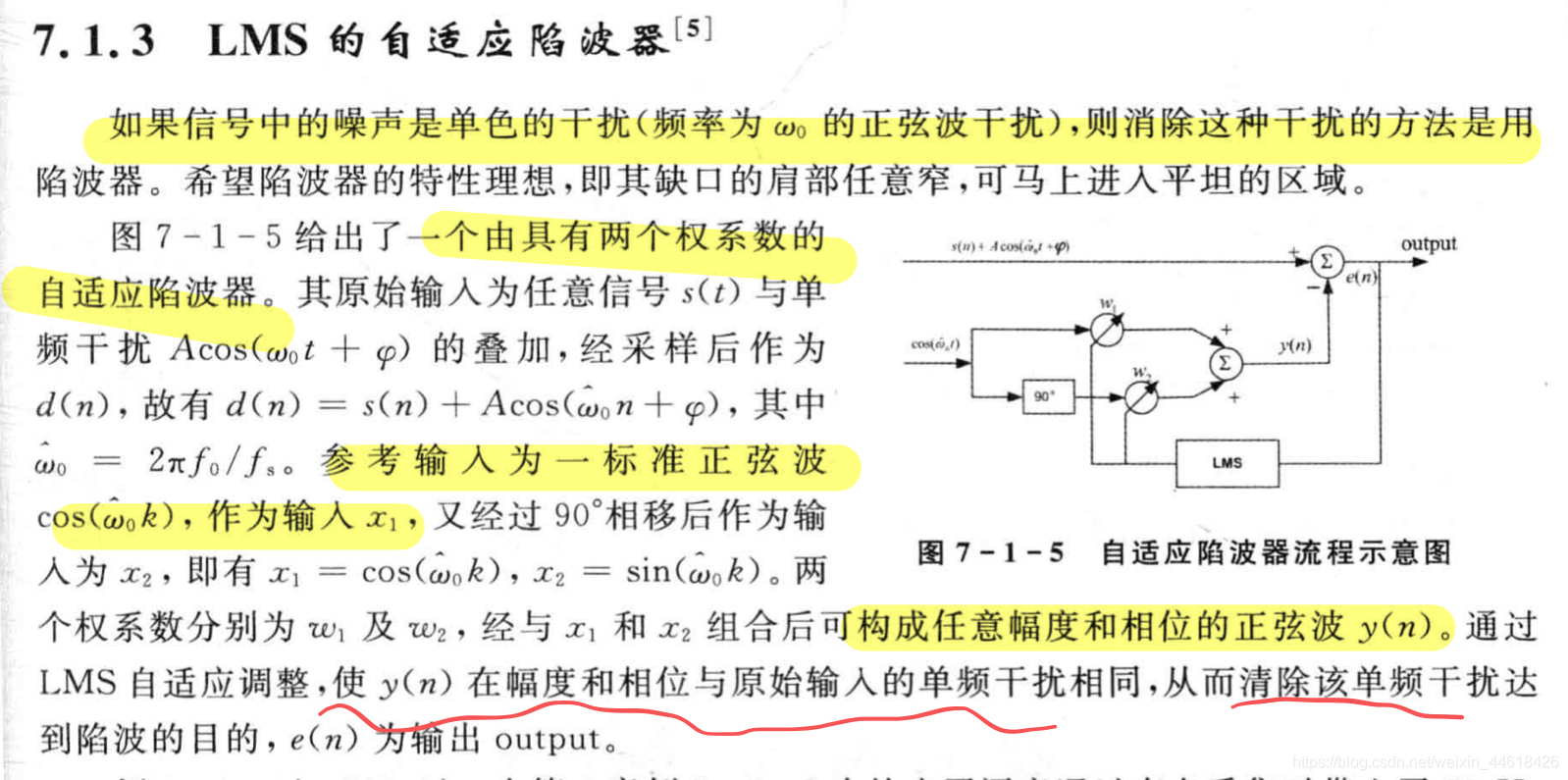
代码
function [output_notchLMS,w1,w2]=notchLMS(x,mu,f0,tt,N)
% notchLMS(Least Mean Squre)LMS陷波滤波器
% 输入参数:
% x 输入的信号序列 (行向量)
% mu 收敛因子(步长) (标量) 要求大于0,小于xn的相关矩阵最大特征值的倒数
% f0 陷波频率 (标量)
% tt 时间刻度 (行向量)
% N 信号长度 (标量)
% 输出参数:
% w1 滤波器的权值1 (标量)
% w2 滤波器的权值2 (标量)
%output_notchLMS 实际输出序列 (列向量)
% 初始化参数
x1=cos(2*pi*tt*f0); % 设置x1和x2
x2=sin(2*pi*tt*f0);
w1=0; % 初始化w1和w2
w2=1;
e=zeros(1,N); % 误差序列,e(k)表示第k次迭代时预期输出与实际输出的误差
y=zeros(1,N); % 输出序列,y(k)表示第k次迭代时,滤波器输出
for i=1:N % 自适应陷波器
y(i)=w1*x1(i)+w2*x2(i); % 滤波器的输出
e(i)=x(i)-y(i); % 第i次迭代的误差
w1=w1+mu*e(i)*x1(i); % 调整w
w2=w2+mu*e(i)*x2(i);
end
output_notchLMS=e; % 陷波器输出
谱减法
-
是一种利用语音信号的短时平稳特性,从带噪声的语音信号短时谱中减去噪声的短时谱,从而得到纯净语音的频谱。
