1.线程是程序里面最小的执行单元。
2.进程是资源的集合。
线程是包含在进程里面的,一个进程可以有多个线程,但只要要有一个线程。
一.多线程,就是N个线程一起干活:
1.传统方式,串行,循环5次需要15s:
import threading,time def run():
time.sleep(3) #干活需要3s print('哈哈哈') for i in range(5): #串行 run()
2.使用多线程并发的方式,节省时间:
import threading,time
def run():
time.sleep(3) #干活需要3s
print('哈哈哈')
for i in range(5):#并发
t = threading.Thread(target=run) #实例化了一个线程,其中target=执行的函数名 t.start() #启动线程
举例:多线程爬虫,比较下并发和串行的时间:
串行方式:
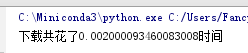
import threading,time,requests urls = { 'baidu':'http://www.baidu.com', 'hao123':'http://www.hao123.com', 'taobao':'https://www.taobao.com/' } def down_html(file_name,url): res = requests.get(url).content #返回二进制内容 open(file_name+'.html','wb').write(res) #因此打开的时候,用wb二进制打开 用串行方式 start_time = time.time() for k,v in urls.items(): down_html(k,v) end_time = time.time() run_time = end_time - start_time print('下载总共花了%s的时间'%run_time)
串行结果:
并行方式:
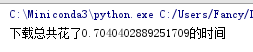
import threading,time,requests urls = { 'baidu':'http://www.baidu.com', 'hao123':'http://www.hao123.com', 'taobao':'https://www.taobao.com/' } def down_html(file_name,url): res = requests.get(url).content #返回二进制内容 open(file_name+'.html','wb').write(res) #因此打开的时候,用wb二进制打开 #用并行方式 start_time = time.time() for k,v in urls.items():#因为urls里有3个Key,因此会启动3个线程 t = threading.Thread(target=down_html,args=(k,v)) #使用多线程调用参数时,必须用args=xx才能传参 t.start() end_time = time.time() run_time = end_time - start_time print('下载共花了%s时间'%run_time)
并行结果: