文章目录
HiveSQL
一、HiveSQL与传统SQL的区别
- 存储位置上:hivesql存储在hdfs上,传统SQL存储在块设备或者本地文件中
- 数据格式:hiveSQL的数据格式是由用户定义的:现在我的年龄10岁,我可以将10存储成文本string类型,不会因为我将他存储成文本型就不能做加减运算;传统SQL受限于系统。但是注意:如果将数字存储成string型他会按照文本的格式进行排序,其他的加减乘除不受限制
- 数据更新:hivesql不支持单条数据的修改删除,如果某一条出错只能全部导入
- 索引:hiveSQL没有索引,因此它的执行延迟非常高,比较慢(但是当数据规模非常大是不见得比MySQL慢),但是MySQL数据少的时候会比较快(hive 有分区)

二、MapReduce的工作流程
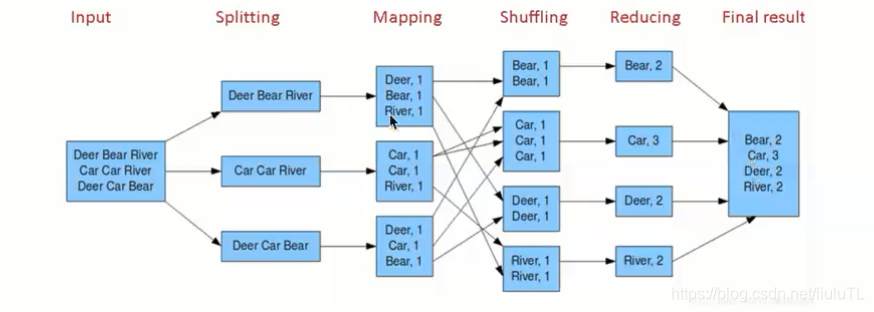
- 当我们吧数据输入的时候首先将数据进行拆分,数据分成多少分是由计算机决定的,用户虽然可以决定,但是不太了解的话就不要擅自改变了,如果自己改不好可能会执行的更加慢;
- 当分配(split)任务后,就到了map过程,读取每一个分块的数据,并把数据里中间键值对抽取出来,然后把中间键值存储在缓存中;
- 下一步将存储在缓存中的键值抽取出来进行shuffle,做一步排序工作,将相同的键值聚集在一起;
- reduce将键值提取,计算,比如bear有两个,最后输出。
基础语法
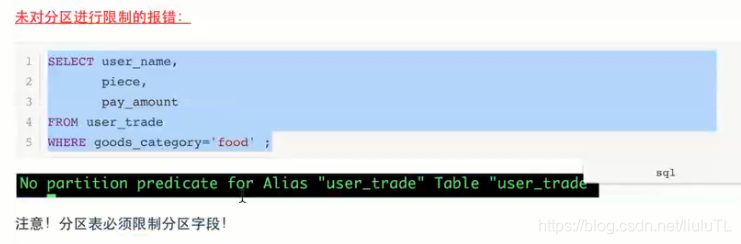
一、基础select(与SQL一样)+分区
select A from B where c
但对于分区表要加上分区条件 (也是在where后)时间是分区字段

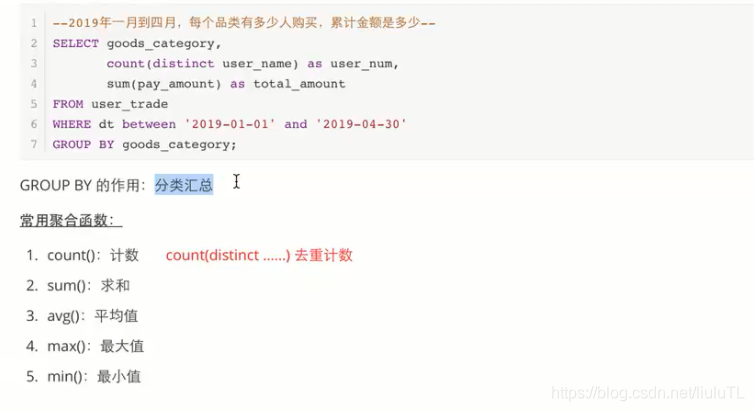
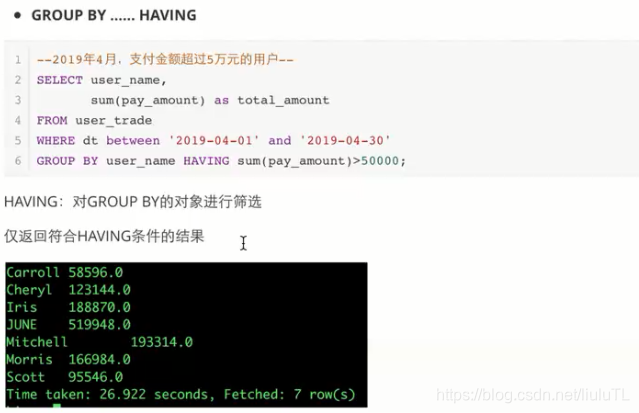
二、group by
拓展:UV就是人数(去重(一件商品一个人买两次就是按一个人,而人次就是2));PV就是人次
三、order by
hive不支持top函数,因此如果要选择前几名一定要使用order by .
