本文我们主要讲解以下几个知识点:线性规划、评估指标、伴随矩阵、过拟合以及判别模型与生成模型等知识点。
- 设线性规划的约束条件为:
则基本可行解为 ()
A.(0, 0, 4, 3)
B.(3, 4, 0, 0)
C.(2, 0, 1, 0)
D.(3, 0, 4, 0)
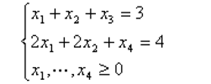
参考答案:C
解析: 这道题简单的做法就是直接代入即可。
2.在下面的数学模型中,属于线性规划模型的()
A.
B.
C.
D.
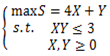
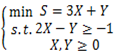
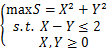
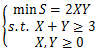
参考答案:B
解析:这道题的考点主要在于什么是线性规划,尤其是线性2字。线性就是指的是最普通的式子,只包含未知数之间只有加减的线性操作的式子。它是区别指数式等其他形式的说法。因此在目标函数和约束条件内,都不能有未知数之间的乘法。因此答案为B。
3.二分类任务中,有三个分类器h1,h2,h3,三个测试样本x1,x2,x3。假设1表示分类结果正确,0表示错误,h1在x1,x2,x3的结果分别(1,1,0),h2,h3分别为(0,1,1),(1,0,1),按投票法集成三个分类器,下列说法正确的是()
A. 集成提高了性能
B. 集成没有效果
C. 集成降低了性能
D. 集成效果不能确定
参考答案:A
解析:这道题三个注意点,一个是集成学习,一个是每个分类器的分类结果,一个是使用投票法。集成学习就是集思广益,看到多个分类器的结果后再做决定。第二个注意的就是每个分类器的结果如(1,1,0)指的是预测结果的正误,而不是预测结果。第三个是投票法,即少数服从多数的方法决定集成学习的最终结果。因此这题的答案是(1,1,1) 因为每一个样本都有2个分类器为1。答案选A。
4.有关机器学习分类算法的Precision和Recall,以下定义中正确的是(假定tp = true positive, tn = true negative, fp = false positive, fn = false negative)
A.Precision= tp / (tp + fp), Recall = tp / (tp + fn)
B.Precision = tp / (tn + fp), Recall = tp /(tp + fn)
C.Precision = tp / (tn + fn), Recall = tp /(tp + fp)
D.Precision = tp / (tp + fp), Recall = tp /(tn + fn)
参考答案:A
解析:这道题2个注意点,一个是PR的含义,一个是TP,TN,FP和FN的含义。
1、精确度(P)对应预测正确的(TP)占预测情况中正类(真正类TP+假正类FP)的比例;
2、召回率(R)对应预测正确的(TP)占真实情况正类(真正类TP+假负类FN)的比例。
这里比较难理解的是这4个类别,其实这四个类别都是针对预测结果而言的,所谓的真正类,指的是预测的正类是真,即预测结果为正,真是结果也为正。同理,假的负类指的是预测负类是假的。
5.下面哪些可能是一个文本语料库的特征()
1.一个文档中的词频统计
2.文档中单词的布尔特征
3.词向量
4.词性标记
5.基本语法依赖
6.整个文档
A.123
B.1234
C.12345
D.123456
参考答案:C
解析:首先要明白特征是什么,特征是指能够区分一个群体与其他群体的一些标记。那就知道了,首先特征是这个群体固有的属性,另外这些属性必须得是可以量化,具有一定普适性的。因此1,2,3,4,5都可以在不同方面表示一个文本语料库,而且它可以以一定方法进行度量的。反观6这个说法,一看就是出题人硬凑出来的,因为整个文档本身指代就不清楚,指的是每篇文档?还是整个语料库?另外,整个文档的什么?是文字?还是文章本身?最后,整个文档很难去和其他的东西进行一个比较和区分,是和另一个文本语料库的文字区分?还是说有无这篇文章?因此6不是特征。
- 设A为n阶方阵,且A的行列式
,而
是A的伴随矩阵,则
等于下列哪个选项?
A.a
B.1/a
C.
D.
参考答案:C
解析: 首先原题目的C和D被画成了矩阵的形式,给予了很大的误导。这里修正了回来,一个矩阵的行列值怎么也不可能是一个矩阵。然后,我们来了解一下什么是伴随矩阵,最后根据行列式性质得出解:
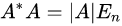
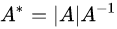
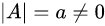
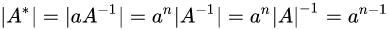

7.设
, 则当x---->1 时()
A.a(x)与b(x)是同阶无穷小,但不是等价无穷小
B.a(x)与b(x)是等价无穷小
C.a(x)是比b(x)高阶的无穷小
D.b(x)是比a(x)高阶的无穷小
参考答案:A
解析:本题的关键在于如何判定是等价无穷小还是同阶无穷小。其判断方法高数就已经学过,直接两者相除,如果是常数,则为同阶,如果是1,则是等价。高阶无穷小为分子更快的变为0(0),低阶无穷小为分母更快的变为0(无穷大)
8.在机器学习中,如果一味的去提高训练数据的预测能力,所选模型的复杂度往往会很高,这种现象称为过拟合。所表现的就是模型训练时候的误差很小,但在测试的时候误差很大,对于产生这种现象以下说法正确的是:()
A.样本数量太少
B.样本数量过多
C.模型太复杂
D.模型太简单
参考答案:AC
解析:这道题非常的简单,在题干中就已经给出了,模型的复杂度高,也就是模型太复杂,而且训练数据少也是过拟合的一个原因。其实这个说法并不严禁,因为样本如果很有代表性,则很少的样本也能够训练出很好的效果,但是如果很多样本都是比较相似的样本,也就是类别不平衡。那么很难训练出一个好模型出来。
9.下列模型属于机器学习生成式模型的是()
A.朴素贝叶斯
B.隐马尔科夫模型(HMM)
C.马尔科夫随机场(Markov Random Fields)
D.深度信念网络(DBN)
参考答案:ABCD
解析:本道题还是老知识要点,那就是什么样的模型是生成式模型,什么模型是判别式模型。判别式模型(Discriminative Model)是直接对条件概率p(y|x;θ)建模。常见的判别式模型有线性回归模型、线性判别分析、支持向量机SVM、神经网络等。
生成式模型(Generative Model)则会对x和y的联合分布p(x,y)建模,然后通过贝叶斯公式来求得p(yi|x),然后选取使得p(yi|x)最大的yi,常见的生成式模型有隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、狄利克雷分布模型(Latent Dirichlet Allocation,LDA)等。
