1、Java集合体系
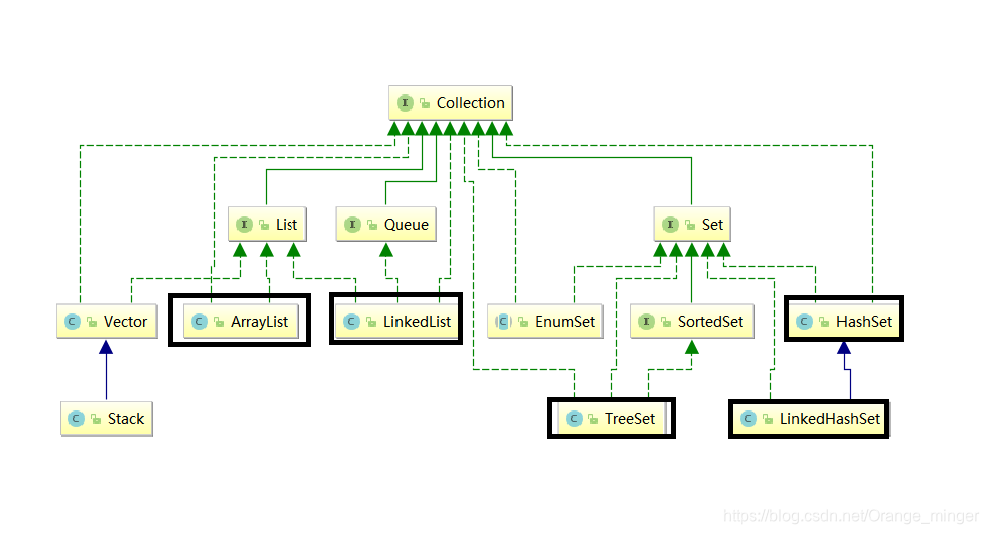
Java集合体系主要由两个接口派生而出:Collection和Map。Collection及其实现类存储的数据均是单列的,而Map及其实现类均是双列的k-v键值对形式。Collection和Map的实现类很多,在不同的应用场景均有应用,学习Java集合一定要会对这个体系进行分类学习,才能有效地掌握它们!
2、Collection体系
Collection是一个接口,定义了一系列的集合操作方法,其实现类主要是重写抽象方法和定义自己特定的方法。该体系的实现类都是直接或间接实现Collection的三个子接口:List、Queue、Set。我们常用的实现类主要有ArrayList、LinkedList、TreeSet、HashSet。
2.1、List接口及其实现类
2.1.1、List
List接口的主要方法如下:
public void add(int index, E element) :将指定的元素,添加到该集合中的指定位置上。
public E get(int index) :返回集合中指定位置的元素。
public E remove(int index) : 移除列表中指定位置的元素, 返回的是被移除的元素。
public E set(int index, E element) :用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
//1.使用多态思想,创建List集合对象
List<String> list = new ArrayList<>();
//2.往尾部添加制定元素
boolean a = list.add("小明");
boolean b = list.add("小红");
boolean c = list.add("小刚");
//3.输出集合
System.out.println("list = " + list);
//4.删除指定索引的元素,并返回被删除的元素
String removeElement = list.remove(2);
System.out.println("removeElement = " + removeElement);
//5.获取指定位置的元素
String getElement = list.get(1);
System.out.println("getElement = " + getElement);
//6.修改指定位置的元素
String setElement = list.set(1, "小严");
System.out.println("setElement = " + setElement);
2.1.2、ArrayList
ArrayList 集合数据存储的结构是数组(关于数组与链表的区别,请查询数据结构)。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。想对ArrayList深入了解的,应该查看它的源码。
查看源码可知,类中定义了private static final int DEFAULT_CAPACITY = 10;与private int size;其中DEFAULT_CAPACITY表示初始容量为10,size表示当前列表的存储的数据数量。类中有多个构造方法,若是指定容量,则使用指定的数字创建ArrayList,否则使用默认数量10为初始化容量。
其他的一些常用方法均可根据方法名与形参列表了解用法,若是想深入了解就查看源码。
2.1.3、LinkedList
LinkedList 集合数据存储的结构是链表。元素增删快,查找慢。
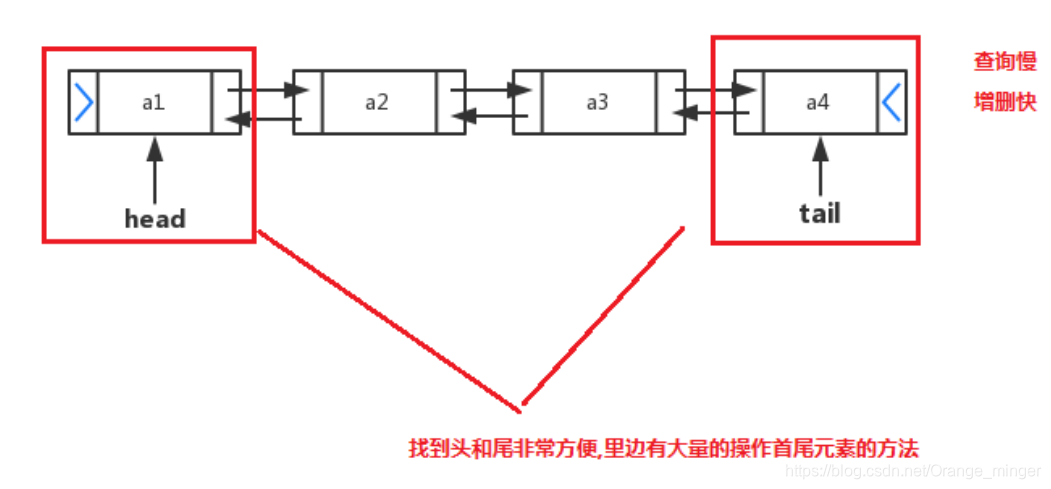
实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。
public void addFirst(E e) :将指定元素插入此列表的开头。
public void addLast(E e) :将指定元素添加到此列表的结尾。
public E getFirst() :返回此列表的第一个元素。
public E getLast() :返回此列表的最后一个元素。
public E removeFirst() :移除并返回此列表的第一个元素。
public E removeLast() :移除并返回此列表的最后一个元素。
public E pop() :从此列表所表示的堆栈处弹出一个元素。
public void push(E e) :将元素推入此列表所表示的堆栈。
public boolean isEmpty() :如果列表不包含元素,则返回true。
由于LinkedList特殊的结构和方法,我们可以利用它来定义栈和队列,具体实现代码如下
public class Stack<E> {
//定义一个linkedlist集合
private LinkedList<E> list = new LinkedList<>();
//入栈,链表的头为栈顶
public void push(E e) {
list.addFirst(e);
}
//出栈,并返回被出栈的元素
public Object pop() {
E e = list.removeFirst();
return e;
}
//栈的大小
public int size() {
return list.size();
}
//查看栈顶元素
public E peak(){
return list.getFirst();
}
//集合是否为空
public boolean isEmpty(){
int size = this.size();
if (size == 0){
return true;
}
return false;
}
public String toString(){
return list.toString();
}
}
public class Quene<E> {
private LinkedList<E> list = new LinkedList<>();
//入队,链表的头为队头
public void push(E e) {
