kmalloc、vmalloc和malloc这3个常用的API函数具有相当的分量,三者看上去很相似,但在实现上可大有讲究。
kmalloc基于slab分配器,slab缓冲区建立在一个连续物理地址的大块内存之上,所以其缓存对象也是物理地址连续的。
如果在内核中不需要连续的物理地址,而仅仅需要内核空间里连续虚拟地址的内存块,该如何处理呢? 这时vmalloc()就派上用场了。
vmlloc()函数声明如下:
// \kernel\msm-3.18\mm\vmalloc.c
/**
* vmalloc - allocate virtually contiguous memory
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE, GFP_KERNEL | __GFP_HIGHMEM);
}
vmalloc使用的分配掩码是“GFP_KERNEL | __GFP_HIGHMEM”,说明会优先使用高端内存High Memory。
/**
* __vmalloc_node - allocate virtually contiguous memory
* @size: allocation size
* @align: desired alignment
* @gfp_mask: flags for the page level allocator
* @prot: protection mask for the allocated pages
* @node: node to use for allocation or NUMA_NO_NODE
* @caller: caller's return address
*
* Allocate enough pages to cover @size from the page level
* allocator with @gfp_mask flags. Map them into contiguous
* kernel virtual space, using a pagetable protection of @prot.
*/
static void *__vmalloc_node(unsigned long size, unsigned long align, gfp_t gfp_mask, pgprot_t prot, int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END, gfp_mask, prot, 0, node, caller);
}
这里的VMALLOC_START和VMALLOC_END是vmalloc中很重要的宏,这两个宏定义在arch/arm/include/pgtable.h头文件中。
ARM64架构的定义在arch/arm64/include/asm/pgtable.h头文件中。
VMALLOC_START是vmalloc区域的开始地址,它是在High_memory指定的高端内存开始地址再加上8MB大小的安全区域(VMALLOC_OFFSET)。
在ARM Vexpress平台中,vmalloc的内存范围在从0xf000_0000到0xff00_0000,大小为240MB, high_memory全局变量的计算在sanity_check_meminfo()函数中。
alloc_vmap_area()在vmalloc整个空间中查找一块大小合适的并且没有人使用的空间,这段空间称为hole。
注意这个函数参数vstart是指VMALLOC_START, vend是指VMALLOC_END。
查找的地址从VMALLOC_START开始,首先从vmap_area_root这棵红黑树上查找,这个红黑树里存放着系统中正在使用的vmalloc区块,遍历左子叶节点找区间地址最小的区块。
如果区块的开始地址等于VMALLOC_START,说明这区块是第一块vmalloc区块。
如果红黑树没有一个节点,说明整个vmalloc区间都是空的
在__vmalloc_area_node()函数中,首先计算vmalloc分配内存大小有几个页面,
然后使用alloc_page()这个API来分配物理页面,并且使用area->pages保存已分配页面的page数据结构指针,最后调用map_vm_area()函数来建立页面映射。
map_vm_area()函数最后调用vmap_page_range_noflush()来建立页面映射关系。
2.7 VMA操作
在32位系统中,每个用户进程可以拥有3GB大小的虚拟地址空间,通常要远大于物理内存,那么如何管理这些虚拟地址空间呢?