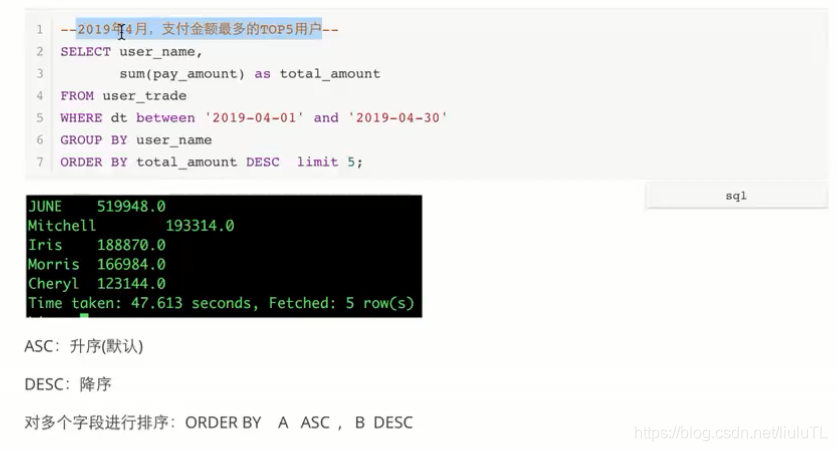
先计算求和,再进行排序
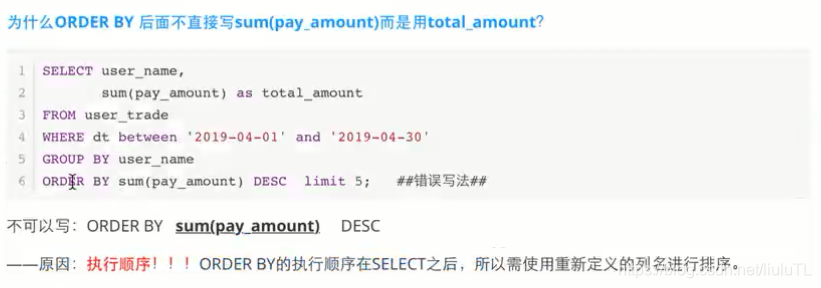
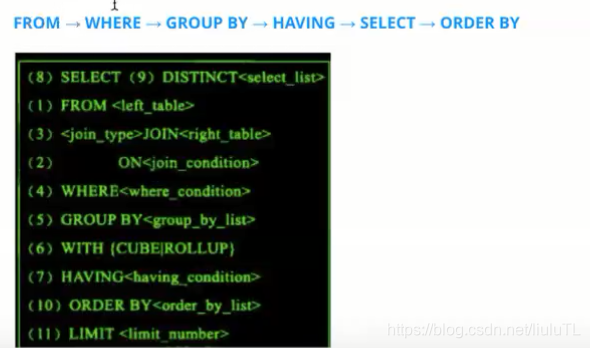
四、执行顺序
常用函数
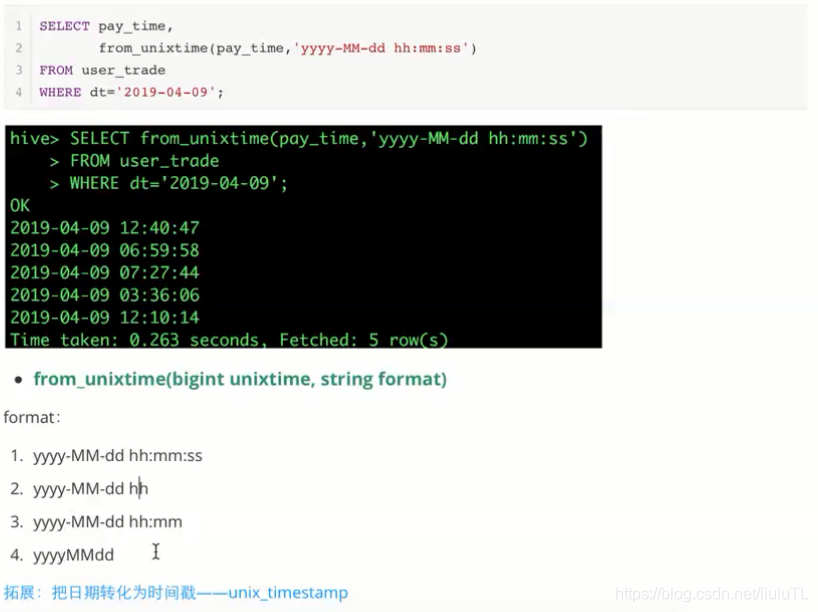
一、如何把时间戳转化成日期
二、如何计算日期间隔
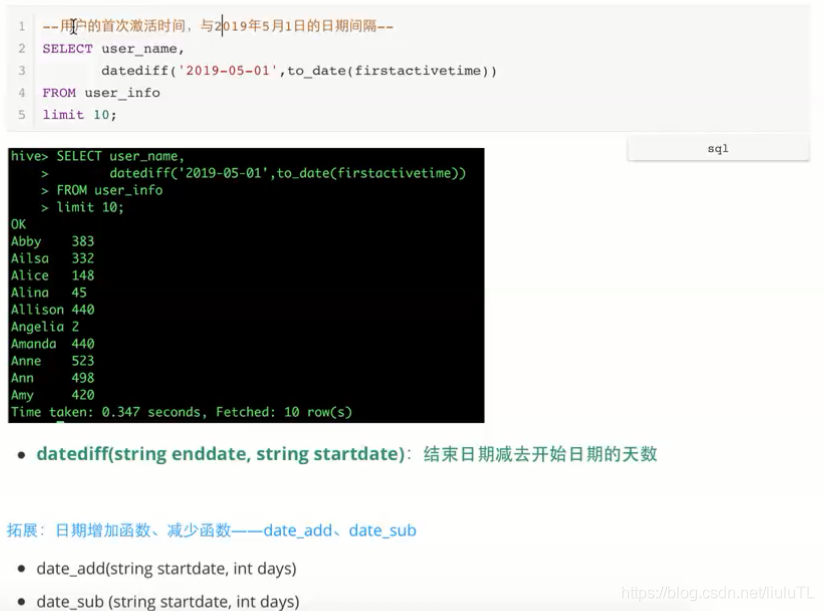
注:to_date :截取日期,不要小时等
三、条件函数
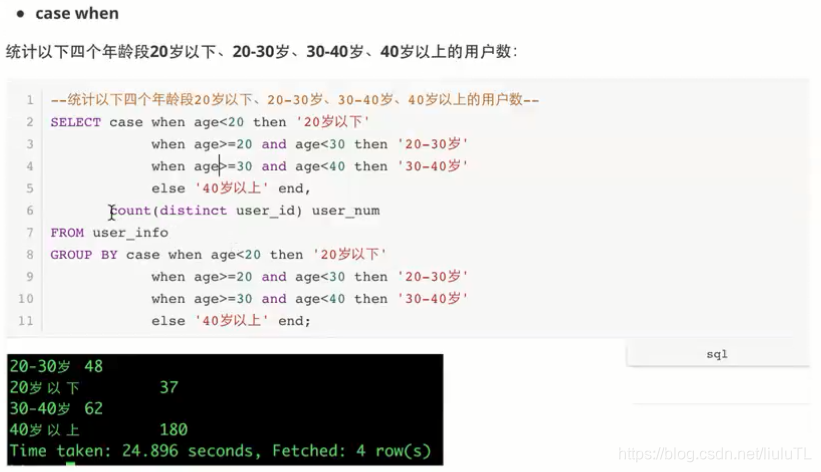
case when(每个条件之间都是相互独立的,没有交集)