list.addLast(e);
}
//出队
public E pop() {
return list.removeFirst();
}
//队列的大小
public int size() {
return list.size();
}
//查看队头元素
public E peak(){
return list.getFirst();
}
//查看队尾元素
public E rear(){
return list.getLast();
}
//队列是否为空
public boolean isEmpty(){
int size = this.size();
if (size == 0){
return true;
}
return false;
}
public String toString(){
String s = list.toString();
return s;
}
}
2.2、Set接口及其实现类
2.2.1、Set
Set 接口和 List 接口一样,同样继承自 Collection 接口,它与 Collection 接口中的方法基本一致,并没有对 Collection 接口进行功能上的扩充,只是比 Collection 接口更加严格了。与 List 接口不同的是,Set 接口中元素无序,并且都会以某种规则保证存入的元素不出现重复。Set 集合有多个子类,这里我们介绍其中的 HashSet 、LinkedHashSet 这两个集合。
2.2.2、HashSet
java.util.HashSet 是 Set 接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。查看源码可知, HashSet 底层的实现其实是一个 HashMap 支持,只是将其中value固定了,把key作为HashSet的值。HashSet 是根据对象的哈希算法(详情查看数据结构)来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性 的方式依赖于:hashCode 与 equals 方法。要想了解HashSet,应该使用HashSet分别储存Integer类型、String类型、自定义对象类型来研究HashSet。
public static void main(String[] args) {
HashSet<Integer> set = new HashSet<Integer>();
set.add(1);
set.add(3);
set.add(2);
set.add(1);
System.out.println("set = " + set);
}
结果输出为set = [1, 2, 3],说明元素添加的无序且不重复的。
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2);//false
String s3 = new String("ccc");
String s4 = new String("ddd");
set.add(s1);
set.add(s2);
set.add(s3);
set.add(s4);
System.out.println("set = " + set);
}
结果输出为set = [aaa, ccc, ddd]。由于String类型是引用类型,所以s1与s2的地址不同,但由于String重写了equals方法,所以HashSet认为二者是相同的。
public class Student {
//未重写equals和hashCode方法
private int age; //
private String name; //
public Student(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
public static void main(String[] args) {
HashSet<Student> set = new HashSet<>();
Student stu1 = new Student(23, "小明");
Student stu2 = new Student(23, "小明");
Student stu3 = new Student(24, "小红");
set.add(stu1);
set.add(stu2);
set.add(stu3);
System.out.println("set = " + set);
}
}
定义的Student没有重写equals方法,所以HashSet判断两个student对象是否相同是根据地址值是否相同来判定的(Object类的原始equals方法)。所以结果输出为set = [Student{age=23, name=‘小明’}, Student{age=23, name=‘小明’}, Student{age=24, name=‘小红’}]。
利用IDEA生成equals和hashCode方法,得出的结果为set = [Student{age=23, name=‘小明’}, Student{age=24, name=‘小红’}]。
2.2.3、LinkedHashSet
我们知道HashSet保证元素唯一,可是元素存放进去是没有顺序的,那么我们要保证有序,怎么办呢? 在HashSet下面有一个子类LinkedHashSet ,它是链表和哈希表组合的一个数据存储结构,保证了存取一致。其它的用法与HashSet几乎一致。
2.2.4、TreeSet
TreeSet底层是二叉树,可以对对象元素进行排序,但是自定义类需要实现comparable接口,重写comparaTo() 方法。TreeSet 可以保证对象元素的唯一性(并不是一定保证唯一性,需要根据重写的compaaTo方法来确定)。下面演示存储integer类型和自定义对象类型。
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
set.add(1);
set.add(2);
set.add(3);
set.add(5);
set.add(1);
set.add(4);
System.out.println("set = " + set);
}