用户进程通常会多次调用malloc()或使用mmap()接口映射文件到用户空间来进行读写等操作,
这些操作都会要求在虚拟地址空间中分配内存块,这些内存块基本上都是离散的。
malloc()是用户态常用的分配内存的接口API函数
mmap()是用户态常用的用于建立文件映射或匿名映射的函数
这些进程地址空间在内核中使用struct vm_area_struct数据结构来描述,简称VMA,也被称为进程地址空间或进程线性区。
由于这些地址空间归属于各个用户进程,所以在用户进程的struct mm_struct数据结构中也有相应的成员,用于对这些VMA进行管理。
struct vm_area_struct数据结构各个成员的含义如下。
❑ vm_start和vm_end:指定VMA在进程地址空间的起始地址和结束地址。
❑ vm_next和vm_prev:进程的VMA都连接成一个链表。
❑ vm_rb:VMA作为一个节点加入红黑树中,每个进程的structmm_struct数据结构中都有这样一棵红黑树mm->mm_rb。
❑ vm_mm:指向该VMA所属的进程struct mm_struct数据结构。
❑ vm_page_prot:VMA的访问权限。
❑ vm_flags:描述该VMA的一组标志位。
❑ anon_vma_chain和anon_vma:用于管理RMAP反向映射。
❑ vm_ops:指向许多方法的集合,这些方法用于在VMA中执行各种操作,通常用于文件映射。
❑ vm_pgoff:指定文件映射的偏移量,这个变量的单位不是Byte,而是页面的大小(PAGE_SIZE)。
❑ vm_file:指向file的实例,描述一个被映射的文件。
2.8 malloc
假设系统中有进程A和进程B,分别使用testA和testB函数分配内存:
// 进程A 分配内存
void testA(void){
char * bufA = malloc(100);
*buf = 100;
}
// 进程B 分配内存
void testB(void){
char * bufB = malloc(100);
mlock(buf, 100);
}
Question:
- malloc 函数返回的内存是否马上就分配物理内存? testA 和 testB 分别在何时分配物理内存?
- 假设不考虑 libc 的因素,malloc 分配100 Byte,那么实际上内核是为其分配物理内存?
- 假设使用printf 打印指针buffA 和 buffB 指向的地址是一样的,那么在内核中这两块虚拟内存是否在“打架”呢?
- vm_normal_page() 函数返回的什么样的页面的 struct page 数据结构? 为什么内存管理代码中需要这两个函数。
- 请简述get_user_page() 函数的作用的实现流程。
malloc()函数是C函数库封装的一个核心函数,C函数库会做一些处理后调用Linux内核系统去调用brk,
所以大家并不太熟悉brk的系统调用,原因在于很少有人会直接使用系统调用brk向系统申请内存,而总是通过malloc()之类的C函数库的API函数。
2.8.1 brk实现
// \kernel\msm-3.18\mm\mmap.c
static unsigned long do_brk(unsigned long addr, unsigned long len);
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
struct vm_area_struct *next;
unsigned long min_brk;
bool populate;
down_write(&mm->mmap_sem);
#ifdef CONFIG_COMPAT_BRK
/*
* CONFIG_COMPAT_BRK can still be overridden by setting
