CNN实现手写数字识别
CNN手写数字识别中的Loss为分类Loss,采用交叉熵来表示。
原理解析
图像经过多层卷积、池化操作后,输出为一个长度为10的向量,即tf.matmul(h_fc1_drop, W_fc2) + b_fc2,为了衡量该结果与样本实际label的差值大小,需要进行一定的处理。首先,使用softmax将特征值转为各个类别的概率值,确保预测值和真实值具有可比性。然后,计算
# softmax:用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类。假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
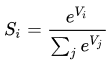
假如网络模型输出的向量是[3, 1, -3],通过以上函数的计算,向量被转化成了[0.88, 0.12, 0],结果向量的三个数值之和刚好等于1,我们可以把这三个值视为结果归属于三个类别的概率值。
softmax详细介绍可以参考 https://www.zhihu.com/question/23765351
# cross_entropy:信息熵是信息论中的概念,它认为一切信息都是一个概率分布。所谓信息熵,就是这段信息的不确定性,即是信息量。如果一段信息,我无论怎么解读都正确,就没有信息量。如果一个信息,我正确解读的概率极低,就包含了极大信息量。这个信息量即是一段信息的不确定性即是“信息熵”。
为了衡量计算概率和真实概率两种概率分布的差值大小,我们引入了交叉熵这个概念。交叉熵可以度量我们所预估事情的错误程度,也即Loss。信息熵是交叉熵的最理想情况。以MNIST手写数字识别为例,真实的数字1样本的概率分布为[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],而我们所预测的概率分布为[0.1, 0.85, 0, 0, 0, 0, 0, 0, 0.05, 0],它的交叉熵可以通过以下定义来计算:
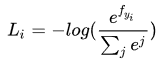
公式括号中的内容为softmax值,也就是我们所预测的概率分布,那么它的交叉熵为Li = -log(0.85),所有样本的交叉熵相加则最终得到所有训练样本/整个batch的训练样本的Loss。理想的情况是概率分布为1,则其交叉熵为0,当所预测值小于1时,则log值小于0,log取负得到正的Loss值,其绝对值越小也就意味着Loss越小。
交叉熵的详细介绍可参看 https://www.jianshu.com/p/2e55dc056896
代码解析:
# ==================================================== #
# 1、softmax层,网络结构略去
# ==================================================== #
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_predict = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# ==================================================== #
# 2、Loss,交叉熵
# ==================================================== #
cross_entropy = -tf.reduce_sum(y_actual * tf.log(y_predict))
# ==================================================== #
# 过程模拟
# ==================================================== #
#1 softmax层
# 比如一个batch有四个样本,他们预测的结果的softmax值如下:
# [0.1, 0.85, 0, 0, 0, 0, 0, 0, 0.05, 0] 样本实际值为1
# [0, 0, 0, 0.9, 0, 0, 0, 0, 0.1, 0] 样本实际值为3
# [0.92, 0, 0, 0, 0, 0, 0, 0, 0.08, 0] 样本实际值为0
# [0, 0, 0, 0, 0, 0.7, 0, 0, 0, 0.3] 样本实际值为5
#2 交叉熵
# 第一步,计算y_actual * log(y_predict)得到:
# 1 * log(0.85)
# 1 * log(0.9)
# 1 * log(0.92)
# 1 * log(0.7)
# 第二步,将所有交叉熵相加,取反
# -(log(0.85) + log(0.9) + log(0.92) + log(0.7))
# tf.reduce_sum(input_tensor, axis)
# 降维求和
# axis省略时,所有元素求和
# axis=0时,按列求和
# axis=1时,按行求和
# 可参考 https://www.jianshu.com/p/d34adf0b77ad
VGG16实现图像分类
VGG16本质上还是深度卷积神经网络,且它只是解决了仅包含一类物体的图像分类问题,其Loss也只由分类误差决定。和类似于LeNet-5等简单网络一样,VGG16的Loss也是通过计算预测结果和实际Label的交叉熵来实现。
源码分析
# ==================================================== #
# 1、网络结构略去,网络输出的特征值logits
# ==================================================== #
logits = fc_op(fc7_drop, name="fc8", n_out=3)
# ==================================================== #
# 2、Loss,softmax -> cross_entropy ->reduce_mean
# ==================================================== #
Loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
# ==================================================== #
# 3、过程模拟
# ==================================================== #
#1 网络输出的特征值logits
# [3, -1, -3]
# [2, -1, 4]
# [-2, 3, 1]
#2 softmax,logits转概率
# [0.979, 0.018, 0.003] 样本实际值为第0类,对应的label为[1, 0, 0]
# [0.118, 0.005, 0.877] 样本实际值为第2类,对应的label为[0, 0, 1]
# [0.006, 0.876, 0.118] 样本实际值为第1类,对应的label为[0, 1, 0]
#2 cross_entropy,计算每个样本的交叉熵
# 1 * log(0.979)
# 1 * log(0.877)
# 1 * log(0.876)
#2 reduce_mean,求和并计算平均交叉熵啊
# (log(0.979) + log(0.877) + log(0.876)) / 3
# tf.nn.softmax_cross_entropy_with_logits()可以参考 https://zhuanlan.zhihu.com/p/51431626
# tf.one_hot()可以参考 https://www.jianshu.com/p/c5b4ec39713b