结果输出set = [1, 2, 3, 4, 5]
public class Student implements Comparable{
private int age; //
private String name; //
public Student(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
@Override
public int compareTo(Object o) {
Student student = (Student)o;//向下转型
return this.age - student.age;//按年龄排序
}
public static void main(String[] args) {
TreeSet<Student> set = new TreeSet<>();
set.add(new Student(23, "小明"));
set.add(new Student(24, "小明"));
set.add(new Student(25, "小明"));
System.out.println("set = " + set);
}
}
2.3、Queue
Queue是实现队列的类,但现在使用很少了。重点还是在List和Set上
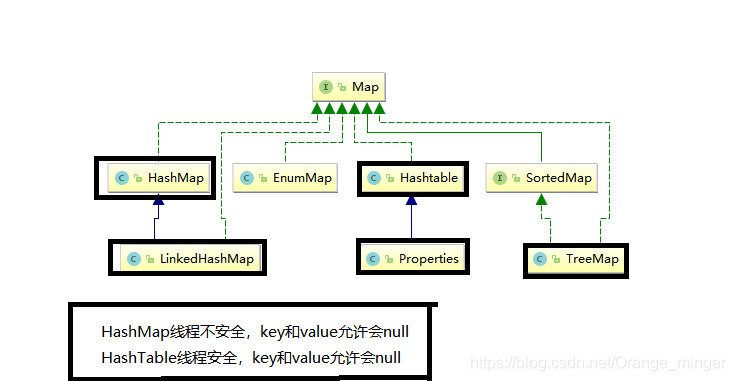
3、Map体系
3.1、Map
Map用于保存具有映射关系的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,一组保存Map里的value,key和value都可以是任何引用类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较总会返回false。
key和value之间存在着单向的一对一的关系,通过指定的key,能够找到对应的value。Map中存在一个keySet()方法,能够获得所有的key,由于key不能重复且无序,所以本质上key集合就是一个set集合,而value看起来则像是一个list集合。
Map接口常用方法:
void clear():删除该Map对象的所有k-v对
boolean containsKey(Object key):查询该Map对象是否包含指定的Key
boolean containsValue(Object value):查询该Map对象是否包含指定的value
Set entrySet():返回该Map对象包含的k-v对所组成的Set集合,Set集合元素都是Map.Entry(Entry是Map的内部类)对象
Object get(Object key):返回指定key对应的value;如果该Map对象不包含该key,则返回null
boolean isEmpty():查询该Map对象是否为空
Set keySet():返回该Map对象所有key组成的Set集合
Object put(Object key,Object value):向该Map对象添加一对k-v对
Object remove(Object key):删除指定key所对应k-v对
boolean remove(Object key, Object value):删除指定key和value所对应k-v对,成功删除则返回True
int size():返回该Map对象的k-v对个数
3.2、HashMap和Hashtable
HashMap和Hashtable都是Map接口的实现类,类似于ArrayList和Vector的关系。在实际开发中,HashMap使用率要远远大于Hashtable。从命名规则来看,可知道Hashtable是个古老的类(没有遵从如今的命名规范)。
想要在HashMap和Hashtable中存储数据,用作key的对象必须实现hashCode()方法和equals()方法。
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
import java.util.Set;
/**
* @author RuiMing Lin
* @date 2020-03-05 16:01
*/
public class Person {
//使用Person类所为key
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
return getAge() == person.getAge() &&
Objects.equals(getName(), person.getName());
}
@Override
public int hashCode() {
return Objects.hash(getName(), getAge());
}
public static void main(String[] args) {
HashMap<Person, String> hmap = new HashMap<>();
hmap.put(new Person("小明", 18), "是个坏学生");
hmap.put(new Person("小红", 17), "是个好学生");
hmap.put(new Person("小刚", 19), "是个学霸");
Set<Map.Entry<Person, String>> entrySet = hmap.entrySet();
for (Map.Entry<Person, String> entry : entrySet) {
Person person = entry.getKey();
String string = entry.getValue();
System.out.println("person = " + person + "..." + "string = " + string);
}
}
}
3.3、LinkedHashMap
LinkedHashMap是HashMap的一个子类,用法几乎一样,只是存储顺序的实现方法不同。LinkedHashMap的底层是使用哈希表与双向链表来保存所有元素,所以LinkedHashMap的迭代顺序和插入顺序一致。
import java.security.Key;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