该算法利用加性噪声与语音不相关的特点,在假设噪声是统计平稳的前提下,用无语音间隙测算到的噪声频谱估计值取代有语音期间噪声的频谱,与含噪语音频谱相减,从而获得语音频谱的估计值。 -
不足:
减去噪声谱后的增强语音会有些较大的功率谱分量的剩余部分,
在频域上呈现出随机出现的尖峰,
在时域上呈现出类正弦信号的叠加,具有一定节奏性起伏、类似音乐的“音乐噪声”。
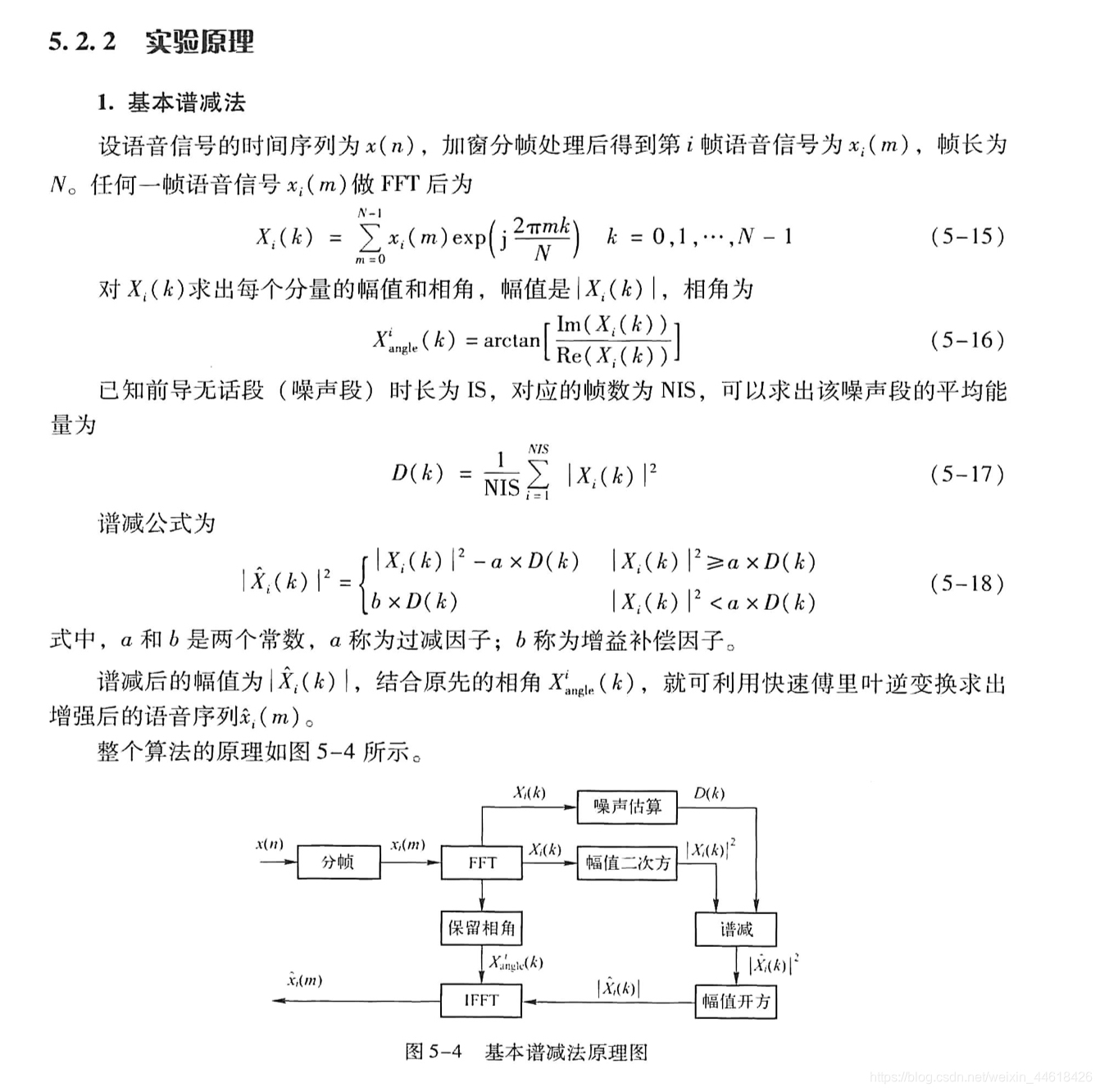

代码
function output_subspec=Subspec(signal,NIS,fn,wlen,inc,a,b)
% 谱减法
% 输入参数:
% signal输入的信号序列 (列向量)
% NIS 前导无话段帧数 (标量)
% fn 帧数 (标量)
% wlen 帧长 (标量)
% inc 帧移 (标量)
% a 过减因子 (标量)
% b 增益补偿因子 (标量)
% 输出参数:
% output_subspec 谱减法输出波形(列向量)
wnd=hamming(wlen); % 加窗
y=enframe(signal,wnd,inc)'; % 分帧
y_fft = fft(y); % FFT
y_a = abs(y_fft); % 求取幅值
y_phase=angle(y_fft); % 求取相位角
y_a2=y_a.^2; % 求能量
Nt=mean(y_a2(:,1:NIS),2); % 计算噪声段平均能量
nl2=wlen/2+1; % 求出正频率的区间
for i = 1:fn % 进行谱减
for k= 1:nl2
