for循环并行
概念性的东西可以参考c++ 对for循环的并行优化例子,此文中使用多线程对for循环进行了优化,并提出可能遇到的一些问题。
实际上for循环还有一种可用的优化方法是使用OpenMP来进行多线程的加速。OpenMp提供了对于并行描述的高层抽象,降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。
实际在一些开源库当中,大多数都使用OpenMP来进行多线程的优化,比如MNN和NCNN。今天介绍的是MNN中对for循环的并行处理。
这部分内容包含在MNN/source/core/Concurrency.h中。
Concurrency.h
MNN对并行处理进行了很好的封装,一个宏MNN_CONCURRENCY_BEGIN就可以对for循环并行处理。
//
// Concurrency.h
// MNN
//
// Created by MNN on 2018/07/26.
// Copyright © 2018, Alibaba Group Holding Limited
//
#ifndef concurrency_h
#define concurrency_h
#ifdef MNN_FORBIT_MULTI_THREADS //如果禁用多线程
#define MNN_CONCURRENCY_BEGIN(__iter__, __num__) for (int __iter__ = 0; __iter__ < __num__; __iter__++) {
#define MNN_CONCURRENCY_END() }
#elif defined(MNN_USE_THREAD_POOL) //使用线程池
#include "ThreadPool.hpp"
#define MNN_STRINGIFY(a) #a
#define MNN_CONCURRENCY_BEGIN(__iter__, __num__) \
{std::pair<std::function<void(int)>, int> task;task.second = __num__;\
task.first = [&](int __iter__) {\
#define MNN_CONCURRENCY_END() };\
auto cpuBn = (CPUBackend*)backend();\
MNN::ThreadPool::enqueue(std::move(task), cpuBn->taskIndex());}
#else //不使用线程池,使用操作系统和编程语言提供的多线程特性
// iOS / OSX
#if defined(__APPLE__) //在iOS上使用dispatch
#include <dispatch/dispatch.h>
#include <stddef.h>
#define MNN_CONCURRENCY_BEGIN(__iter__, __num__) \
dispatch_apply(__num__, dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^(size_t __iter__) {
#define MNN_CONCURRENCY_END() \
});
// Windows 在windows上使用openmp
#elif defined(_MSC_VER)
#include <omp.h>
#define MNN_CONCURRENCY_BEGIN(__iter__, __num__) \
__pragma(omp parallel for) for (int __iter__ = 0; __iter__ < __num__; __iter__++) {
#define MNN_CONCURRENCY_END() }
#define MNN_CONCURRENCY_BEGIN_CONDITION(__iter__, __num__, __condition__) \
int __iter__ = 0; \
__pragma(omp parallel for if(__condition__)) \
for (; __iter__ < __num__; __iter__++) {
// Android 在其他平台上使用openmp
#else
#include <omp.h>
#define MNN_STRINGIFY(a) #a
#define MNN_CONCURRENCY_BEGIN(__iter__, __num__) \
_Pragma("omp parallel for") for (int __iter__ = 0; __iter__ < __num__; __iter__++) {
#define MNN_CONCURRENCY_END() }
#endif
#endif
#endif /* concurrency_h */
OpenMP部分
重点是MNN_CONCURRENCY_BEGIN和MNN_CONCURRENCY_END两个宏定义
#define MNN_CONCURRENCY_BEGIN(__iter__, __num__) \
_Pragma("omp parallel for") for (int __iter__ = 0; __iter__ < __num__; __iter__++) {
#define MNN_CONCURRENCY_END() }
使用实例
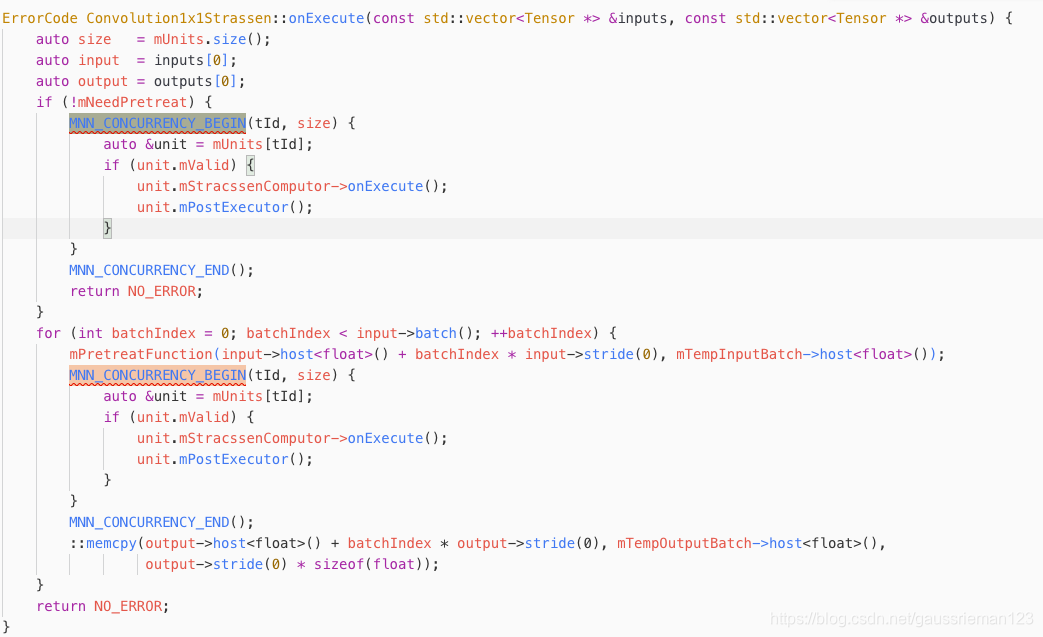
将第一个展开就是:
#pragma omp parallel for
for(int tid = 0; tid < size; tid++){
auto &unit = mUnits[tId];
if (unit.mValid) {
unit.mStracssenComputor->onExecute();
unit.mPostExecutor();
}
}