/**
* @author RuiMing Lin
* @date 2020-03-05 16:14
*/
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<String,Integer> lsmap = new LinkedHashMap();
lsmap.put("小明", 18);
lsmap.put("小红", 19);
lsmap.put("小刚", 20);
Set<Map.Entry<String, Integer>> entrySet = lsmap.entrySet();
for (Map.Entry<String, Integer> entry : entrySet) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("key = " + key + "..." + "value = " + value);
}
}
}
3.4、SortedMap和TreeMap
SortedMap和TreeMap的原理与上面的SortedSet和TreeSet一样,不了解的请回去翻翻看。
4、集合遍历
4.1、List遍历方式一
import java.util.ArrayList;
/**
* @author RuiMing Lin
* @date 2020-03-05 16:38
*/
public class Demo2 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(2);
list.add(3);
//遍历方式一:普通for循环
for(int i = 0;i < list.size(); i++) {
System.out.print(list.get(i) + " ");
}
System.out.println();
//使用遍历方式一进行删除所有为2的元素
for(int i=0; i<list.size(); i++) {
if (2 == list.get(i)) {
list.remove(i);
}
}
System.out.println("list.toString() = " + list.toString());
}
}
结果为:
1 2 2 3
list.toString() = [1, 2, 3]
此时便出现了一个错误:有一个2未被删除。原因是当删除一个元素时,后面元素的索引就会被修改(index = index - 1),如删除第一个2时候,此时下一个元素2的索引由原来的索引为2变为1,而此时for循环执行i++,对应索引的位置为2而新的1索引上的值就不会在读取了,所以结果为【1,2,3】。要解决这个问题很容易,需要把 list.remove(i)改为list.remove(i - -)。
4.2、List遍历方式二
import java.util.ArrayList;
import java.util.Iterator;
/**
* @author RuiMing Lin
* @date 2020-03-05 16:38
*/
public class Demo2 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(2);
list.add(3);
//遍历方式二:使用迭代器
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()){
Integer next = iterator.next();
System.out.println("next = " + next);
if (next == 2){
//务必使用Iterator的remove()
iterator.remove();
}
}
System.out.println("list.toString() = " + list.toString());
}
}
删除元素过程中务必使用Iterator的remove(),若是使用集合的remove(),迭代器便会检测到集合的内容发生改变,便会报出并发修改异常。
4.3、List遍历方式三
import java.util.ArrayList;
import java.util.Iterator;
/**
* @author RuiMing Lin
* @date 2020-03-05 16:38
*/
public class Demo2 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(2);
list.add(3);
//遍历方式三:使用增强for循环
for (Integer integer : list) {
System.out.println("integer = " + integer);
}
System.out.println("list.toString() = " + list.toString());
}
}
使用增强for循环无法删除元素,因为集合删除元素需要提供索引。
4.4、Map遍历方式一
import java.util.LinkedHashMap;
import java.util.Set;
/**
* @author RuiMing Lin
* @date 2020-03-05 16:14
*/
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<String,Integer> lsmap = new LinkedHashMap();
lsmap.put("小明", 18);
lsmap.put("小红", 19);
lsmap.put("小刚", 20);
Set<String> keySet = lsmap.keySet();
for (String key : keySet) {
Integer integer = lsmap.get(key);
System.out.println("integer = " + integer);
}
}
}
使用Map集合的keySet()获取所有的key,再通过key获取value