if y_a2(k,i)>a*Nt(k)
temp(k) = y_a2(k,i) - a*Nt(k);
else
temp(k)=b*y_a2(k,i);
end
U(k)=sqrt(temp(k)); % 把能量开方得幅值
end
X(:,i)=U;
end
output_subspec=OverlapAdd2(X,y_phase(1:nl2,:),wlen,inc); % 合成谱减后的语音
Nout=length(output_subspec); % 把谱减后的数据长度补足与输入等长
N=length(signal); % 信号长度
if Nout>N
output_subspec=output_subspec(1:N);
elseif Nout<N
output_subspec=[output_subspec; zeros(N-Nout,1)];
end
output_subspec=output_subspec/max(abs(output_subspec)); % 幅值归一
评价指标
关键词: 残余噪声、归一化均方根MRMS、相关系数、信噪比
-
存在的疑惑:
(1)衡量滤波效果 一般都用SNR(信噪比)、RMSE(均方根误差)等指标,根据这些指标的定义公式,都要知道真实不含噪信号,在做典型信号外加噪声的仿真实验时,这些性能指标比较容易得到。但对于实际信号,无法得到真实不含噪信号,而且真实不含噪声信号也正是滤波算法想得到的,那么这些指标是否还能适用呢?
A:一般仅知道带噪信号和去噪后信号比较难评性能。
(2)对于同一个信号,用谱减法、自适应滤波、小波去噪等多种去噪方法,如何比较去噪的效果?