所以不能计算20岁以下和18-30的,即使计算出来了,18-30中也没有18,19的
if函数
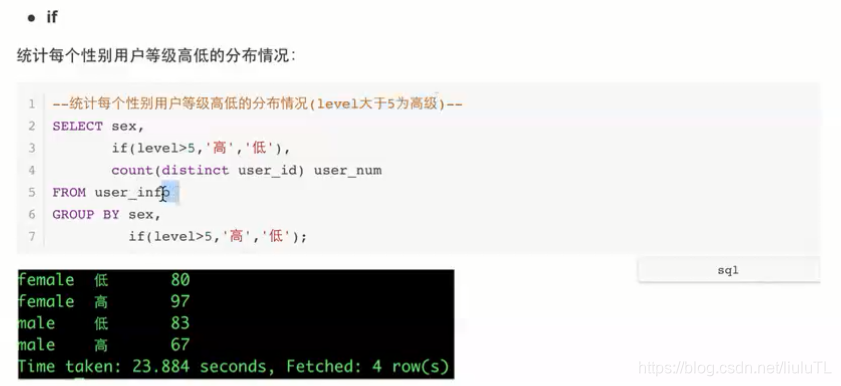
if(条件,a,b): 符合条件的会返回a,不符合会返回b。
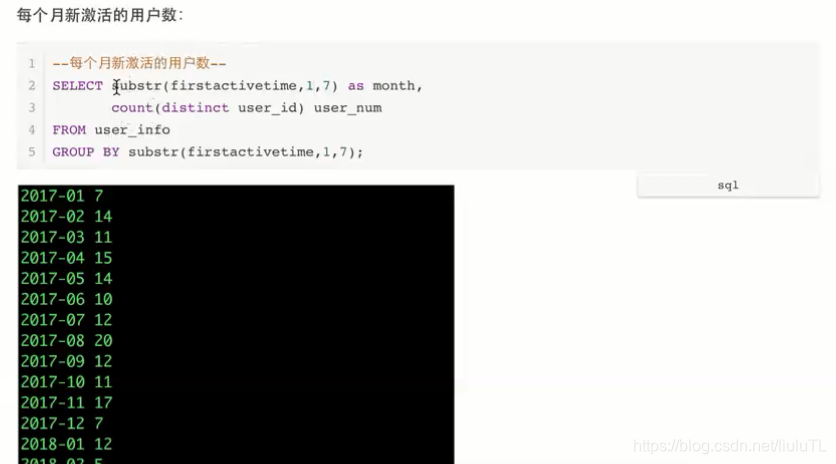
四、字符串函数(substr)
substr
substr(要截取的字段,1,7):从第1位开始截取,截取后面7个字段,不是1-7

2019-04-09 11:11:11,我想要截取04-09 11:11:11
substr(2019-04-09 11:11:11,6) 不指定第三个参数是一直截取到最后
get_json_object