* randomize_va_space to 2, which will still cause mm->start_brk
* to be arbitrarily shifted
*/
if (current->brk_randomized)
min_brk = mm->start_brk;
else
min_brk = mm->end_data;
#else
min_brk = mm->start_brk;
#endif
if (brk < min_brk)
goto out;
/*
* Check against rlimit here. If this check is done later after the test
* of oldbrk with newbrk then it can escape the test and let the data
* segment grow beyond its set limit the in case where the limit is
* not page aligned -Ram Gupta
*/
if (check_data_rlimit(rlimit(RLIMIT_DATA), brk, mm->start_brk, mm->end_data, mm->start_data))
goto out;
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk)
goto set_brk;
/* Always allow shrinking brk. */
if (brk <= mm->brk) {
if (!do_munmap(mm, newbrk, oldbrk-newbrk))
goto set_brk;
goto out;
}
/* Check against existing mmap mappings. */
next = find_vma(mm, oldbrk);
if (next && newbrk + PAGE_SIZE > vm_start_gap(next))
goto out;
/* Ok, looks good - let it rip. */
if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)
goto out;
set_brk:
mm->brk = brk;
populate = newbrk > oldbrk && (mm->def_flags & VM_LOCKED) != 0;
up_write(&mm->mmap_sem);
if (populate)
mm_populate(oldbrk, newbrk - oldbrk);
return brk;
out:
retval = mm->brk;
up_write(&mm->mmap_sem);
return retval;
}
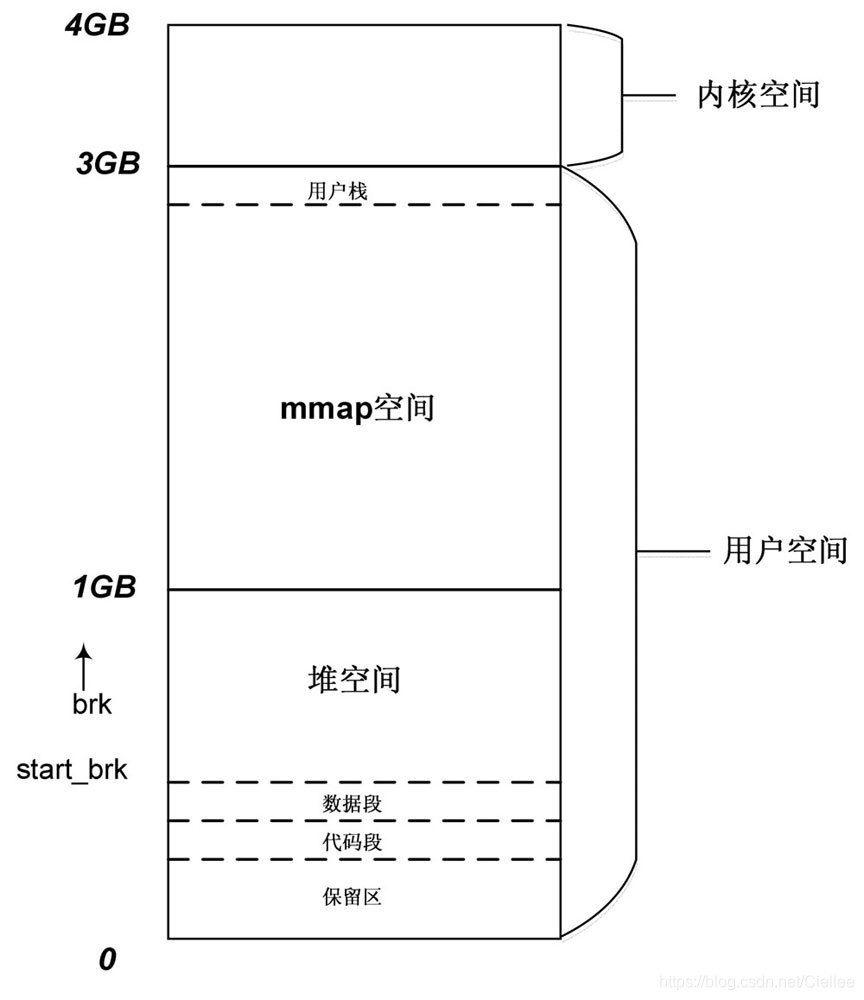
在32位Linux 内核中,每个用户进程拥有3GB 的虚拟内存。
内核为何为用户空间来划分这3GB 的虚拟空间呢?
用户进程的可执行文件由代码段和数据段组成,
数据段包括所有的静态分配的数据空间(如,全局变量和静态局部变量等 )。
这些空间在可执行文件装载时,内核就为其分配好这些空间,包括虚拟地址和物理页面,并建立好二者的映射关系。
如上图,用户进程的用户栈从3GB 虚拟空间的顶部开始,由顶向下延伸,
而 brk 分配的空间是从数据段的顶部end_data 到 用户栈的底部,就 是下这个连界往上推进 一段,同时内核和进程 会记录当前加界的位置。
/*
* this is really a simplified "do_mmap". it only handles
* anonymous maps. eventually we may be able to do some
* brk-specific accounting here.
