目录
一. 事务
- Redis 事务可以一次执行多个命令(允许在一次单独的步骤中执行一组命令),并且带有以下两个重要的保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
1.1 特点
- Redis会将一个事务中的所有命令序列化,然后按顺序执行
- 执行中不会被其它命令插入,不许出现加赛行为
1.2 处理过程
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
1.3 事务的错误处理:
- 队列中的某个命令出现了报告错误,执行时整个的所有队列都会被取消。
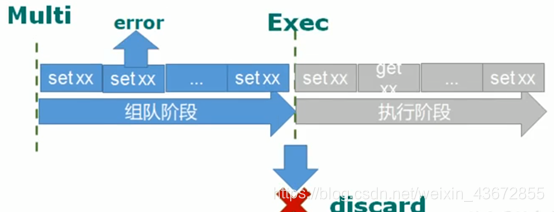

- 事务的错误处理
如果执行的某个命令报出了错误,则只有报错的命令不会被执行,而其它的命令都会执行,不会回滚。如下图所示
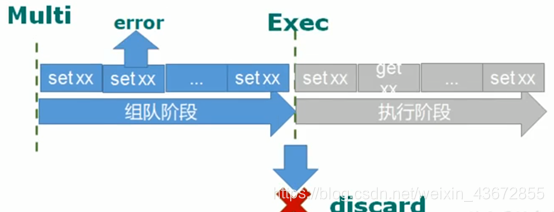

1.4 命令
DISCARD
取消事务,放弃执行事务块内的所有命令。
EXEC
执行所有事务块内的命令。
MULTI
标记一个事务块的开始。
UNWATCH
Redis Unwatch 命令用于取消 WATCH 命令对所有 key 的监视。
如果在执行WATCH命令之后,EXEC命令或DISCARD命令先被执行的话,那就不需要再执行UNWATCH了
WATCH key [key ...]
监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。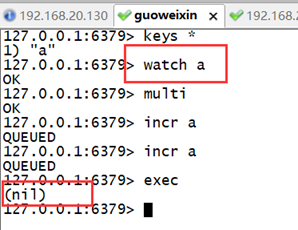