extra1和extra2存储内容都是一样的,存的都是用户系统,学历等,只是类型不同,一个数string类型一个是map类型。key-value经常会用string和map来进行存储。

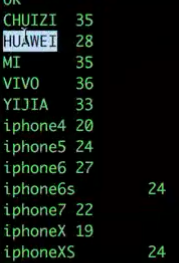
五、聚合统计函数
时间戳的间隔是秒间隔,我们要日期间隔需要用到正常的日期
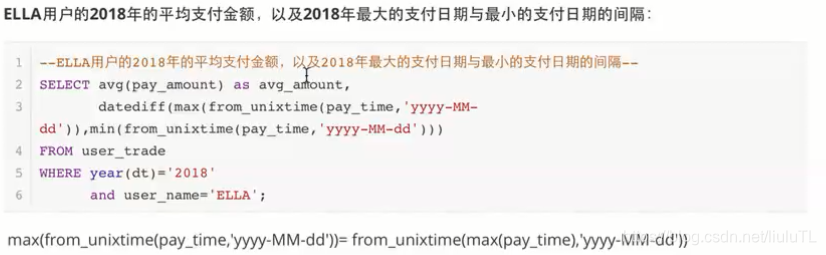
其中year(dt)='2018'也可以写成dt between '2018-01-01' and '2018-12-31'

重点练习
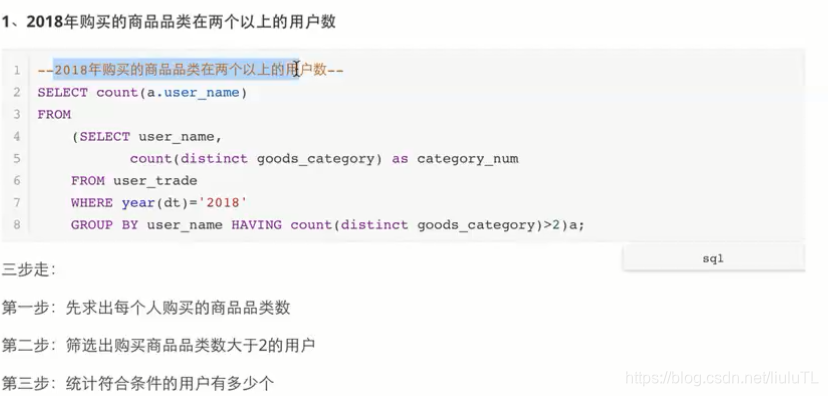
1、2018年购买的商品品类在两个以上的用户数
2、用户激活时间在2018年,年龄段在20-30岁和30-40岁的婚姻状况分布

