前面已经部署好了HDFS, YARN比较容易了
1.修改配置文件
#vi etc/hadoop
官方已经提供了一个配置文件,直接拿来用
#cp mapred-site.xml.template mapred-site.xml
#vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
#vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2.启动Yarn
# sbin/start-yarn.sh

启动成功 打开 http://192.168.18.110:8088 看看 这是Yarn提供的UI视图

3.跑一个试试
hadoop安装好是有一些官方提供的例子的,跑一个
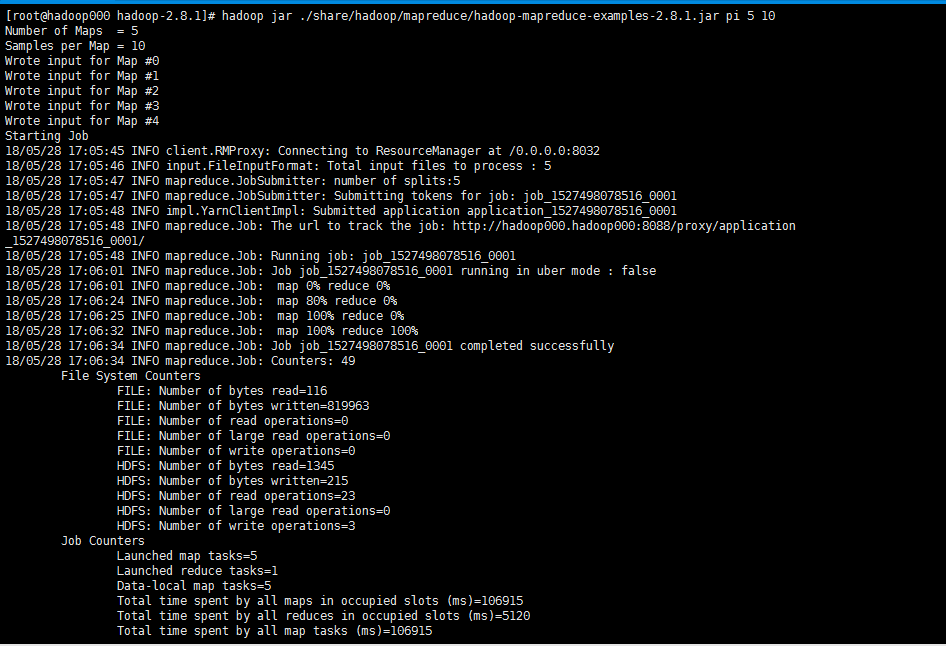
#hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar pi 5 10
可以看到计算结果以及整个任务过程
视图UI上也能看到我们刚才跑的任务