4.5、Map遍历方式二
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
import java.util.Set;
/**
* @author RuiMing Lin
* @date 2020-03-05 16:01
*/
public class Person {
//使用Person类所为key
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
return getAge() == person.getAge() &&
Objects.equals(getName(), person.getName());
}
@Override
public int hashCode() {
return Objects.hash(getName(), getAge());
}
public static void main(String[] args) {
HashMap<Person, String> hmap = new HashMap<>();
hmap.put(new Person("小明", 18), "是个坏学生");
hmap.put(new Person("小红", 17), "是个好学生");
hmap.put(new Person("小刚", 19), "是个学霸");
Set<Map.Entry<Person, String>> entrySet = hmap.entrySet();
for (Map.Entry<Person, String> entry : entrySet) {
Person person = entry.getKey();
String string = entry.getValue();
System.out.println("person = " + person + "..." + "string = " + string);
}
}
}
通过获取Map的内部类Entry获取所有的k-v对,再通过Entry的getKey()和getValue()获取key和value。
4.6、Map遍历两种方式的比较
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @author RuiMing Lin
* @date 2020-02-29 16:03
*/
public class Demo1 {
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
for (int i = 0; i < 100000000; i++) {
// 向map集合添加100w条数据
map.put(i, "num" + i);
}
for (int i = 1; i <= 5; i++) {
long time = entryTime(map);
System.out.println("使用entrySet()第" + i + "次花费时间为" + time + "ms");
}
for (int i = 1; i <= 5; i++) {
long time = keyTime(map);
System.out.println("使用keySet()第" + i + "次花费时间为" + time + "ms");
}
}
public static long entryTime(HashMap<Integer, String> map) {
long start = System.currentTimeMillis();
Set<Map.Entry<Integer, String>> entrySet = map.entrySet();
for (Map.Entry<Integer, String> entry : entrySet) {
Integer key = entry.getKey();
String value = entry.getValue();
//System.out.println("key = " + key +"..." + "value = " + value);
}
long end = System.currentTimeMillis();
return end - start;
}
public static long keyTime(HashMap<Integer, String> map) {
long start = System.currentTimeMillis();
Set<Integer> keySet = map.keySet();
for (Integer key : keySet) {
String value = map.get(key);//keySet()花费时间的原因,需要遍历2次map集合
}
long end = System.currentTimeMillis();
return end - start;
}
}
结果输出为:
使用entrySet()第1次花费时间为158ms
使用entrySet()第2次花费时间为136ms
使用entrySet()第3次花费时间为153ms
使用entrySet()第4次花费时间为149ms
使用entrySet()第5次花费时间为152ms
使用keySet()第1次花费时间为200ms
使用keySet()第2次花费时间为190ms
使用keySet()第3次花费时间为257ms
使用keySet()第4次花费时间为238ms
使用keySet()第5次花费时间为175ms
分析:结果可以看出使用keySet()获取值所需要的时间较长,原因在于它需要遍历两次map集合
5、总结
Java的集合体系几乎是面试必考的,同时也是Java基础中最重要的一部分。正如前言所说,Java体系庞大,一定要学会分类总结。同时,也要学会寻找内在联系,比如set和map的关系。最后,要多思考什么场景用什么容器合适,到底是使用最简单的数组就可以了?还是选择可变长度的List?或是选择不会有重复元素的Set?亦或是双列的Map?
有错误的地方敬请指出,欢迎大家评论区或者私信交流!每日持续更新Java、Python、大数据技术,请大家多多关注!