1.5 回滚
Redis 不支持回滚(roll back)
- 只有当发生语法错误(这个问题在命令队列时无法检测到)了,Redis命令才会执行失败, 或对keys赋予了一个类型错误的数据:这意味着这些都是程序性错误,这类错误在开发的过程中就能够发现并解决掉,几乎不会出现在生产环境。
- 由于不需要回滚,这使得Redis内部更加简单,而且运行速度更快。
1.6 应用场景
- 一组命令必须同时都执行,或者都不执行。
- 我们想要保证一组命令在执行的过程之中不被其它命令插入。
例如:商品秒杀(活动)。
二. redis脚本
Redis 脚本使用 Lua 解释器来执行脚本。 Redis 2.6 版本通过内嵌支持 Lua 环境。执行脚本的常用命令为 EVAL。
三. Redis数据淘汰策略redis.conf
Redis官方给的警告,当内存不足时,Redis会根据配置的缓存策略淘汰部分Keys,以保证写入成功。当无淘汰策略时或没有找到适合淘汰的Key时,Redis直接返回out of memory错误。
最大缓存配置
在 redis 中,允许用户设置最大使用内存大小maxmemory 512G
redis 提供6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰volatile-lfu:从已设置过期的Keys中,删除一段时间内使用次数最少使用的volatile-ttl:从已设置过期时间的数据集中挑选最近将要过期的数据淘汰volatile-random:从已设置过期时间的数据集中随机选择数据淘汰allkeys-lru:从数据集中挑选最近最少使用的数据淘汰allkeys-lfu:从所有Keys中,删除一段时间内使用次数最少使用的allkeys-random:从数据集中随机选择数据淘汰no-enviction(驱逐):禁止驱逐数据(不采用任何淘汰策略。默认即为此配置),针对写操作,返回错误信息
建议:了解了Redis的淘汰策略之后,在平时使用时应尽量主动设置/更新key的
expire时间,主动剔除不活跃的旧数据,有助于提升查询性能
四. Redis持久化
数据存放于:
内存:高效、断电(关机)内存数据会丢失
硬盘:读写速度慢于内存,断电数据不会丢失
4.1 持久化方式
4.1.1 RDB
RDB:是redis的默认持久化机制。RDB相当于照快照,保存的是一种状态。
几十G数据 --> 几KB快照
快照是默认的持久化方式。这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
优点:
- 快照保存数据极快、还原数据极快
- 适用于灾难备份
缺点:
- 小内存机器不适合使用,RDB机制符合要求就会照快照
4.1.1.1 启动方式
- 服务器正常关闭时
./bin/redis-cli shutdown key满足一定条件,会进行快照
vim redis.conf搜索save
:/save
save 900 1//每900秒(15分钟)至少1个key发生变化,产生快照
save 300 10//每300秒(5分钟)至少10个key发生变化,产生快照
save 60 10000//每60秒(1分钟)至少10000个key发生变化,产生快照
4.1.2 AOF
由于快照方式是在一定间隔时间做一次的,所以如果redis 意外down 掉的话,就会丢失最后一次快照后的所有修改。如果应用要求不能丢失任何修改的话,可以采用aof 持久化方式。
Append-only file:aof 比快照方式有更好的持久化性,是由于在使用aof 持久化方式时,redis 会将每一个收到的写命令都通过write 函数追加到文件中(默认是appendonly.aof)。当redis 重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。
4.1.2.1 启动方式
有三种方式如下(默认是:每秒 fsync 一次) appendonly yes -启用 aof 持久化方式
appendfsync always//收到写命令就立即写入磁盘,最慢,但是保证完全的持久化appendfsync everysec//每秒钟写入磁盘一次,在性能和持久化方面做了很好的折中appendfsync no//完全依赖 os,性能最好,持久化没保证
4.1.2.2 产生的问题
aof 的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用 incr test命令 100 次,文件中必须保存全部的 100 条命令,其实有 99 条都是多余的。
五. redis与mysql一致性问题
5.1 解决方案
5.1.1 实时同步
对强一致要求比较高的,应采用实时同步方案,即查询缓存查询不到再从DB查询,保存到缓存;更新缓存时,先更新数据库,再将缓存的设置过期(建议不要去更新缓存内容,直接设置缓存过期)。
@Cacheable:查询时使用,注意Long类型需转换为Sting类型,否则会抛异常
@CachePut:更新时使用,使用此注解,一定会从DB上查询数据
@CacheEvict:删除时使用;
@Caching:组合用法
5.1.2 异步队列
对于并发程度较高的,可采用异步队列的方式同步,可采用kafka等消息中间件处理消息生产和消费。
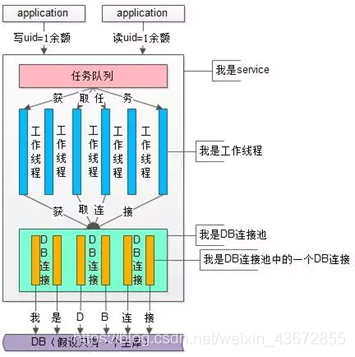
5.1.3 使用阿里的同步工具canal
canal实现方式是模拟mysql slave和master的同步机制,监控DB bitlog的日志更新来触发缓存的更新,此种方法可以解放程序员双手,减少工作量,但在使用时有些局限性。
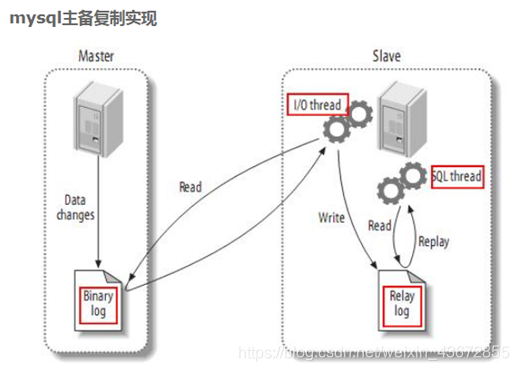
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
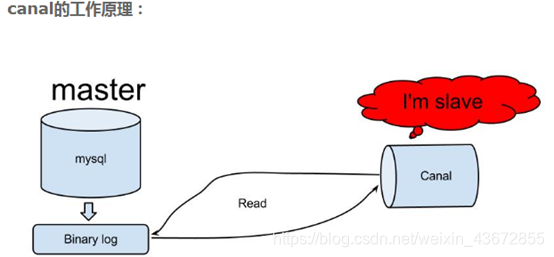
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
5.1.4 采用UDF自定义函数的方式
面对mysql的API进行编程,利用触发器进行缓存同步,但UDF主要是c/c++语言实现,学习成本高。
5.1.5 使用定时器
定时将redis 数据同步到数据库中。
六. 缓存穿透、缓存雪崩、缓存击穿(热点Key)
6.1 缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,如果数据库也查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
解决办法: 持久层查询不到就缓存空结果,查询时先判断缓存中是否exists(key) ,如果有直接返回空,没有则查询后返回,
简单的伪代码如下:
//首先到redis中查询数据
if(redis.exist(key)){
String str = redis.get(key);
//如果为空字符串那么直接返回null
if(str == ""){
return null;
}
//不是的话直接返回该字符串
return str;
//redis 没有数据则到DB中查找
}else{
String value = selectFromDB(key);
//如果数据库也没有,那么在redis中也要设置一个key,同时设置失效时间
//这样下次查询的时就走redis
if(value == null){
reids.set(key, "");
return null;
}
redis.set(key, value);
return value;
}
注意:
insert时需清除查询的key,否则即便DB中有值也查询不到(当然也可以设置空缓存的过期时间)
6.2 缓存雪崩
在某一个时间段,缓存集中大量失效时,引发大量查询数据库。
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
在做电商项目的时候,一般是采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。
6.3 缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
解决办法:
- 使用锁,单机用
synchronized,lock等,分布式用分布式锁。 - 缓存过期时间不设置,而是设置在key对应的
value里。如果检测到存的时间超过过期时间则异步更新缓存。 - 在
value设置一个比过期时间t0小的过期时间值t1,当t1过期的时候,延长t1并做更新缓存操作。 - 设置标签缓存,标签缓存设置过期时间,标签缓存过期后,需异步地更新实际缓存