*/
static unsigned long do_brk(unsigned long addr, unsigned long len)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
unsigned long flags;
struct rb_node **rb_link, *rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
len = PAGE_ALIGN(len);
if (!len)
return addr;
flags = VM_DATA_DEFAULT_FLAGS | VM_ACCOUNT | mm->def_flags;
error = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED);
if (error & ~PAGE_MASK)
return error;
error = mlock_future_check(mm, mm->def_flags, len);
if (error)
return error;
/*
* mm->mmap_sem is required to protect against another thread
* changing the mappings in case we sleep.
*/
verify_mm_writelocked(mm);
/*
* Clear old maps. this also does some error checking for us
*/
munmap_back:
if (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) {
if (do_munmap(mm, addr, len))
return -ENOMEM;
goto munmap_back;
}
/* Check against address space limits *after* clearing old maps... */
if (!may_expand_vm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
if (security_vm_enough_memory_mm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
/* Can we just expand an old private anonymous mapping? */
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL);
if (vma)
goto out;
/*
* create a vma struct for an anonymous mapping
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
INIT_LIST_HEAD(&vma->anon_vma_chain);
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
vma->vm_flags |= VM_SOFTDIRTY;
return addr;
}
get_user_pages()函数是一个很重要分配物理内存的接口函数,有很多驱动程序使用这个API来为用户态程序分配物理内存
vm_normal_page()函数把page页面分为两个阵营,一个是normalpage,另一个是special page。
(1)normal page通常指正常mapping的页面,例如匿名页面、pagecache和共享内存页面等。
(2)special page通常指不正常mapping的页面,这些页面不希望参与内存管理的回收或者合并的功能,例如映射如下特性页面。
❑ VM_IO:为I/O设备映射内存。
❑ VM_PFN_MAP:纯PFN映射。
❑ VM_MIXEDMAP:固定映射。
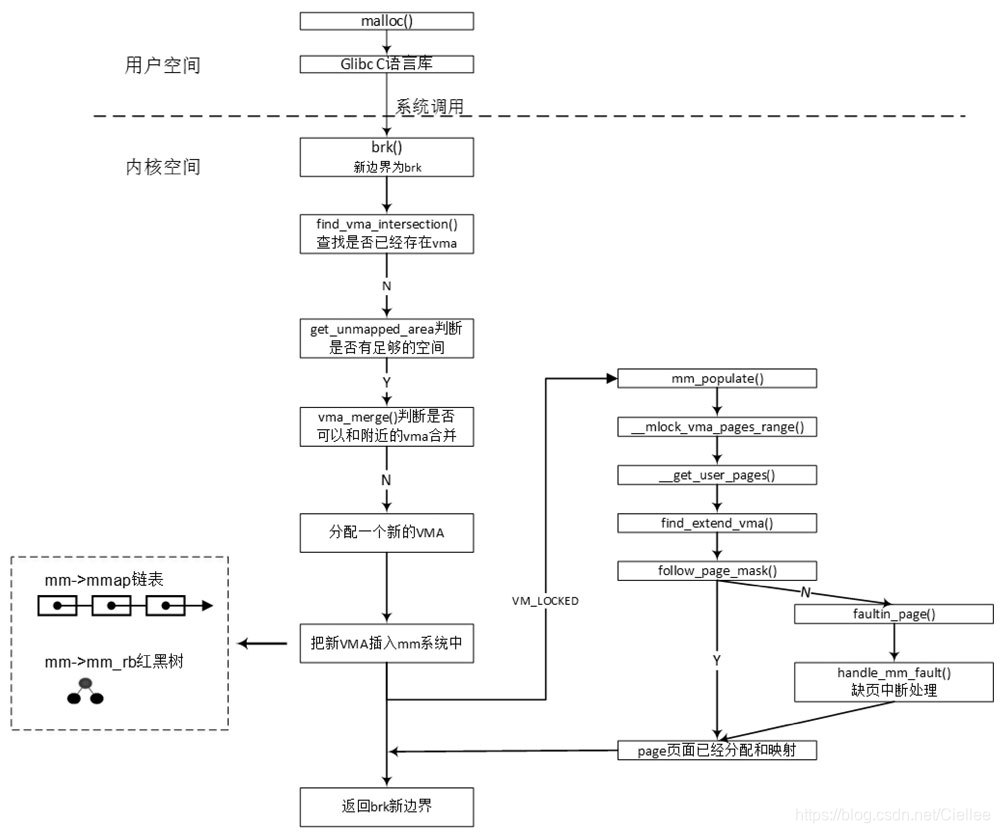
(1)get_user_pages()函数
用于把用户空间的虚拟内存空间传到内核空间,内核空间为其分配物理内存并建立相应的映射关系,
long get_user_pages(struct task_struct *tsk, struct mm_struct *mm, unsigned long start, unsigned long nr_pages, int write, int force ,struct page **pages, struct vm area struct **vmas);
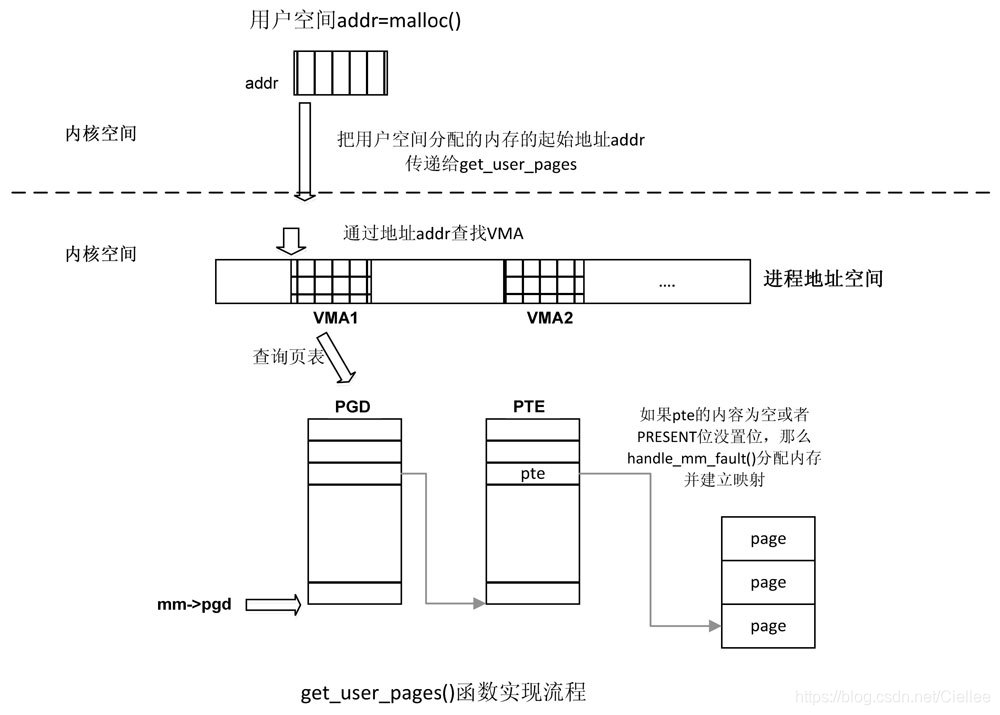
(2)follow_page()函数
通过虚拟地址addr寻找相应的物理页面,返回normal mapping页面对应的struct page数据结构,该函数会查询页表。
inline struct page *follow_page(struct vm_area_struct *vma, unsigned long address, unsigned int foll flags);
(3)vm_normal_page()函数
该函数由pte返回normal mapping的struct page数据结构,主要目的是过滤掉那些令人讨厌的special mapping的页面。
struct page *vm_normal_page(struct vm_area struct * vma, unsigned long addr, pte t_pte);