A:像均方根、相关系数、信噪比等可以用作横向对比,但不适用于绝对的去噪效果评价 -
对LMS和NLMS的滤波结果,计算残余噪声、归一化均方根MRMS、相关系数、信噪比
1、残余噪声
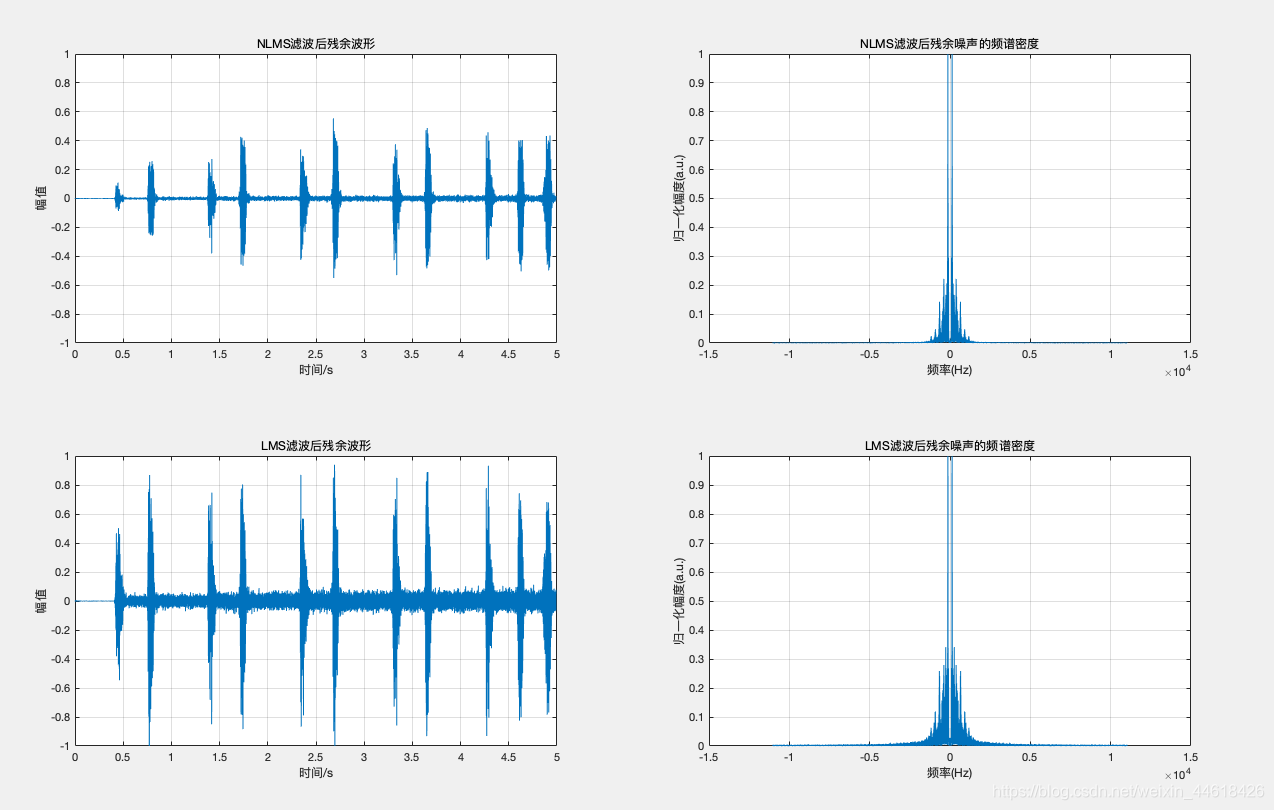
通过从系统输出e中减去源信号s可以得到残余噪声,残余噪声反映了系统输出信号的完整性。剩余噪声主要来自两个方面:一是环境噪声/干扰的残余部分;二是自适应滤波器产生的信号失真。
实验结果:
数字信号处理中均值、方差、均方值、均方差计算和它们的物理意义
2、归一化均方根MRMS
MRMS是一种归一化均方根MSE,反映了自适应系统引入的期望信号的失真程度。
代码:
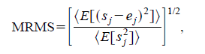
function MRMS=MRMS_cal(s,e)
% 归一化均方根
% s 是纯语音信号
% e 是滤波后信号
n=length(s);
sum=0;
sum1=0;
for i=1:n
sum=sum+(s(i)-e(i))^2;
end
ave=sum/n;
for i=1:n
sum1=sum1+s(i)^2;
end
ave1=sum1/n;
MRMS=sqrt(ave/ave1);
实验结果:

3、相关系数
利用自适应滤波的输出e跟噪声通道信号x求互相关表示去噪性能。
也可以用自适应输出e跟纯净的体音信号求相关表示去噪性能。
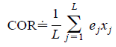
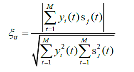
代码:
function cov=cov_cal(x,y)
% 协方差
sum=0;
n=length(x);
x_ave=mean(x);
y_ave=mean(y);
for i=1:n
sum=sum+(x(i)-x_ave)*(y(i)-y_ave);
end
cov=sum/(n-1);
实验结果:
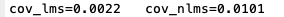
4、信噪比
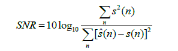
代码:
function snr=SNR_cal(I,In)
% 计算带噪语音信号的信噪比
% I 是纯语音信号
% In 是带噪的语音信号
% 信噪比计算公式是
% snr=10*log10(Esignal/Enoise)
I=I(:)'; % 把数据转为一列
In=In(:)';
Ps=sum((I-mean(I)).^2); % 信号的能量
Pn=sum((I-In).^2); % 噪声的能量
snr=10*log10(Ps/Pn); % 信号的能量与噪声的能量之比,再求分贝值
实验结果:
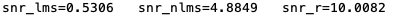
待解决的问题
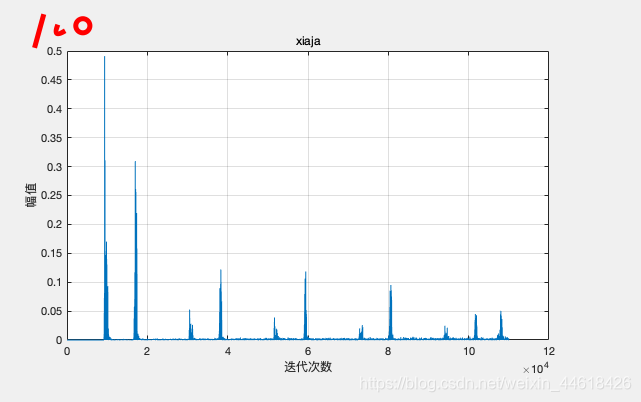
怎么画出 msd 迭代收敛曲线?
(1)做出 NLMS 和 LMS误差曲线
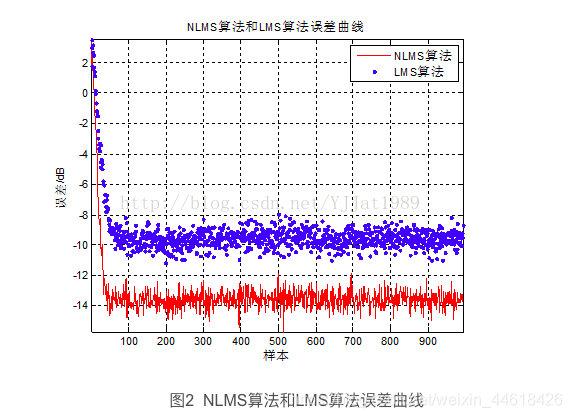
(2)不同步长对NLMS算法的影响
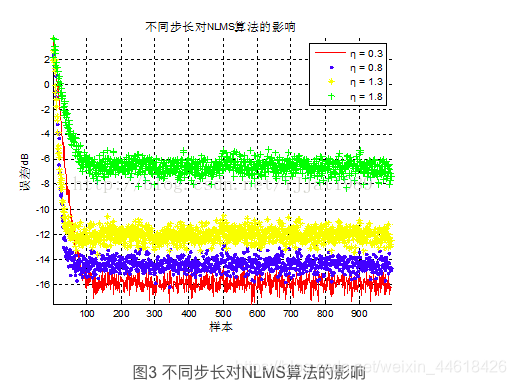
实际:一直是这样的…待开学解决…